
网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码
这一篇首先从allitebooks.com里抓取书籍列表的书籍信息和每本书对应的ISBN码。
一、分析需求和网站结构
allitebooks.com这个网站的结构很简单,分页+书籍列表+书籍详情页。
要想得到书籍的详细信息和ISBN码,我们需要遍历所有的页码,进入到书籍列表,然后从书籍列表进入到每本书的详情页里,这样就能够抓取详情信息和ISBN码了。
二、从分页里遍历每一页书籍列表
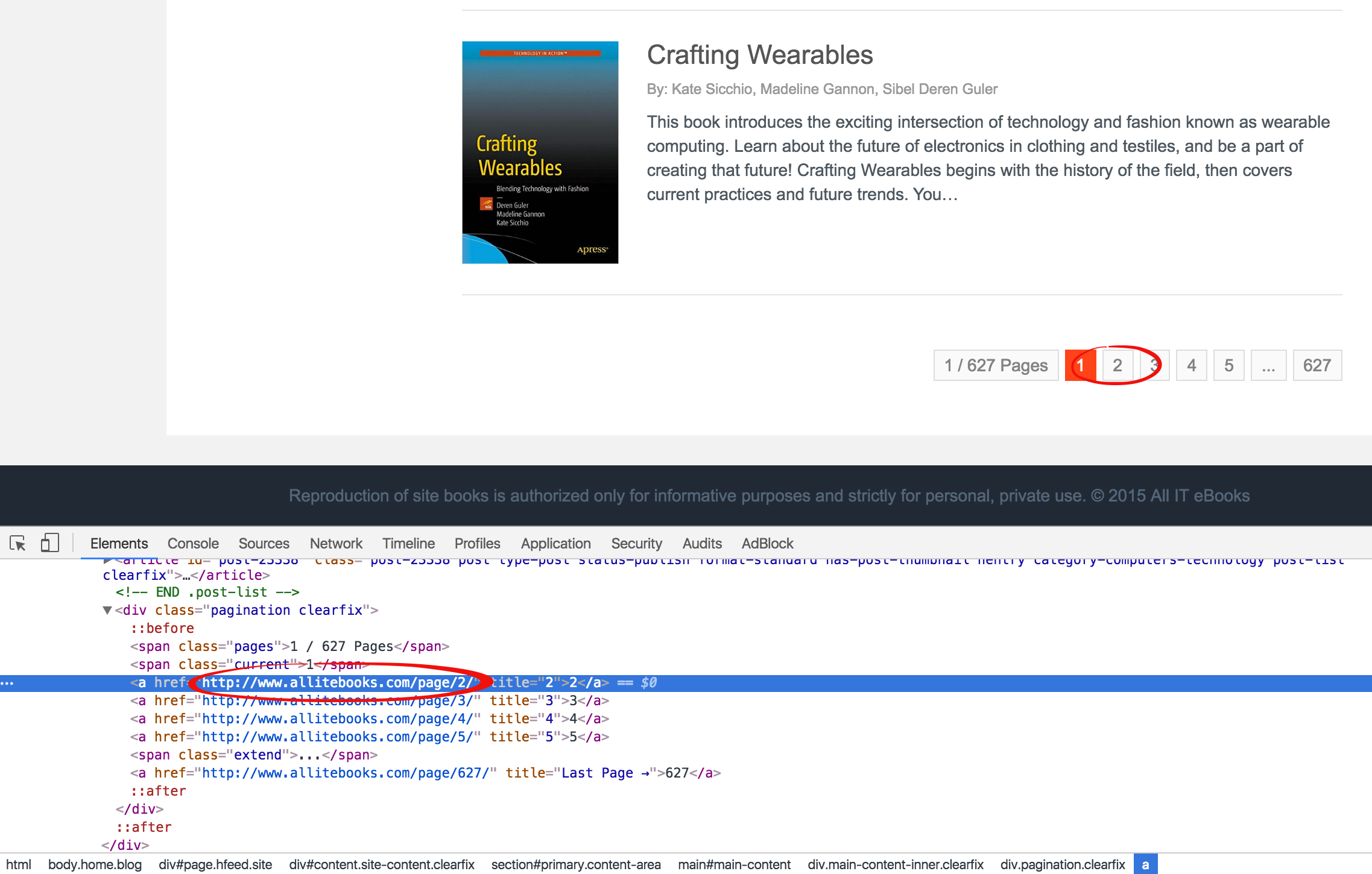
通过查看分页功能的HTML代码,通过class="current"可以定位当前页码所在span标签,此span标签的下一个兄弟a标签就是下一页链接所在的标签,
而通过对比最后一页的span可以发现,在最后一页中,通过class="current"找到的span标签却没有下一个兄弟a标签。所以我们可以通过这一点判断出是否已经到最后一页了。代码如下:

# Get the next page url from the current page url def get_next_page_url(url): page = urlopen(url) soup_page = BeautifulSoup(page, 'lxml') page.close() # Get current page and next page tag current_page_tag = soup_page.find(class_="current") next_page_tag = current_page_tag.find_next_sibling() # Check if the current page is the last one if next_page_tag is None: next_page_url = None else: next_page_url = next_page_tag['href'] return next_page_url
三、从书籍列表里找到详情页的链接
在书籍列表点击书名或者封面图都可以进入详情,则书名和封面图任选一个,这里选择书名。
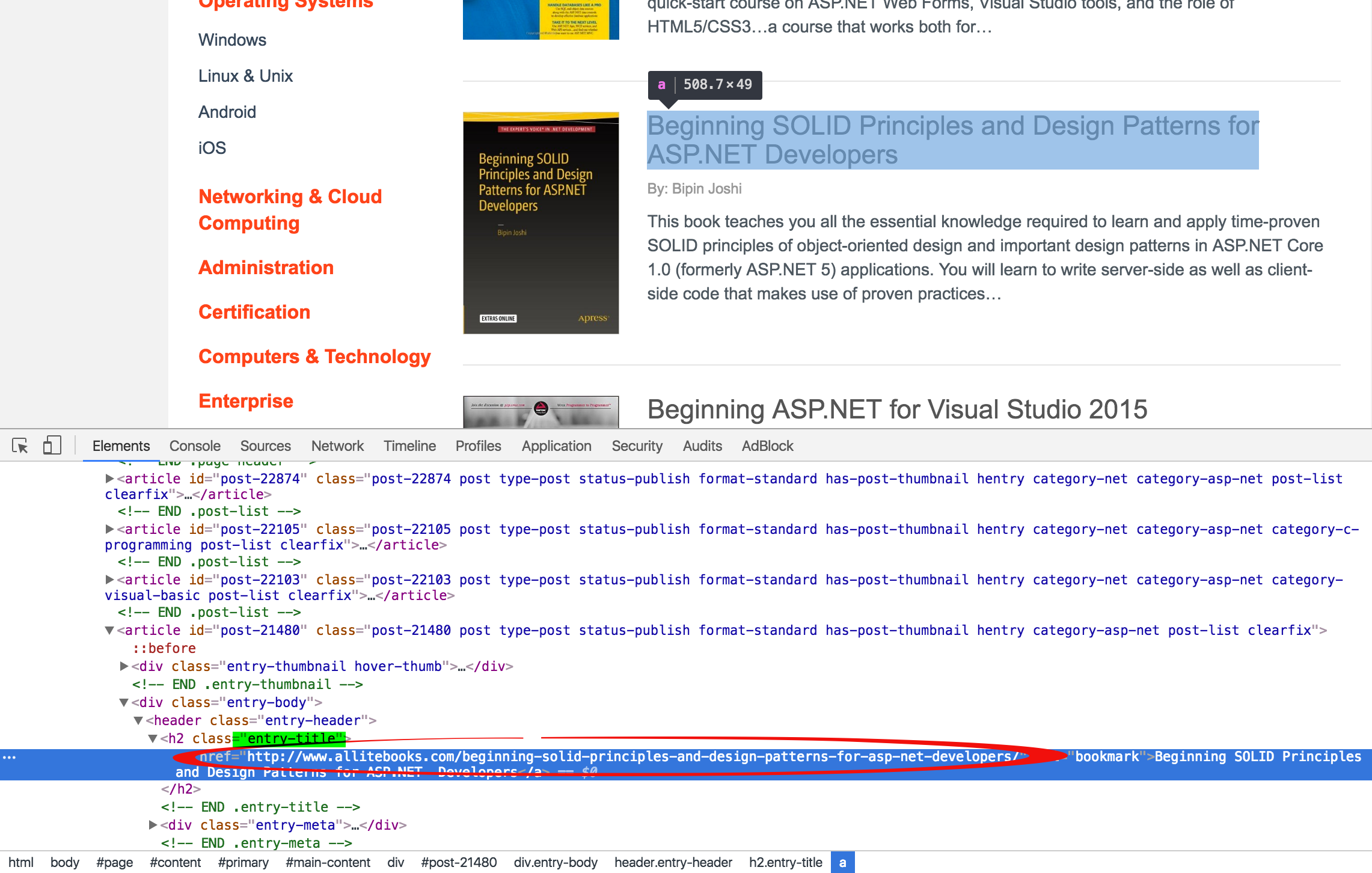
我们可以通过查找class="entry-title"定位到书名所在的h2标签,然后通过此标签的a属性即可获得链接所在的a标签,再通过a标签的string属性可得到链接。
代码如下:
# Get the book detail urls by page url def get_book_detail_urls(url): page = urlopen(url) soup = BeautifulSoup(page, 'lxml') page.close() urls = [] book_header_tags = soup.find_all(class_="entry-title") for book_header_tag in book_header_tags: urls.append(book_header_tag.a['href']) return urls
四、从书籍详情页里抓取标题和ISBN码
