信息抽取(UIE)技术:让保险理赔信息处理流程便捷高效
一、引言
在当今快速发展的保险行业中,风险评估与定价是核心环节,它们直接关系到保险公司的盈利能力和市场竞争力。随着人工智能技术的不断进步,尤其是深度学习在图像识别和自然语言处理领域的突破,保险案件信息的自动化处理已成为可能。在理赔过程中,用户上传的理赔资料,如医疗记录、事故报告等,需要被准确解读以提取关键信息,如疾病诊断、治疗费用等,这些信息对于案件的准确理赔至关重要。然而,现有技术在处理这些数据时,往往依赖于对文本字段的置信度评估,这种方法在面对复杂的理赔资料时显得力不从心,无法全面反映整体资料的置信度。为了解决这一问题,我们引入了一种创新的保险案件信息抽取的置信度评估方法,该方法通过深度学习技术,不仅提取关键信息,还对信息抽取过程的特征进行分析,从而提高了置信度评估的准确性。这一技术的应用,有望为保险行业带来更高效、更准确的风险评估与定价解决方案。
二、用户案例
在我作为项目经理的职业生涯中,我遇到了一个特别棘手的问题。我们公司需要处理大量的保险理赔案件,这些案件涉及的资料繁杂,包括医疗报告、事故现场照片、目击者陈述等。这些资料中蕴含着大量的关键信息,比如患者的疾病诊断、治疗费用、事故责任方等,但这些信息往往分散在文本的不同部分,而且格式各异,给信息的提取和整合带来了巨大的挑战。
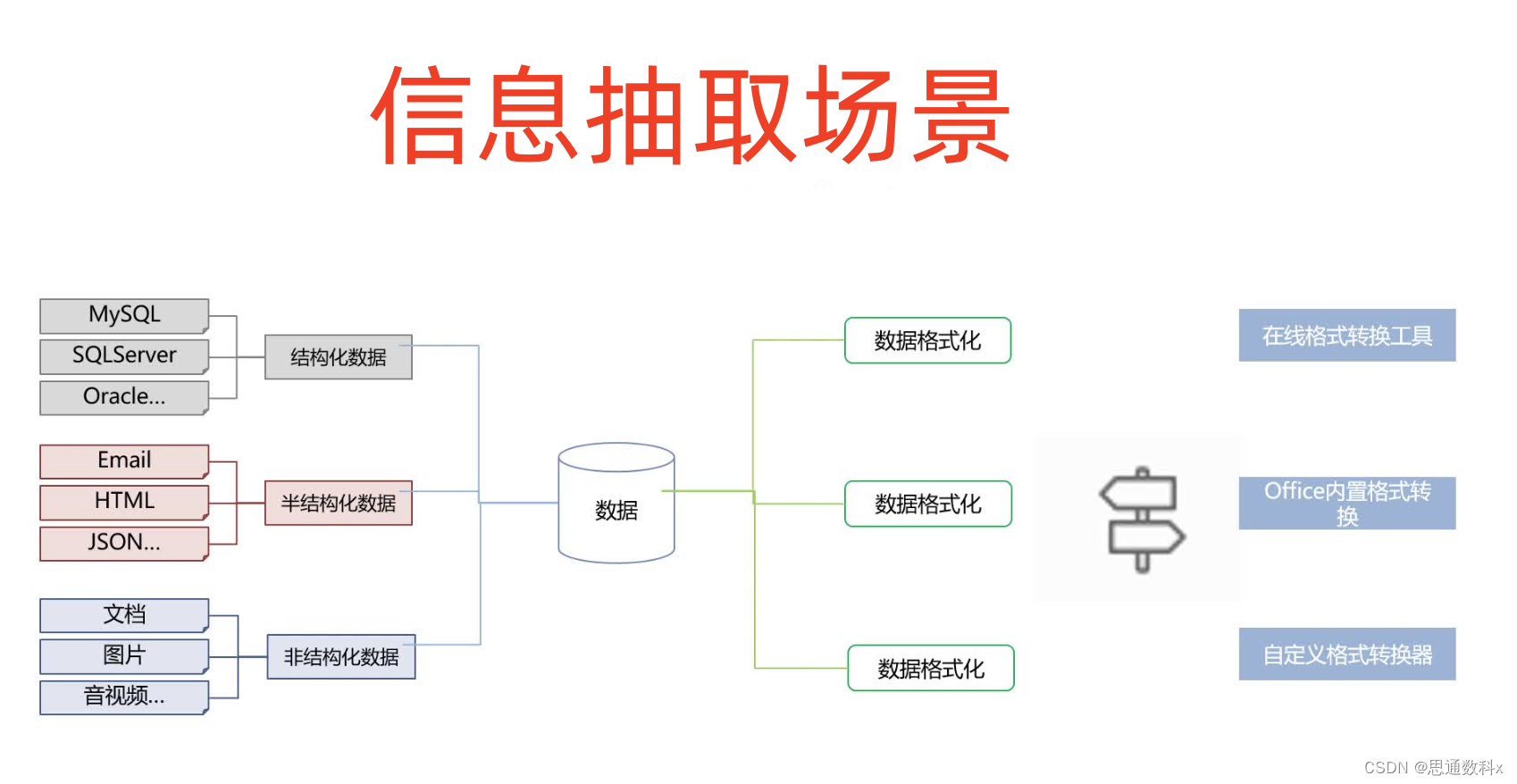
