
利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一、reindex() 方法:重新索引
针对 Series
重新索引指的是根据index参数重新进行排序。
如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行。
不想用缺失值,可以用 fill_value 参数指定填充值。
例如:

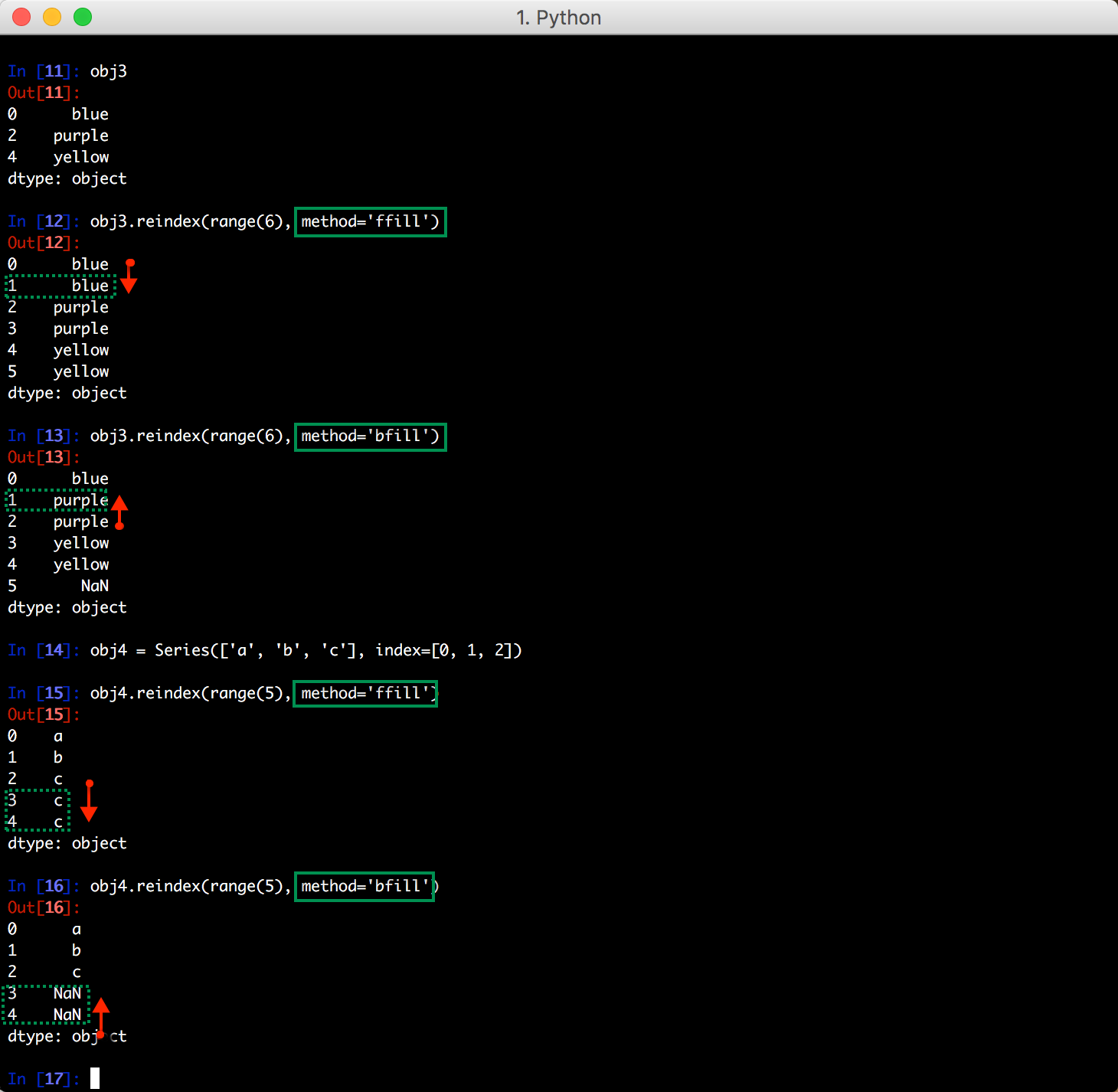