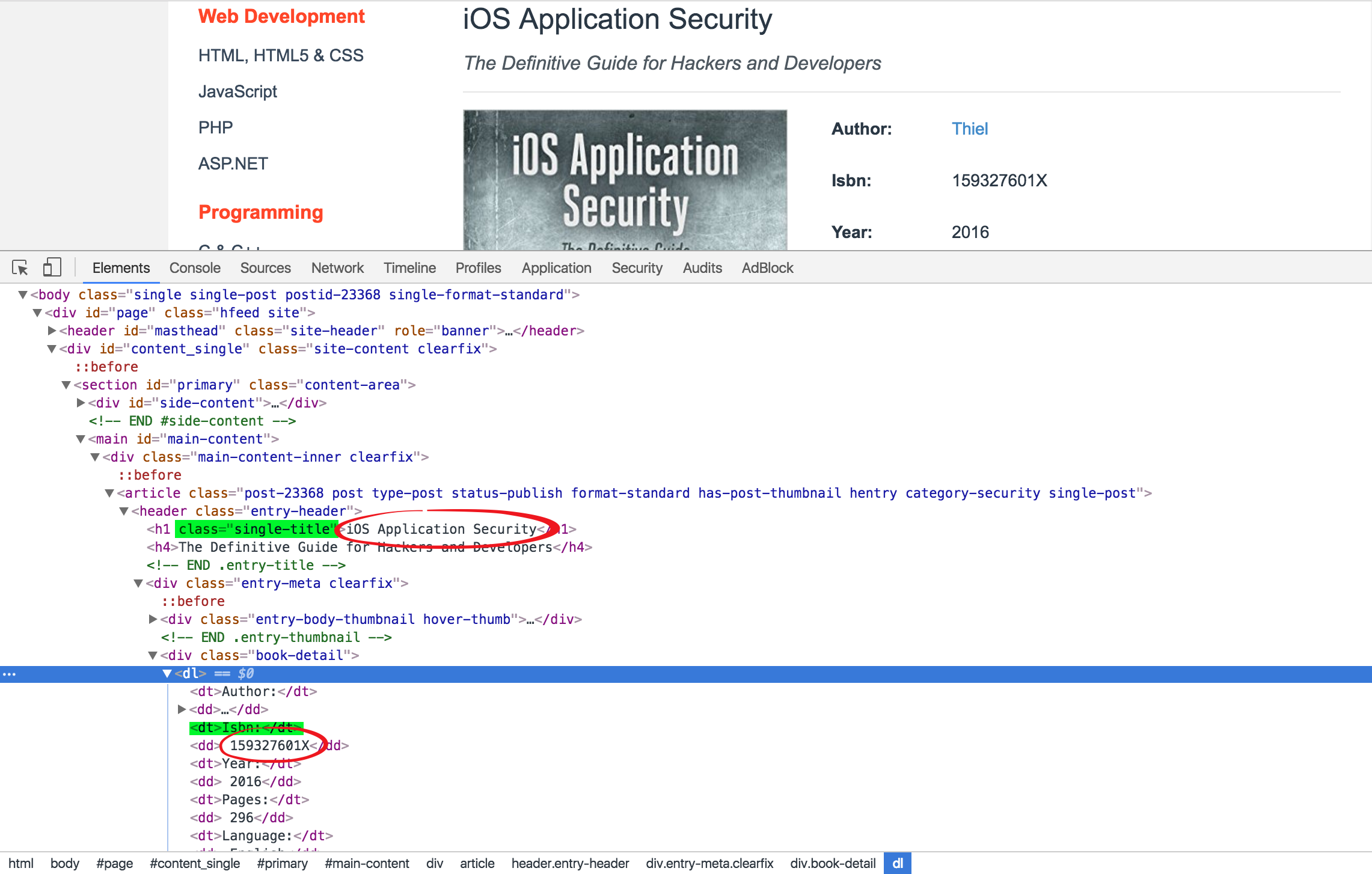
通过查看书籍详情页的HTML代码,我们可以通过查找class="single-title"定位到标题所在的h1标签获得标题,然后通过查找text="Isbn:"定位到"Isbn:"的所在的dt标签,此标签的下一个兄弟节点就是书籍ISBN码所在的标签,通过此标签的string属性可获得ISBN码内容。
代码如下:
# Get the book detail info by book detail url def get_book_detail_info(url): page = urlopen(url) book_detail_soup = BeautifulSoup(page, 'lxml') page.close() title_tag = book_detail_soup.find(class_="single-title") title = title_tag.string isbn_key_tag = book_detail_soup.find(text="Isbn:").parent isbn_tag = isbn_key_tag.find_next_sibling() isbn = isbn_tag.string.strip() # Remove the whitespace with the strip method return { 'title': title, 'isbn': isbn }
五、将三部分代码整合起来