为了提高效率,我们决定采用信息抽取技术。首先,我们利用参数与属性抽取功能,自动识别文本中的数值信息,比如医疗费用的金额、事故发生的时间和地点。这大大减少了人工阅读和数据录入的工作量。例如,在一个理赔案件中,我们成功地从一份复杂的医疗报告中自动提取出了患者的治疗费用,这在以前可能需要花费数小时的人工阅读和核对。
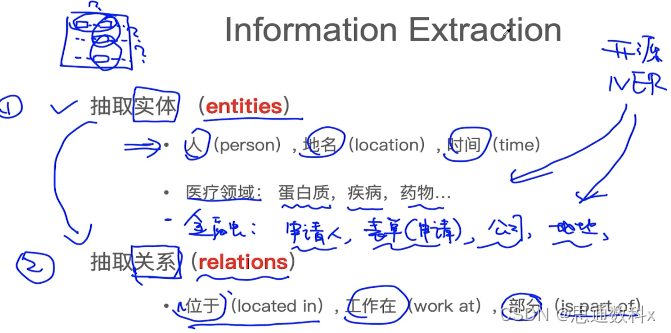
我们使用实体抽取技术来识别文本中的关键名词短语,如“心脏病”、“交通事故”等。这些实体的识别对于理解案件的性质至关重要。例如,在一个涉及交通事故的案件中,我们能够准确地识别出事故责任方和受害者,这对于确定理赔责任非常有帮助。
关系抽取技术进一步帮助我们理解了文本中实体之间的联系。例如,我们能够识别出“心脏病”是由“高血压”引起的,或者“交通事故”是由“驾驶员酒驾”导致的。这些关系信息对于案件的分析和理赔决策至关重要。
事件抽取技术让我们能够从文本中提取出完整的事件描述,包括事件的参与者、发生的时间、地点和结果。这在处理涉及复杂情况的理赔案件时尤为有用。比如,在一个涉及多车相撞的交通事故中,我们能够清晰地描绘出事故的经过,这对于确定责任和理赔金额非常关键。
通过对这些技术的应用,我们不仅提高了信息处理的效率,还提升了理赔决策的准确性。这不仅为客户带来了更好的服务体验,也为公司节省了大量的人力和时间成本。
三、技术原理
在保险行业的风险评估与定价系统中,信息抽取技术的应用至关重要。通过深度学习技术,尤其是自然语言处理(NLP)的应用,我们能够从大量的非结构化文本数据中提取出有价值的信息,从而为风险评估和定价提供准确的数据支持。