fill_value 会让所有的缺失值都填充为同一个值,如果不想这样而是用相邻的元素(左或者右)的值填充,则可以用 method 参数,可选的参数值为 ffill 和 bfill,分别为用前值填充和用后值填充:
针对 DataFrame
重新索引操作:

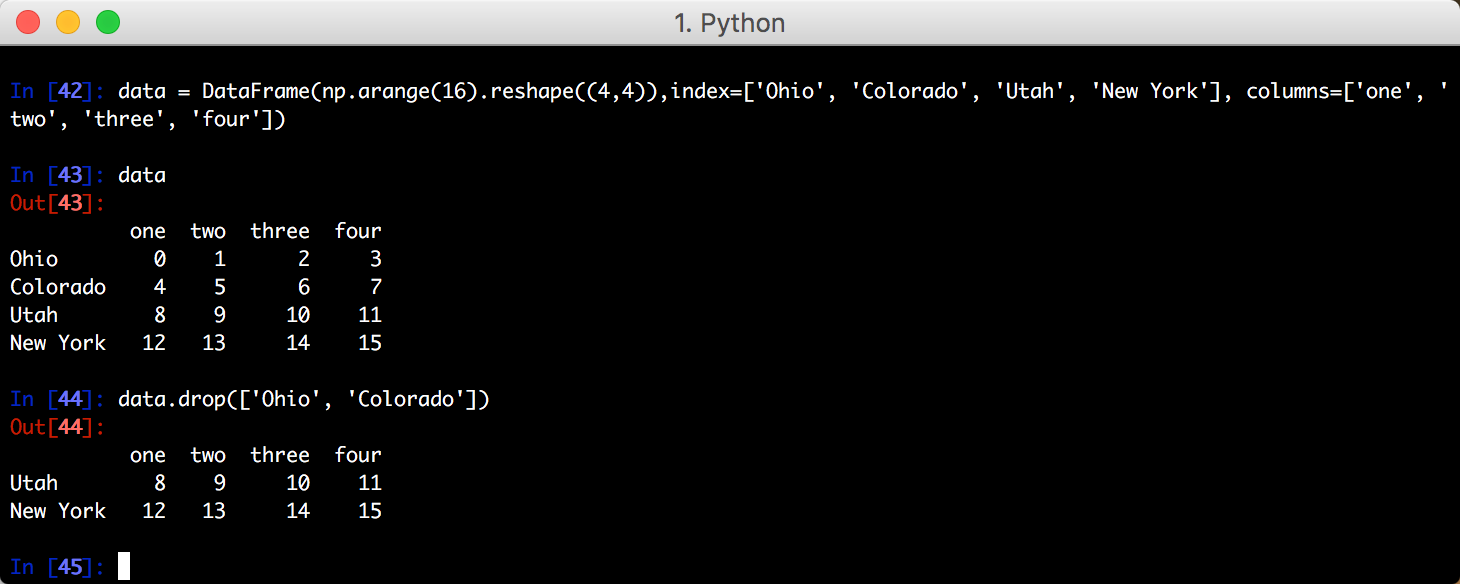
二、drop() 方法:丢弃数据
针对 Series
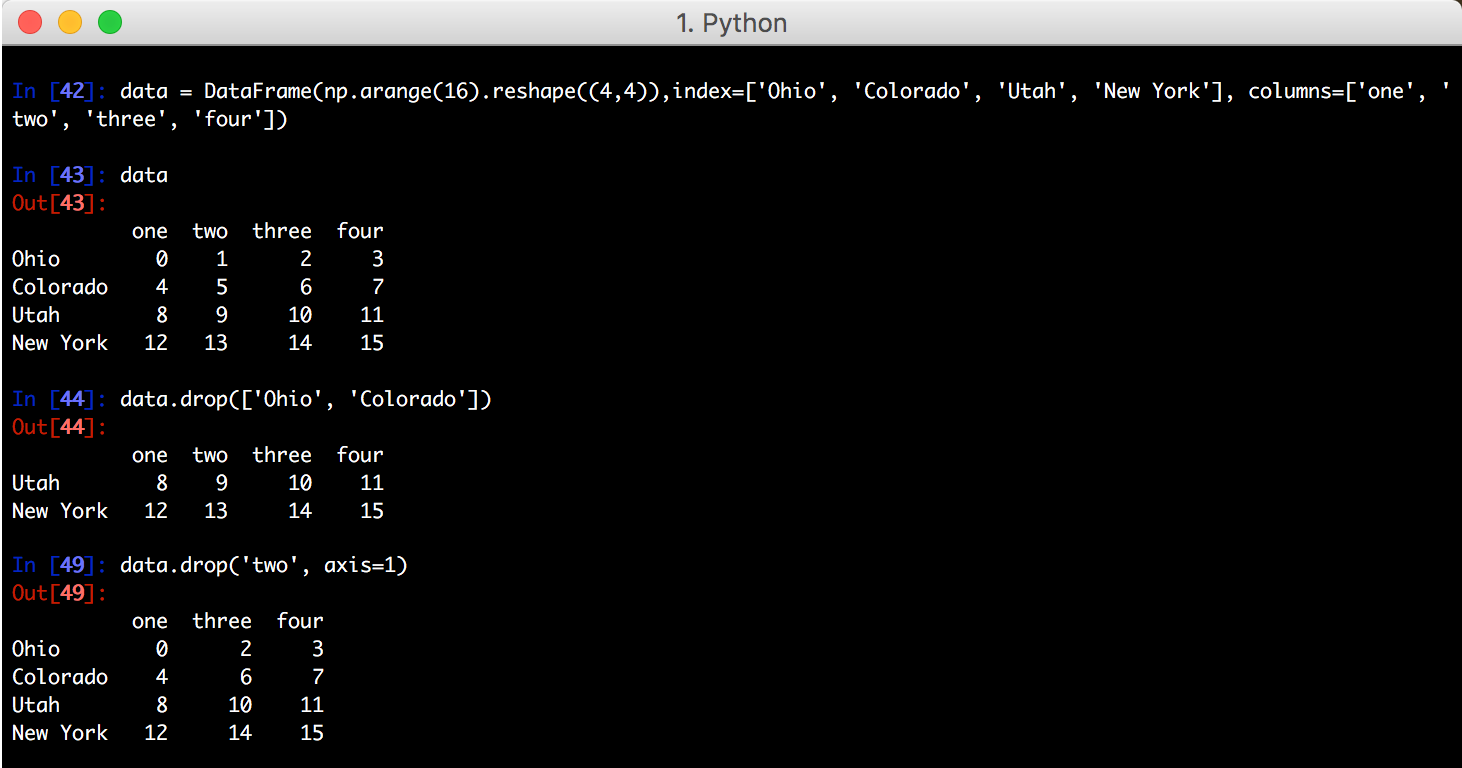
针对 DataFrame
不仅可以删除行,还可以删除列:
三、索引、选取和过滤
