网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
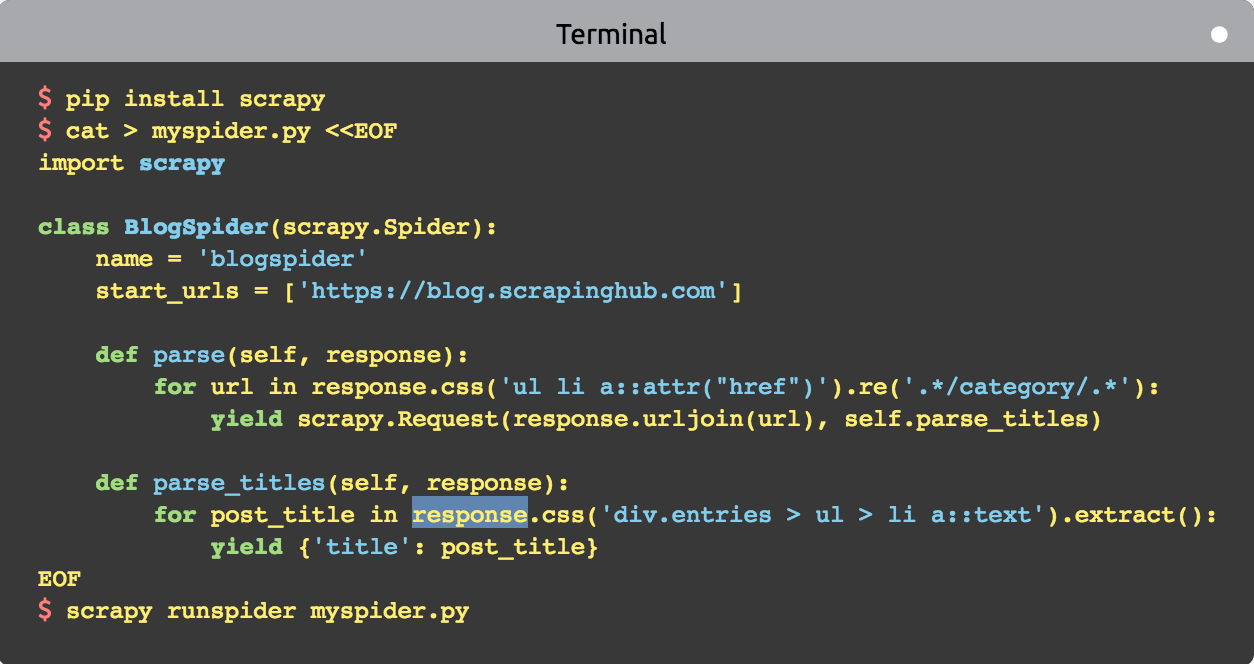
- 当执行scrapy runspider xxx.py命令的时候, Scrapy在项目里查找Spider(蜘蛛🕷️)并通过爬虫引擎来执行它。
- 首先从定义在start_urls里的URL开始发起请求,然后通过parse()方法处理响应。response参数就是返回的响应对象。
- 在parse()方法中,通过一个CSS选择器获取想要抓取的数据。
pip install scrapy
scrapy startproject book_project
import scrapy class BookItem(scrapy.Item): title = scrapy.Field() isbn = scrapy.Field() price = scrapy.Field()
import scrapy from book_project.items import BookItem class BookInfoSpider(scrapy.Spider): name = "bookinfo" allowed_domains = ["allitebooks.com", "amazon.com"] start_urls = [ "http://www.allitebooks.com/security/", ]
def parse(self, response): num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first()) base_url = "http://www.allitebooks.com/security/page/{0}/" for page in range(1, num_pages): yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page)
'//a'的意思所有的a标签;
'//a[contains(@title, "Last Page →")' 的意思是在所有的a标签中,title属性包涵"Last Page →"的a标签;
extract() 方法解析并返回符合条件的节点数据。
def parse_page(self, response): for sel in response.xpath('//div/article'): book_detail_url = sel.xpath('div/header/h2/a/@href').extract_first() yield scrapy.Request(book_detail_url, callback=self.parse_book_info) def parse_book_info(self, response): title = response.css('.single-title').xpath('text()').extract_first() isbn = response.xpath('//dd[2]/text()').extract_first() item = BookItem() item['title'] = title item['isbn'] = isbn amazon_search_url = 'https://www.amazon.com/s/ref=nb_sb_noss?url=search-alias%3Daps&field-keywords=' + isbn yield scrapy.Request(amazon_search_url, callback=self.parse_price, meta={ 'item': item })