在实际应用中,我们首先利用预训练的语言模型,如BERT或GPT,来理解理赔资料中的深层语言结构和语义。这些模型在大规模文本数据上进行预训练,能够捕捉到语言的细微差别,为后续的信息抽取任务打下坚实的基础。
我们会对这些预训练模型进行任务特定的微调。在保险行业的特定场景下,这可能包括对医疗术语的识别、事故责任的判定以及费用明细的解析等。微调过程中,模型会在标注好的保险理赔数据上进行进一步训练,以适应保险行业的特定需求。
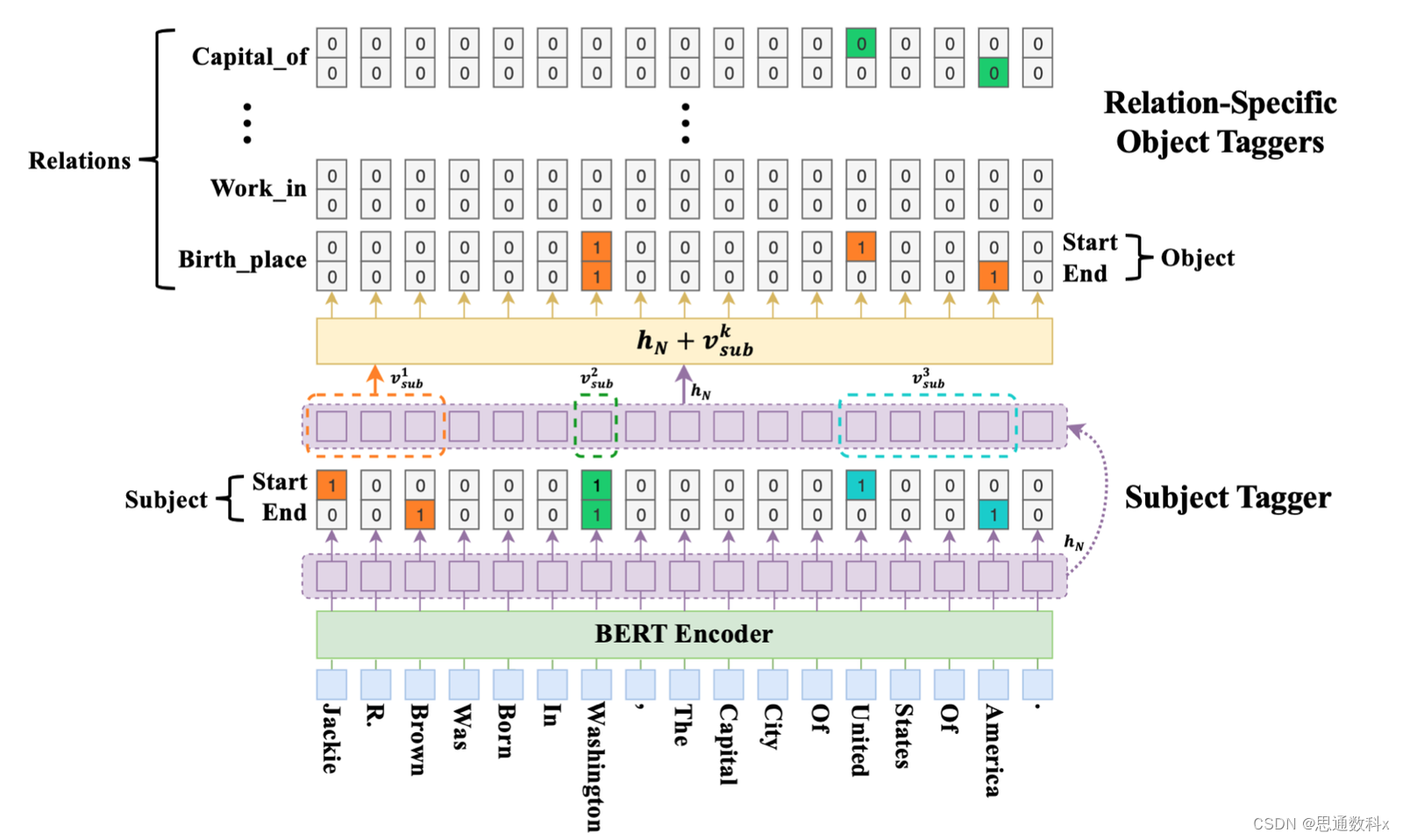
在实体识别(NER)方面,我们使用序列标注技术来识别文本中的关键实体,如疾病名称、药物名称、费用金额等。这些实体的准确识别对于理解理赔案件的细节至关重要。例如,通过识别医疗报告中的疾病名称和治疗费用,我们可以更准确地评估理赔金额。
关系抽取技术则帮助我们理解实体之间的联系。在保险理赔中,这可能涉及到识别疾病与治疗费用之间的关系,或者事故责任方与受害者之间的关系。这些关系信息对于确定理赔责任和金额至关重要。
在模型评估与优化方面,我们通过准确率、召回率、F1分数等指标来评估模型的性能,并根据评估结果对模型进行调整。这包括调整学习率、优化网络结构或增加训练数据,以确保信息抽取的准确性和可靠性。
总的来说,通过深度学习和自然语言处理技术的应用,我们的保险风险评估与定价系统能够更准确地处理理赔资料,为保险公司提供强有力的数据支持,从而提高理赔效率和客户满意度。
四、NLP平台应用