针对 Series
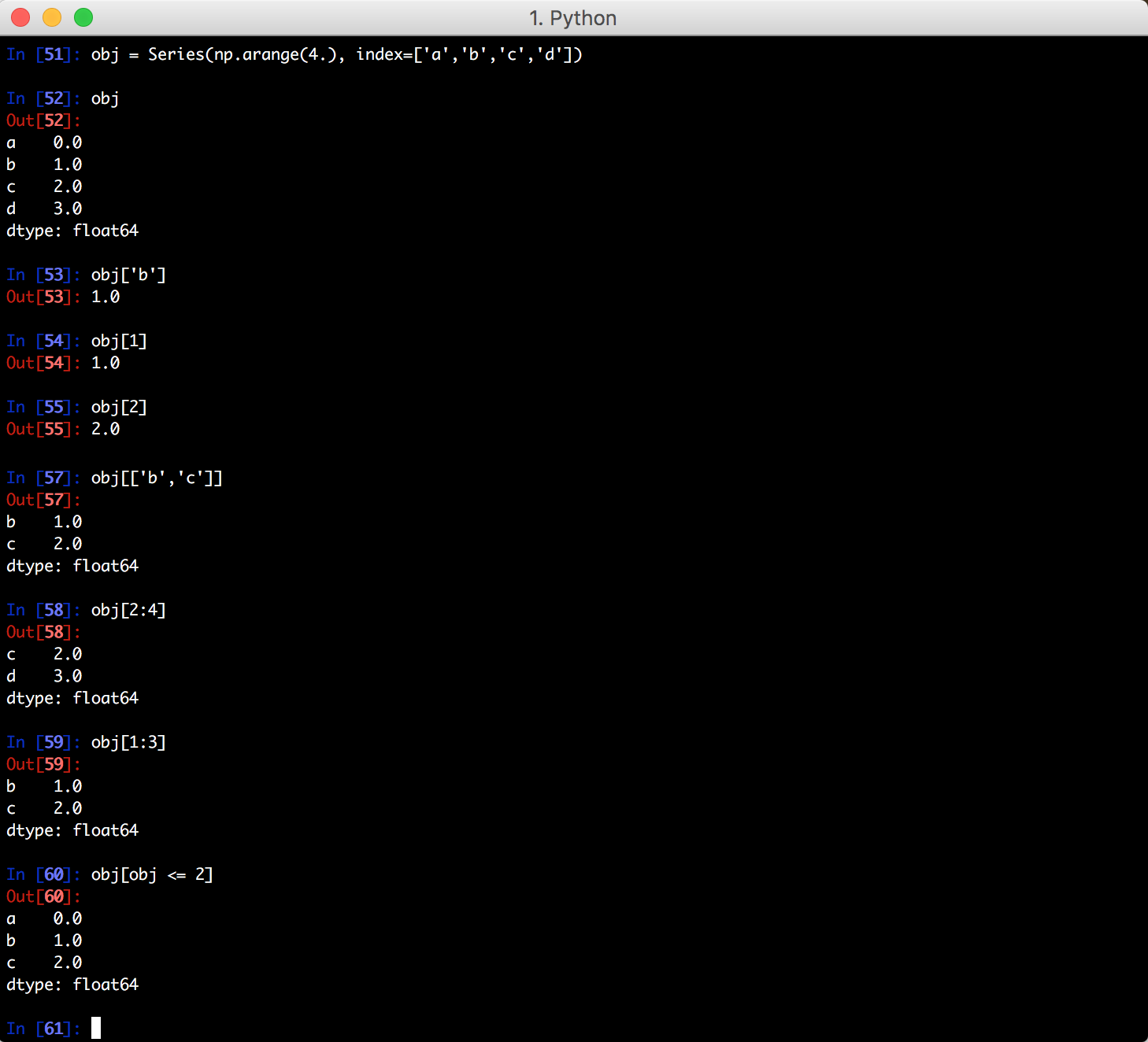
需要注意一点的是,利用索引的切片运算与普通的 Python 切片运算不同,其末端是包含的,既包含最后一个的项。比较:
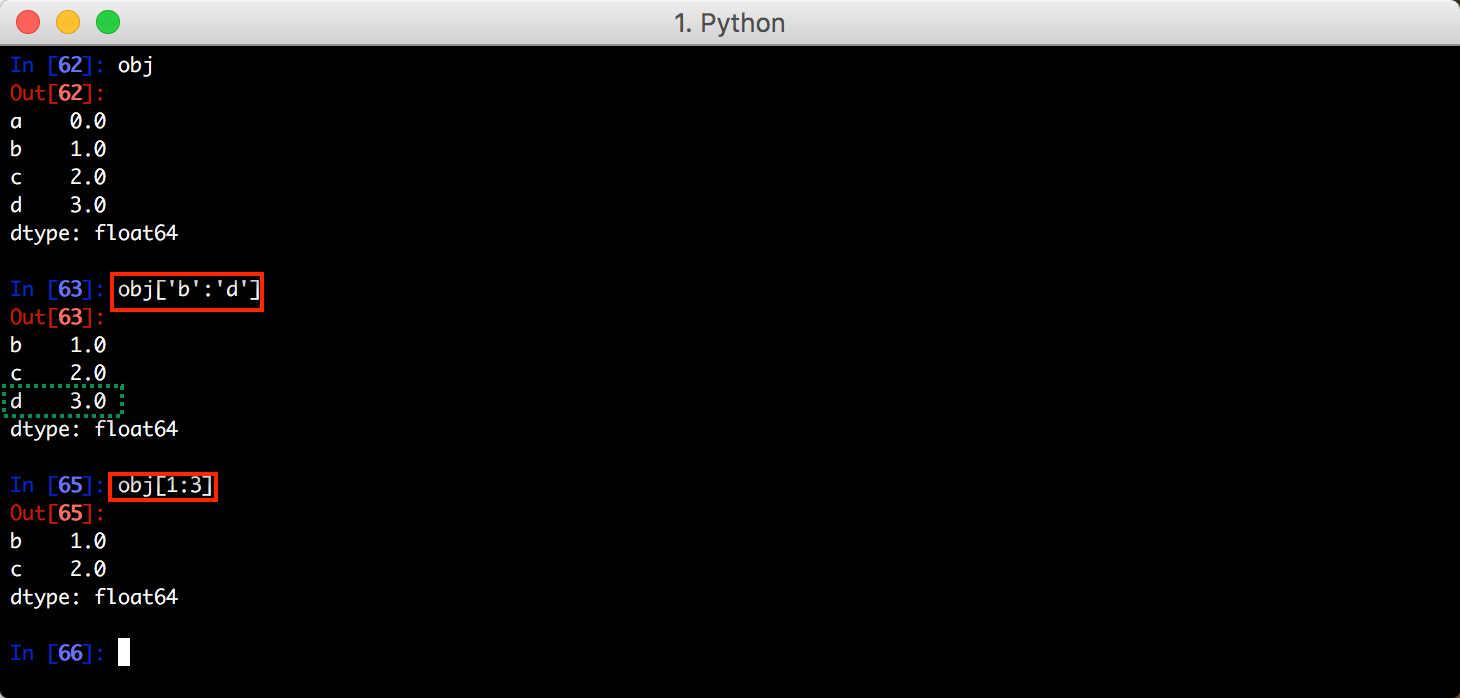
