SSAS:菜鸟笔记(一)基本思路及操作
建模思路
- 创建数据源 Data Source
- 创建数据源视图 Data Source View
- 创建数据维度 Dimenstrition
- 创建数据立方 Cube → 选定要填充的数据内容 Fact
- 向数据维度 Dimenstrition 中添加属性 Attributes,并设定属性之间的逻辑关系
- 校正/调整 Measures、Attribute、Hierarchies,包括各种关系、排序、索引、计算脚本等
名词理解
- Cube:逻辑数据库,用于存放逻辑数据表,并管理关联关系的地方
- Dimenstrition:逻辑数据表,可以依据多张具有逻辑关系的物理数据表构建
- Attribute:逻辑数据表的字段
- Fact:用于填充逻辑数据表的字段,来自逻辑数据表所关联的各物理数据表及与这些物理数据表有关联关系的指定物理数据表
- Measure
- Hierarchy:逻辑表内部的逻辑结构
- Calculation Column:编写脚本依据现有的属性生成新的属性列,在Data Source View当中创建,必须使用已经加入到DSV当中的属性,不然无法完成计算,计算表达式使用的是T-SQL语法
- Composite KeyColumn:用于呈现,并实现属性的唯一标识
性能优化
- 根据分析的实际需要,合理设置Dimenstrition的Attributes之间的逻辑关联关系
- 添加新的逻辑关系
- 修改默认逻辑关系
- “rgrid”关系类型:如果关联的两个属性之间的关系没有变化,则将会增量处理数据,而不会每次都全部重新计算
- “flexible”关系类型:无论关联的两个属性之间的关系是否变化,都会灵活的处理数据
- 合理设置Dimenstrition Attributes Hierarchy的自动索引,
- 关闭不在Hierarchy中显示的属性的索引,能够提高执行效率
- 开启不在Hierarchy中显示,但是作为键值的属性的索引,能够提高执行效率
- 合理设置Dimenstrition Attributes Hierarchy的自动排序,
- 如果不在意数据之间的顺序,关闭此项,能够提高执行效率
应用图示

Hierachy

Display Folder
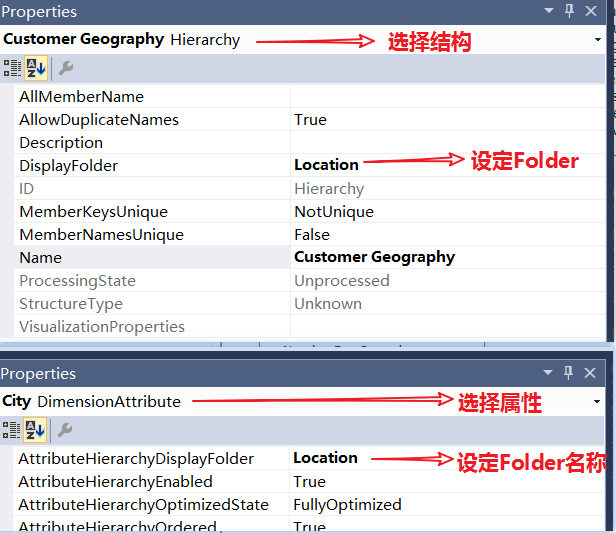
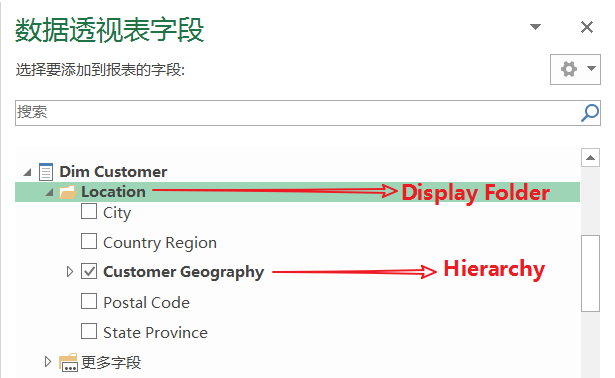
DimAttributes Relationships

