
Apache Spark简单介绍、安装及使用
Apache Spark简介
Apache Spark是一个高速的通用型计算引擎,用来实现分布式的大规模数据的处理任务。
分布式的处理方式可以使以前单台计算机面对大规模数据时处理不了的情况成为可能。
Apache Spark安装及配置(OS X下的Ubuntu虚拟机)
学习新东西最好是在虚拟机下操作,以免对现在的开发环境造成影响,我的系统是OS X,安装的是VirtualBox虚拟机,然后在虚拟机里安装的Ubuntu系统。
VirtualBox安装方法请查看教程:
注意在安装过程中设置4GB的RAM和20GB的空间,否则会出现不够用的情况。
安装 Anaconda
Anaconda 是Python科学计算包的合集,在接下来的例子中,会用到其中的matplotlib用来生成一张柱状图。
然后在Terminal中输入命令:
bash Anaconda2-4.1.1-Linux-x86_64.sh
安装 Java SDK
Spark运行在JVM上,所以还需要安装Java SDK:
$ sudo apt-get install software-properties-common $ sudo add-apt-repository ppa:webupd8team/java $ sudo apt-get update $ sudo apt-get install oracle-java8-installer
设置JAVA_HOME
打开.bashrc文件
gedit .bashrc
在.bashrc中添加如下设置:
JAVA_HOME=/usr/lib/jvm/java-8-oracle export JAVA_HOME PATH=$PATH:$JAVA_HOME export PATH
安装Spark
去官网下载压缩包,下载地址 http://spark.apache.org/downloads.html
将安装包解压,命令如下:
$ tar -zxvf spark-2.0.0-bin-hadoop2.7.tgz
$ rm spark-2.0.0-bin-hadoop2.7.tgz
启用IPython Notebook
打开.bashrc文件
gedit .bashrc
在.bashrc中添加如下设置:
export PYSPARK_DRIVER_PYTHON=ipython
export PYSPARK_DRIVER_PYTHON_OPTS=notebook
检查是否安装成功 (需重启Terminal)
cd ~/spark-2.0.0-bin-hadoop2.7
./bin/pyspark
Apache Spark简单使用
打开Spark服务后,点击new - Notebooks - Python新建一个Notebook文件。
在这个小例子中,我们读取Spark文件夹下的NOTICE文件里的内容,然后统计词频,最后生成一张图表。示例很简单,直接贴出代码截图和最后的结果:
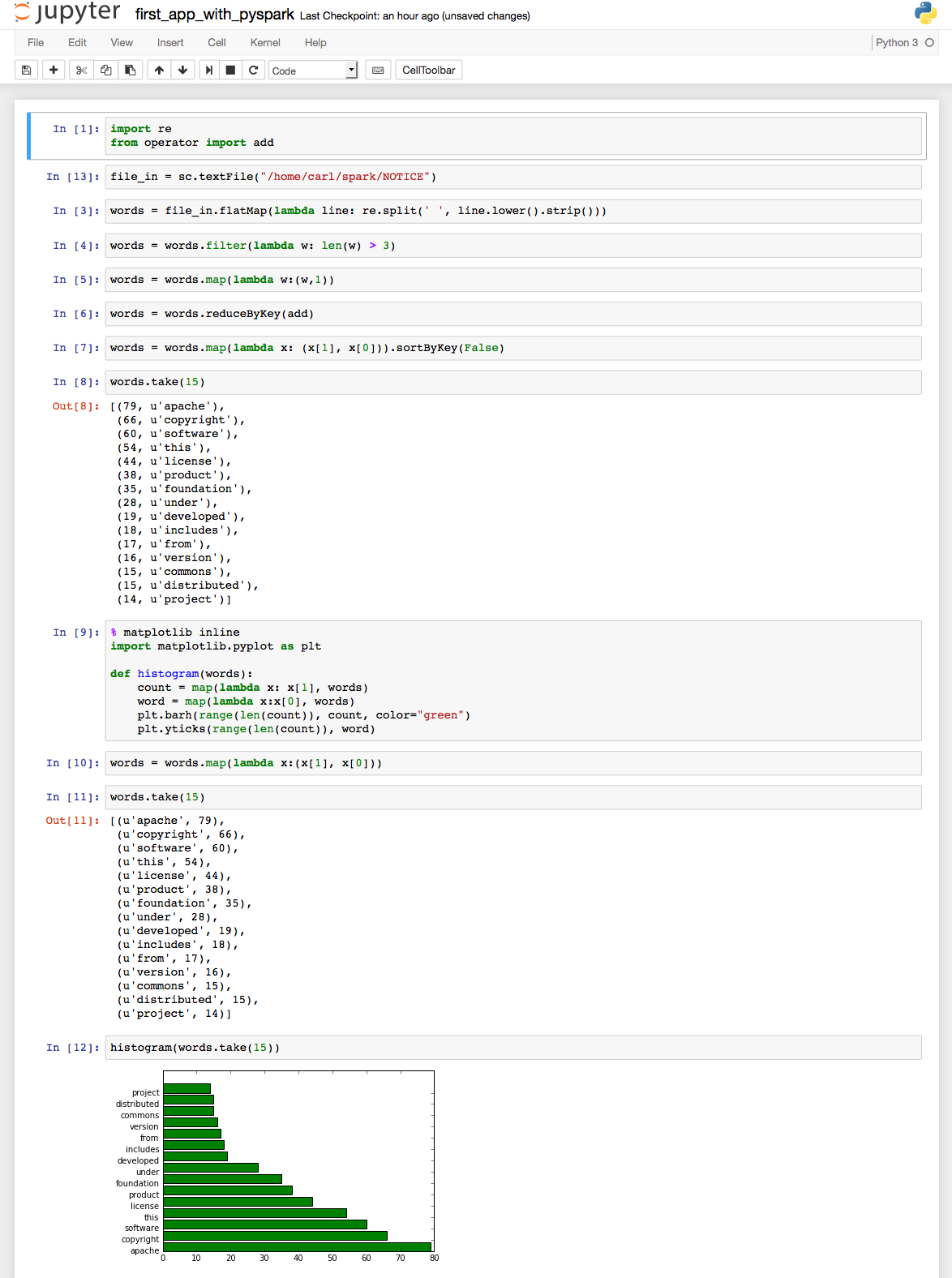
源代码:

 View Code
View Code


# coding: utf-8 # In[1]: import re from operator import add # In[13]: file_in = sc.textFile("/home/carl/spark/NOTICE") # In[3]: words = file_in.flatMap(lambda line: re.split(' ', line.lower().strip())) # In[4]: words = words.filter(lambda w: len(w) > 3) # In[5]: words = words.map(lambda w:(w,1)) # In[6]: words = words.reduceByKey(add) # In[7]: words = words.map(lambda x: (x[1], x[0])).sortByKey(False) # In[8]: words.take(15) # In[9]: get_ipython().magic(u'matplotlib inline') import matplotlib.pyplot as plt def histogram(words): count = map(lambda x: x[1], words) word = map(lambda x:x[0], words) plt.barh(range(len(count)), count, color="green") plt.yticks(range(len(count)), word) # In[10]: words = words.map(lambda x:(x[1], x[0])) # In[11]: words.take(15) # In[12]: histogram(words.take(15))
这些内容是在学习 Spark for Python Developers 这本书过程中的随笔,接下来还会继续分享和Spark相关的知识,有兴趣的朋友欢迎关注本博客,也欢迎大家留言进行讨论。
福利:Spark for Python Developers电子版下载链接:Spark for Python Developers.pdf
我们处于大数据时代,对数据处理感兴趣的朋友欢迎查看另一个系列随笔: 利用Python进行数据分析 基础系列随笔汇总
如果你对网络爬虫感兴趣,请查看另一篇随笔: 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
如果你对网络爬虫感兴趣,请查看另一篇随笔: 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
作者:backslash112 (美国CS研究生在读/机器人工程师)
出处:http://sirkevin.cnblogs.com
GitHub:https://github.com/backslash112
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
出处:http://sirkevin.cnblogs.com
GitHub:https://github.com/backslash112
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

posted on 2016-09-08 16:23 backslash112 阅读(8516) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架