赋值操作:
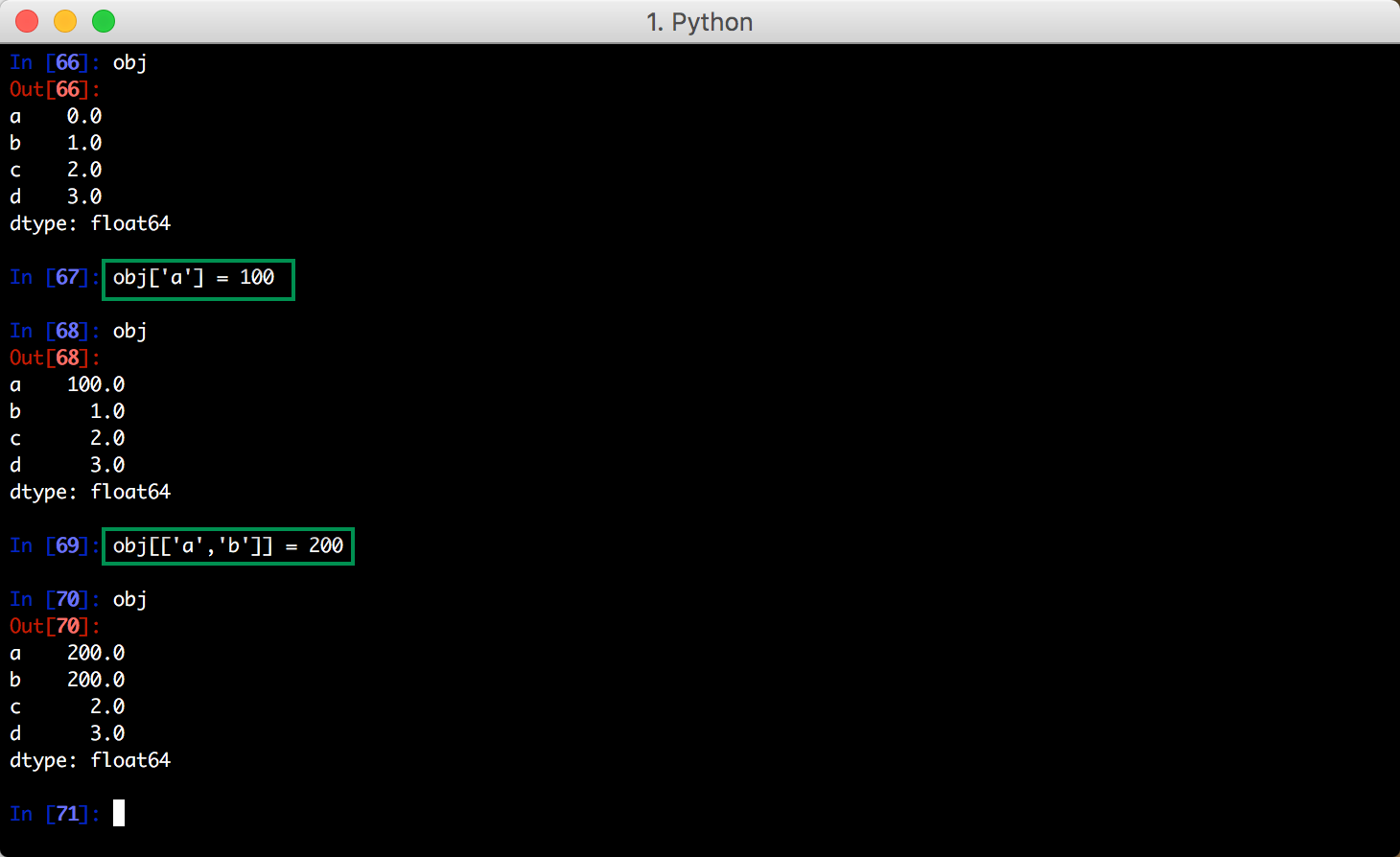
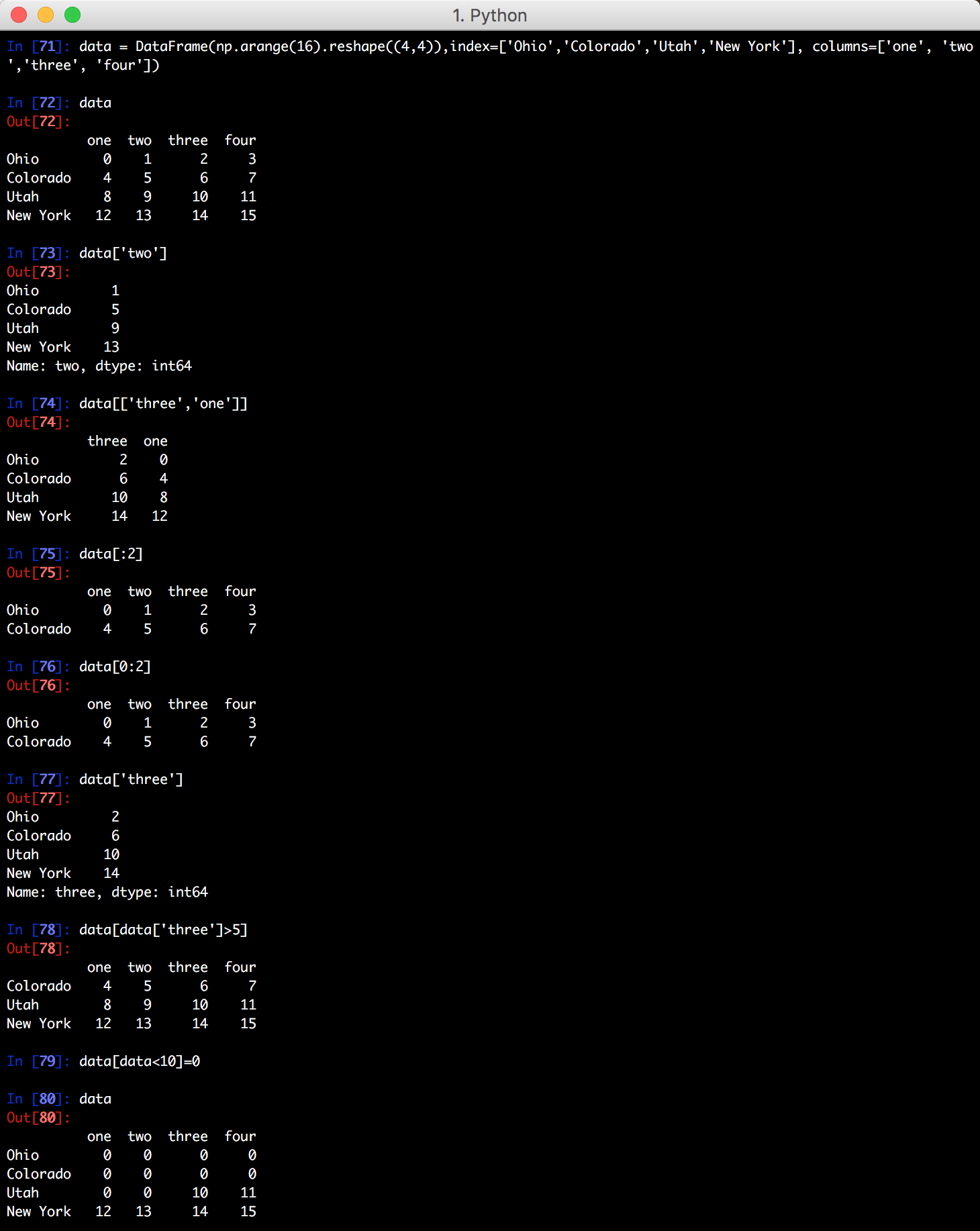
针对 DataFrame