Parent Attribute Properties

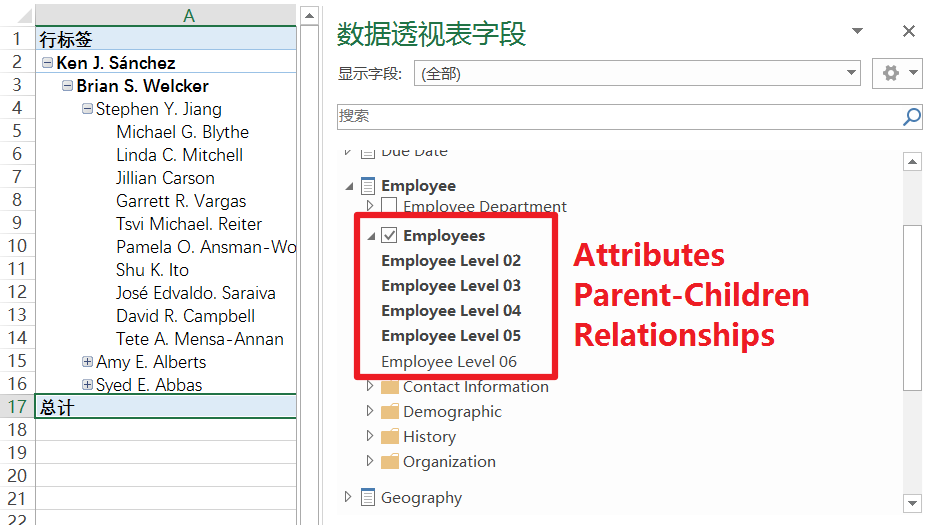
Changing the Sort Order by Modifying Composite Key Member Order
设定排序规则