为了实现上述技术原理,我们选择了一个成熟的NLP平台,它提供了一整套的自然语言处理工具,使我们能够无需从头开始编写代码,就能快速部署和应用深度学习模型。
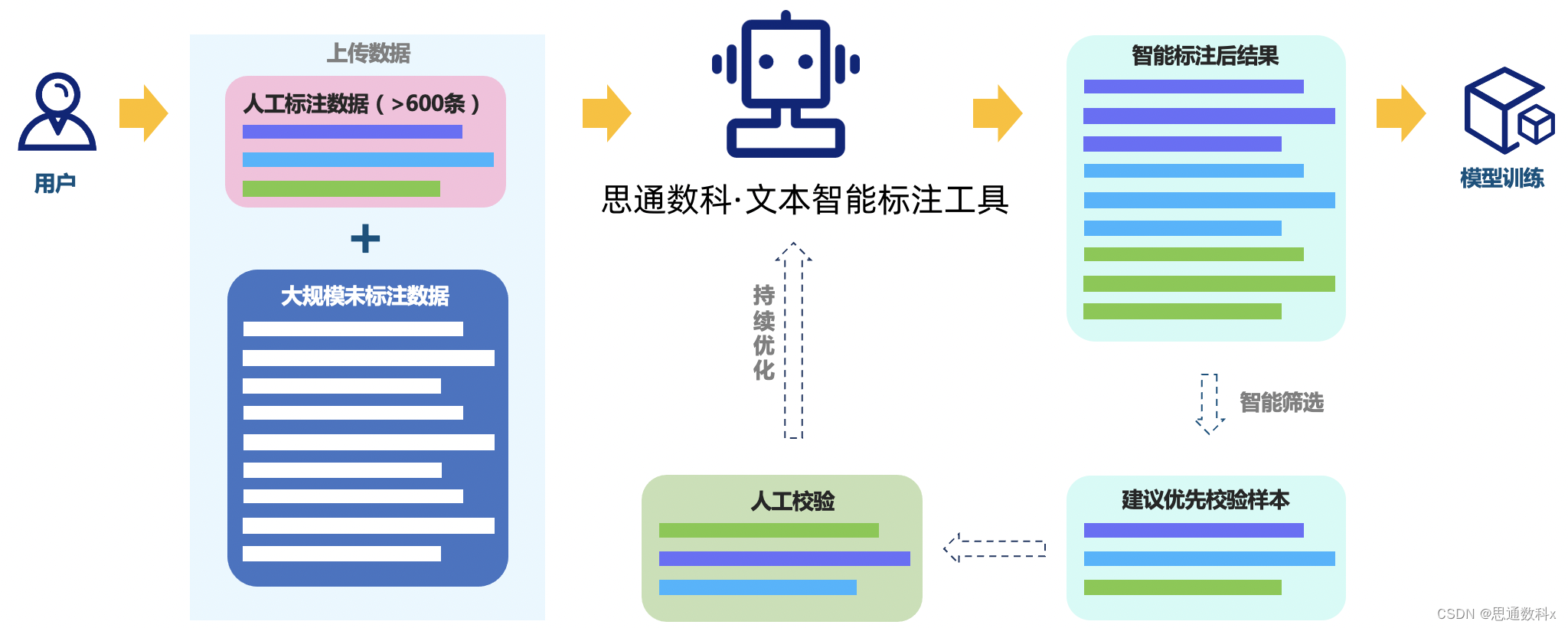
以下是我们如何使用这个平台的具体步骤:
数据收集:我们首先从历史理赔案件中收集了200条数据样本,这些样本涵盖了各种类型的保险理赔情况,确保了数据的多样性和全面性。
数据清洗:通过平台提供的数据预处理工具,我们去除了无关信息,纠正了拼写错误,并标准化了术语,以提高数据质量。
样本标注:利用平台的在线标注工具,我们对数据进行了细致的标注,包括实体、关系和事件的识别。为了确保标注质量,我们进行了多轮的标注和校对。
样本训练:在标注完成后,我们使用平台的模型训练功能,提取了文本特征,并训练了多个模型。通过调整参数,我们优化了模型的性能。
模型评估:我们选择了精确度、召回率和F1分数等评估指标,通过交叉验证等方法,确保了模型的泛化能力。根据评估结果,我们对模型进行了多次迭代,以达到最佳性能。
结果预测:训练好的模型被部署到生产环境中,用于对新的理赔资料进行自动化的信息抽取。平台的web界面使得整个流程操作简便,无需编程知识。
通过这个NLP平台,我们不仅提高了信息处理的效率,还确保了信息抽取的准确性。这使得我们的理赔处理流程更加高效,同时也为客户提供了更加精准的服务。
Python代码示例
伪代码示例,展示如何使用NLP平台的观点抽取功能
导入必要的库
import requests
from requests.auth import HTTPBasicAuth