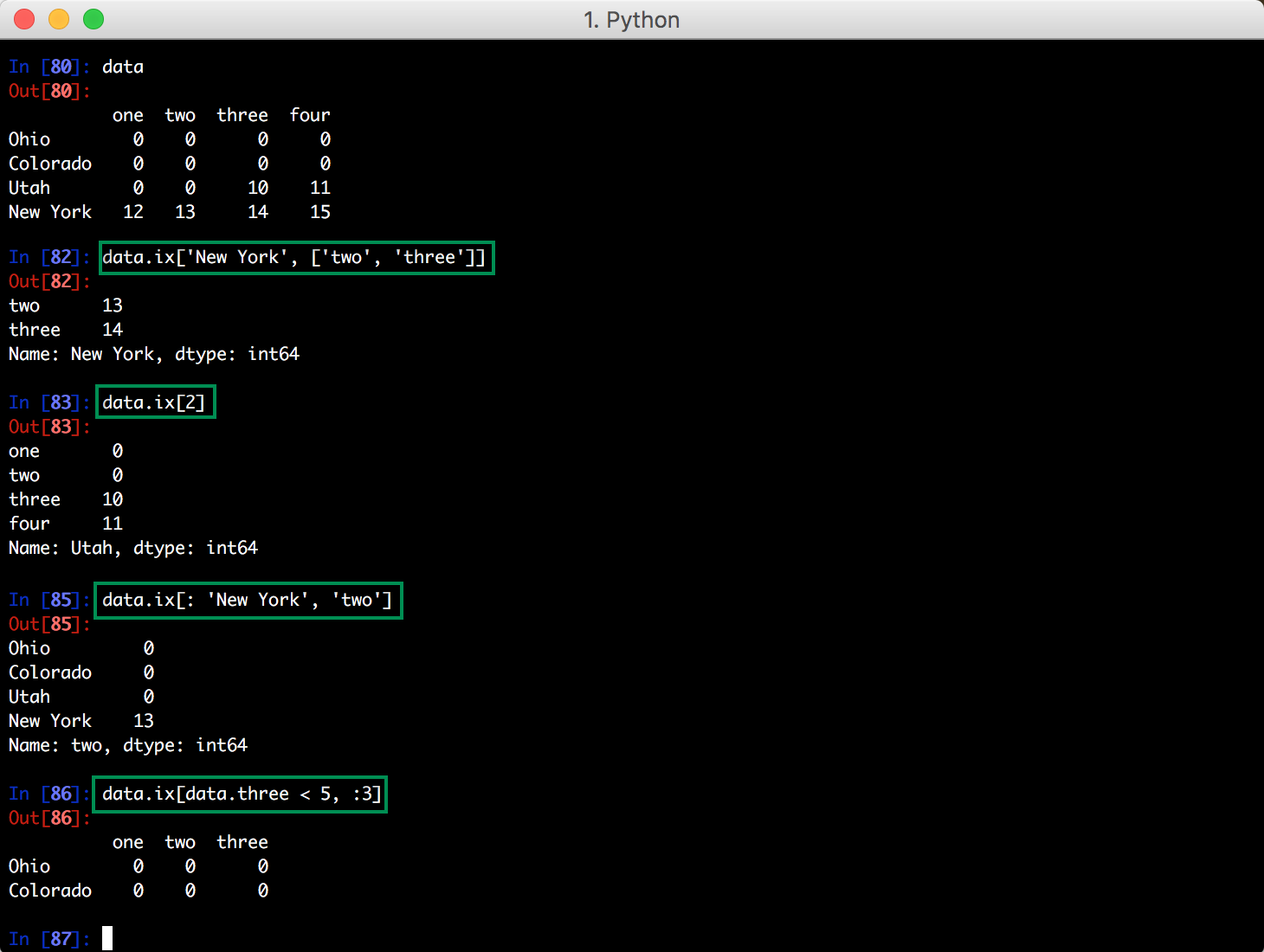
DataFrame 中的 ix 操作:
四、算术运算和数据对齐
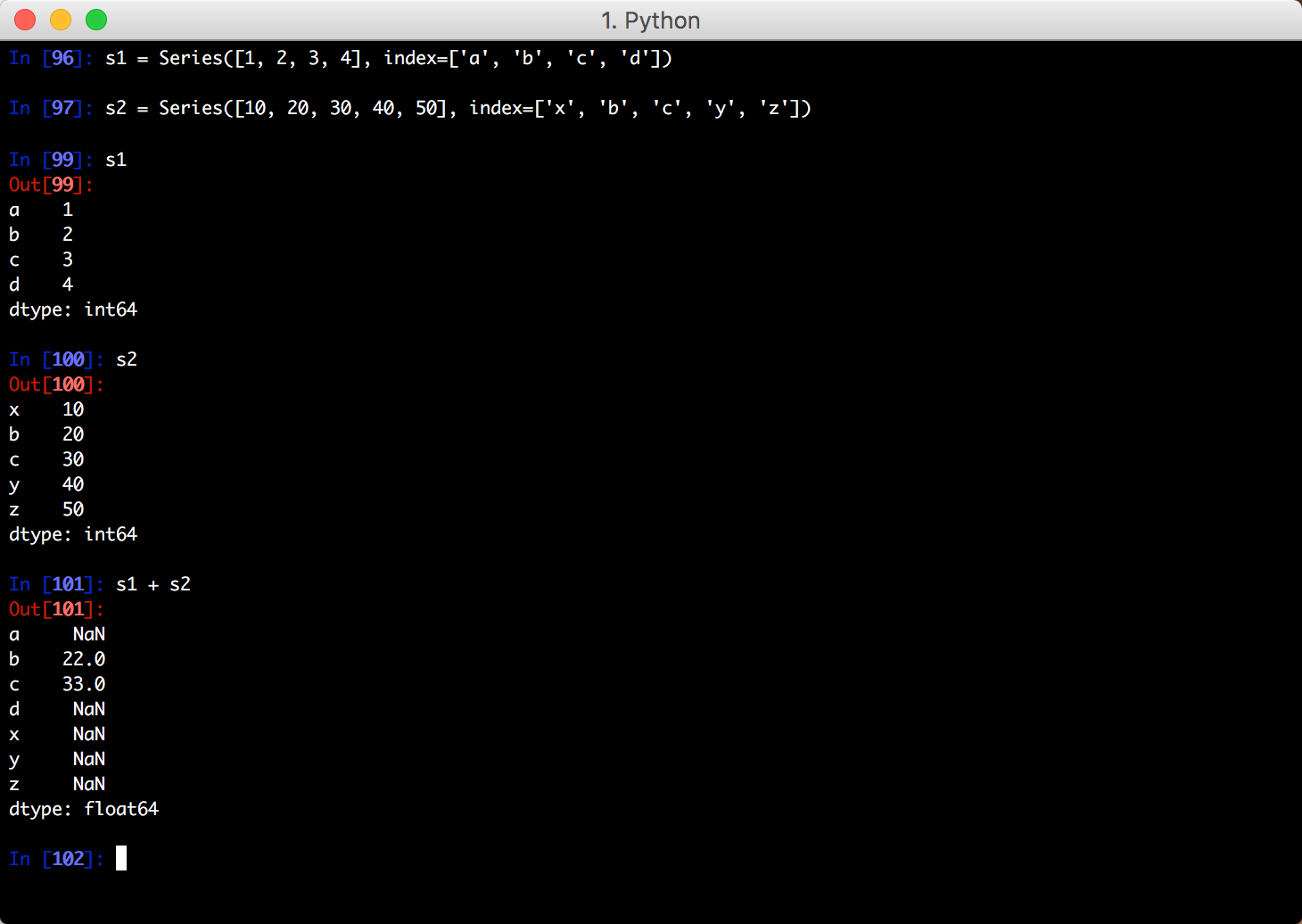
针对 Series