def parse_price(self, response): item = response.meta['item'] item['price'] = response.xpath('//span/text()').re(r'\$[0-9]+\.[0-9]{2}?')[0] yield item
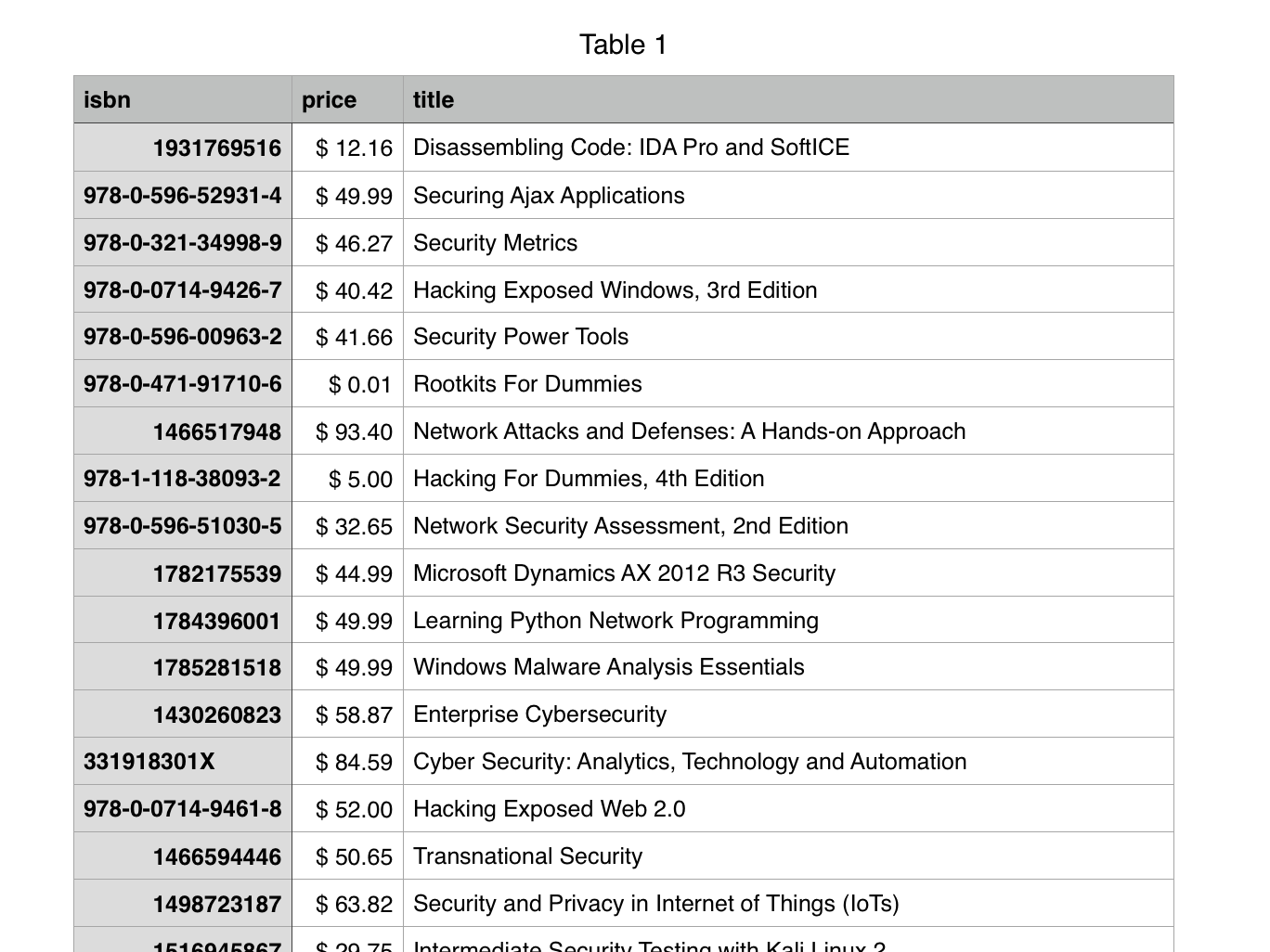
scrapy crawl bookinfo -o books.csv
大数据,大数据分析、BeautifulSoup,Beautiful Soup入门,Scrapy, Scrapy爬虫,数据挖掘,数据分析,数据处理,pandas,网络爬虫,web scraper,python excel,python写入excel数据,python处理csv文件 Scrapy csv, python操作Excel,excel读写 Scrapy框架 Scrapy框架入门大数据,大数据分析、BeautifulSoup,Beautiful Soup入门,Scrapy, Scrapy爬虫,数据挖掘,数据分析,数据处理,pandas,网络爬虫,web scraper,python excel,python写入excel数据,python处理csv文件 Scrapy csv, python操作Excel,excel读写 Scrapy框架 Scrapy框架入门 大数据,大数据分析、BeautifulSoup,Beautiful Soup入门,Scrapy, Scrapy爬虫,数据挖掘,数据分析,数据处理,pandas,网络爬虫,web scraper,python excel,python写入excel数据,python处理csv文件 Scrapy csv, python操作Excel,excel读写 Scrapy框架 Scrapy框架入门 大数据,大数据分析、BeautifulSoup,Beautiful Soup入门,Scrapy, Scrapy爬虫,数据挖掘,数据分析,数据处理,pandas,网络爬虫,web scraper,python excel,python写入excel数据,python处理csv文件 Scrapy csv, python操作Excel,excel读写 Scrapy框架 Scrapy框架入门 大数据,大数据分析、BeautifulSoup,Beautiful Soup入门,Scrapy, Scrapy爬虫,数据挖掘,数据分析,数据处理,pandas,网络爬虫,web scraper,python excel,python写入excel数据,python处理csv文件 Scrapy csv, python操作Excel,excel读写 Scrapy框架 Scrapy框架入门
出处:http://sirkevin.cnblogs.com
GitHub:https://github.com/backslash112
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
posted on 2016-08-25 10:35 backslash112 阅读(13013) 评论(8) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号