def run(): url = "http://www.allitebooks.com/programming/net/page/1/" book_info_list = [] def scapping(page_url): book_detail_urls = get_book_detail_urls(page_url) for book_detail_url in book_detail_urls: # print(book_detail_url) book_info = get_book_detail_info(book_detail_url) print(book_info) book_info_list.append(book_info) next_page_url = get_next_page_url(page_url) if next_page_url is not None: scapping(next_page_url) else: return scapping(url)
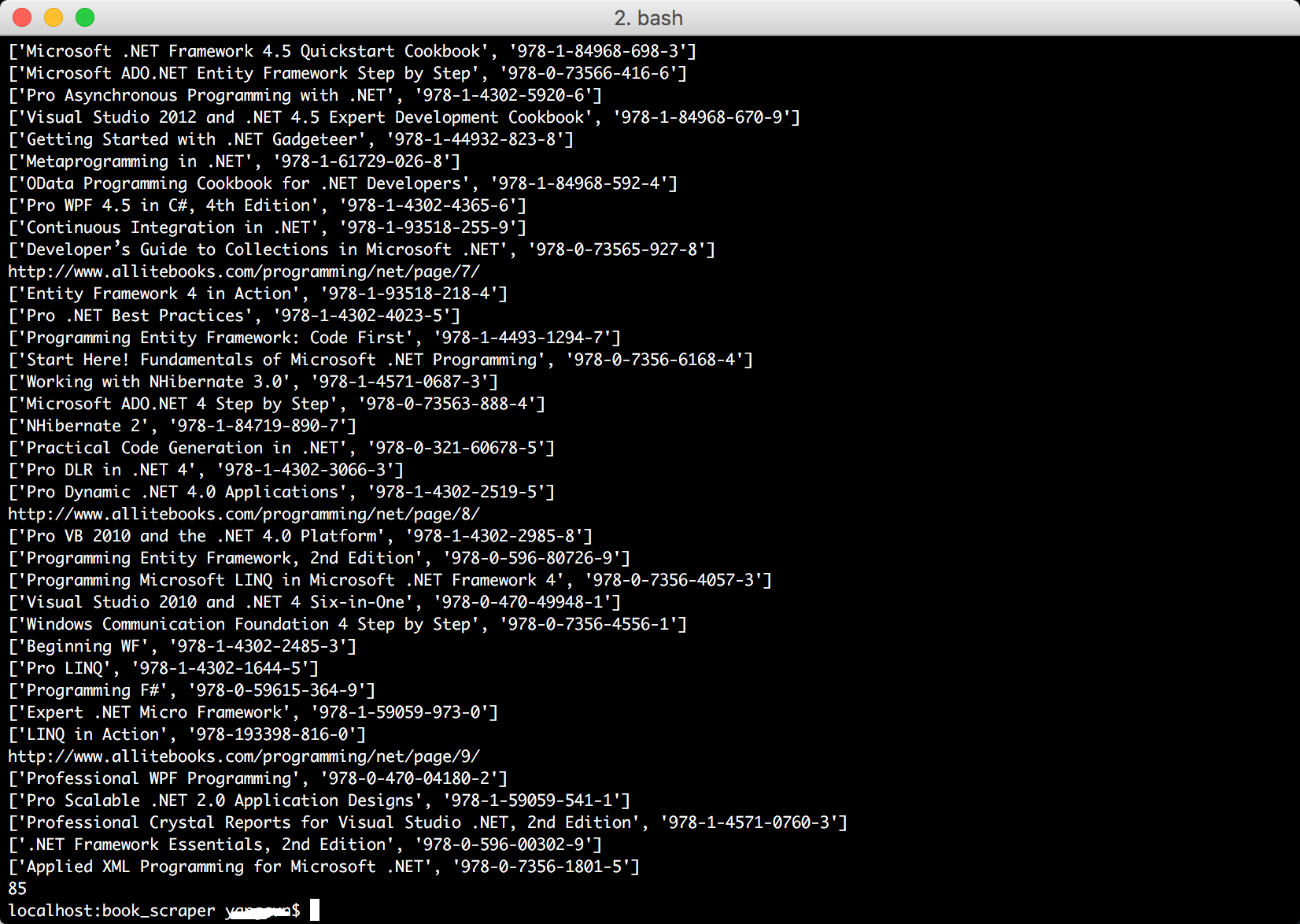
运行结果
六、将结果写入文件,以供下一步处理使用
def save_to_csv(list): with open('books.csv', 'w', newline='') as fp: a = csv.writer(fp, delimiter=',') a.writerow(['title','isbn']) a.writerows(list)
未完待续...
完整代码请移步github:https://github.com/backslash112/book_scraper_python
Beautiful Soup基础知识:网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
我们处于大数据时代,对数据处理感兴趣的朋友欢迎查看另一个系列随笔:利用Python进行数据分析 基础系列随笔汇总
接下来一篇随笔是根据获取到的ISBN码去amazon.com网站获取每本书对应的价格,并通过数据分析的知识对获取的数据进行处理,最后输出到csv文件。有兴趣的朋友欢迎关注本博客,也欢迎大家留言讨论。
作者:backslash112 (美国CS研究生在读/机器人工程师)
出处:http://sirkevin.cnblogs.com
GitHub:https://github.com/backslash112
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
出处:http://sirkevin.cnblogs.com
GitHub:https://github.com/backslash112
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

posted on 2016-08-18 21:38 backslash112 阅读(2148) 评论(3) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架