设置请求的URL和请求头
url = "https://nlp.stonedt.com/api/extract"
headers = {
"secret-id": "你的secret-id",
"secret-key": "你的secret-key"
}
准备请求的数据
data = {
"text": "事故描述:2024年2月15日,张伟驾驶车牌号为BJ-A1234的轿车,在北京市朝阳区某十字路口与李明驾驶的车牌号为SH-B4567的摩托车发生碰撞。事故导致张伟的车辆前保险杠受损,李明的摩托车侧翻,李明受轻伤。医疗记录:李明在事故发生后被送往北京市第一人民医院接受治疗。诊断结果为:轻微脑震荡,左臂擦伤。治疗费用总计为人民币3,500元。事故责任判定:根据交通警察的事故报告,张伟因未遵守交通信号灯指示,负主要责任。李明因超速行驶,负次要责任。理赔金额:张伟的车辆维修费用为人民币8,000元。李明的医疗费用由张伟的保险公司部分赔付,根据责任比例,张伟的保险公司需赔付李明医疗费用的70%,即人民币2,450元。理赔决定:张伟的保险公司同意赔付车辆维修费用8,000元,并按照责任比例赔付李明的医疗费用2,450元。总计赔付金额为10,450元。"
}
发送POST请求
response = requests.post(url, json=data, headers=headers)
检查请求是否成功
if response.status_code == 200:
解析返回的JSON数据