Grouping Attribute Hierarchy Members
通过如下图所示的方式,可以将原始数据进行自动分组。

Hiding and Disabling Attribute Hierarchies
通过隐藏、禁用属性层次结构,能够在一定程度上提高数据的安全性、可用性。
结合对自动排序、索引的合理启禁,可以在提高执行效率。
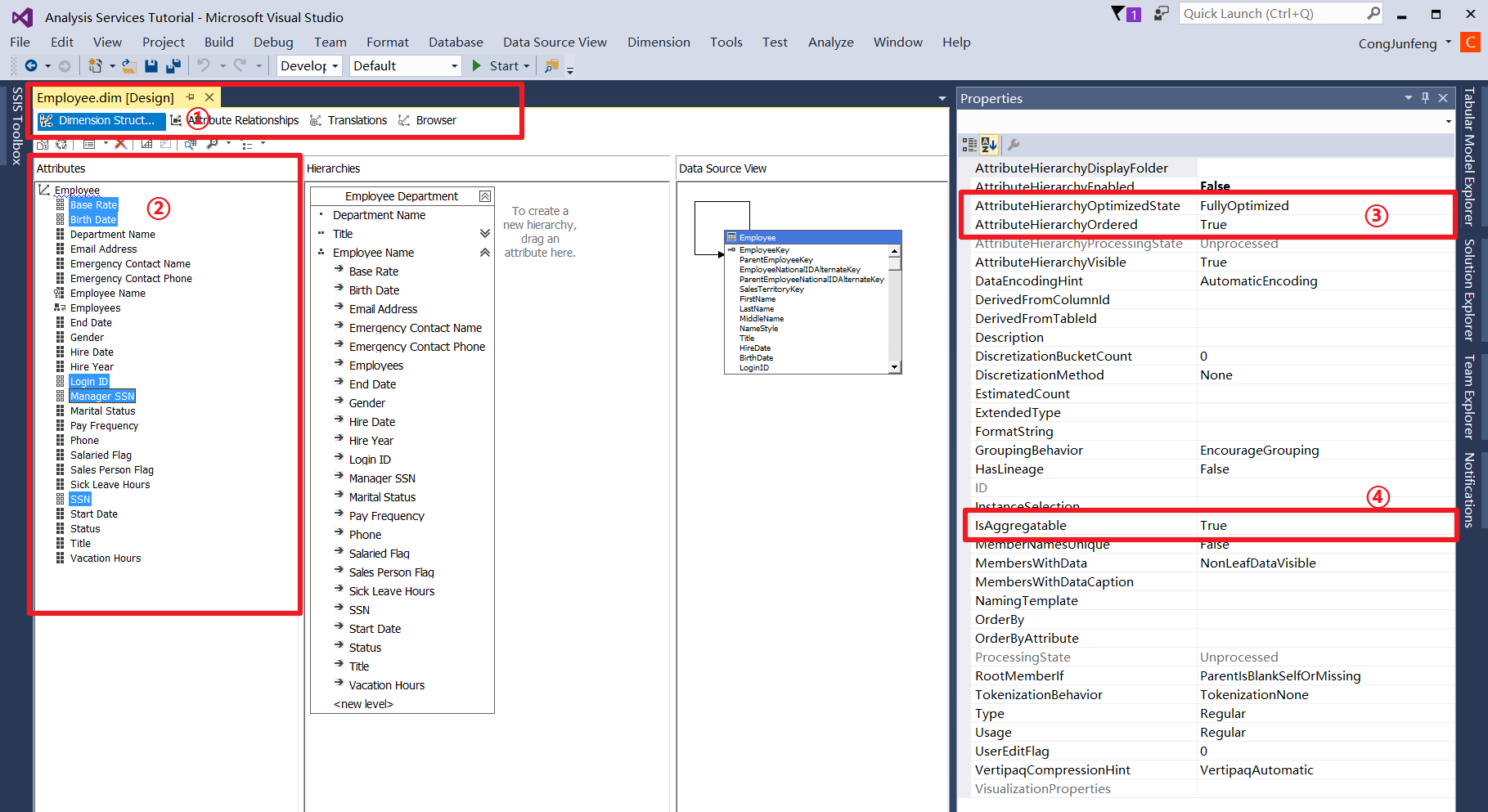
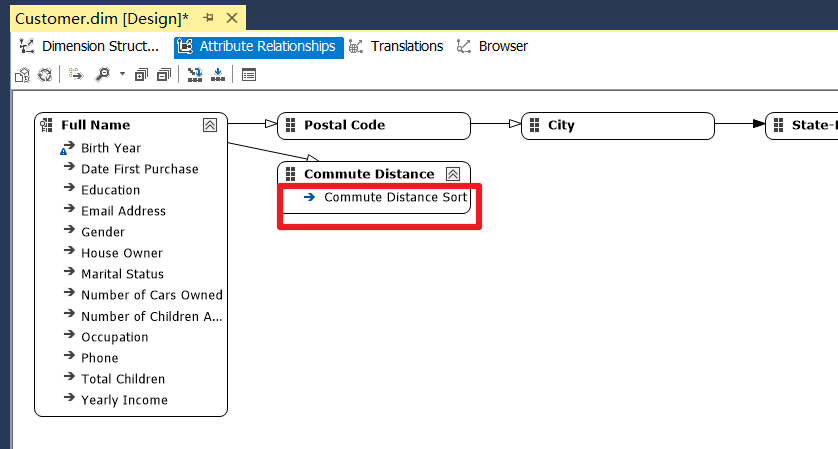
Defining an Attribute Relationship and Sort Order in Dimension
- 基于Calculation或原始属性,创建用于排序的属性
- 设定新属性在Hierarchy中的可用性、可见性、自动索引、自动排序,以优化性能
- 在 Attribute Relationships Tab 中,为要进行排序的属性创建新的关联关系到新属性
- 在 Dimetion Structure Tab 中,为要进行排序的属性设定“OrderBy:AttributeKey”、“OrderByAttribute:[刚刚关联的属性]”

版权声明:
作者:莫不逢
出处:http://www.cnblogs.com/sitemanager/
Github:https://github.com/congjf
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号