extracted_data = response.json()
print("请求返回结果:", response)
print("错误信息:", response.text)
五、项目总结
本项目显著提升了保险理赔案件处理的效率与准确性。通过引入先进的信息抽取技术,我们实现了对理赔资料的自动化处理,大幅减少了人工阅读和数据录入的需求。这一转变不仅提高了工作效率,降低了人力成本,还通过减少人为错误,增强了理赔决策的可靠性。客户体验也因此得到显著改善,理赔流程的透明度和响应速度的提升,赢得了客户的广泛认可。
通过深度学习模型的精准分析,为风险评估和定价提供了更为精确的数据支持。这不仅优化了保险公司的运营模式,还为公司在激烈的市场竞争中赢得了先机。总体而言,项目的成功实施为保险行业树立了一个新的技术标杆,展示了人工智能在提升行业效率和服务质量方面的巨大潜力。
六、开源项目(可本地化部署,永久免费)
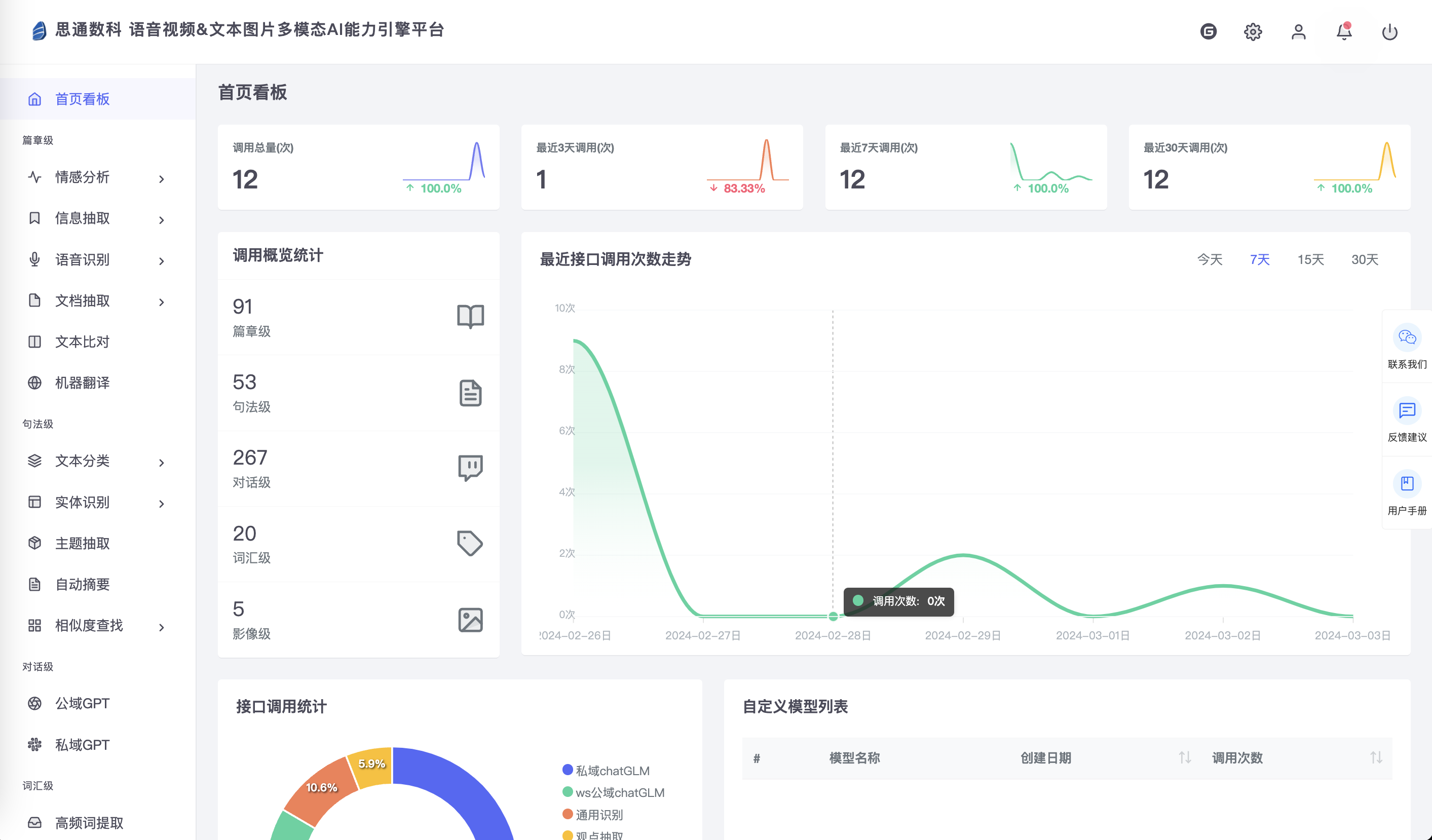
思通数科的多模态AI能力引擎平台是一个企业级解决方案,它结合了自然语言处理、图像识别和语音识别技术,帮助客户自动化处理和分析文本、音视频和图像数据。该平台支持本地化部署,提供自动结构化数据、文档比对、内容审核等功能,旨在提高效率、降低成本,并支持企业构建详细的内容画像。用户可以通过在线接口体验产品,或通过提供的教程视频和文档进行本地部署。
多模态AI能力引擎平台
https://gitee.com/stonedtx/free-nlp-api