将2个对象相加时,具有重叠索引的索引值会相加处理;不重叠的索引则取并集,值为 NA:
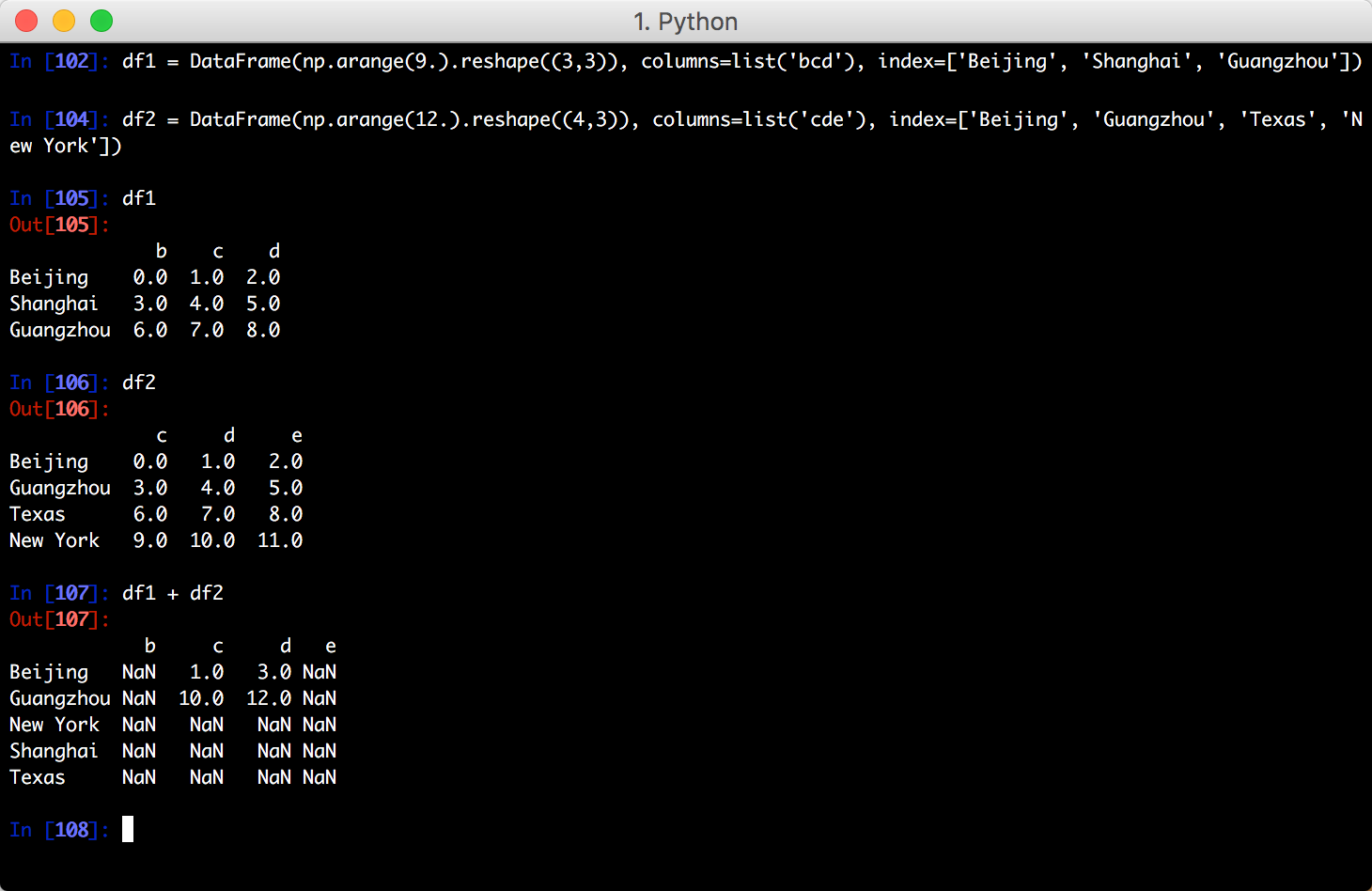
针对 DataFrame
对齐操作会同时发生在行和列上,把2个对象相加会得到一个新的对象,其索引为原来2个对象的索引的并集:
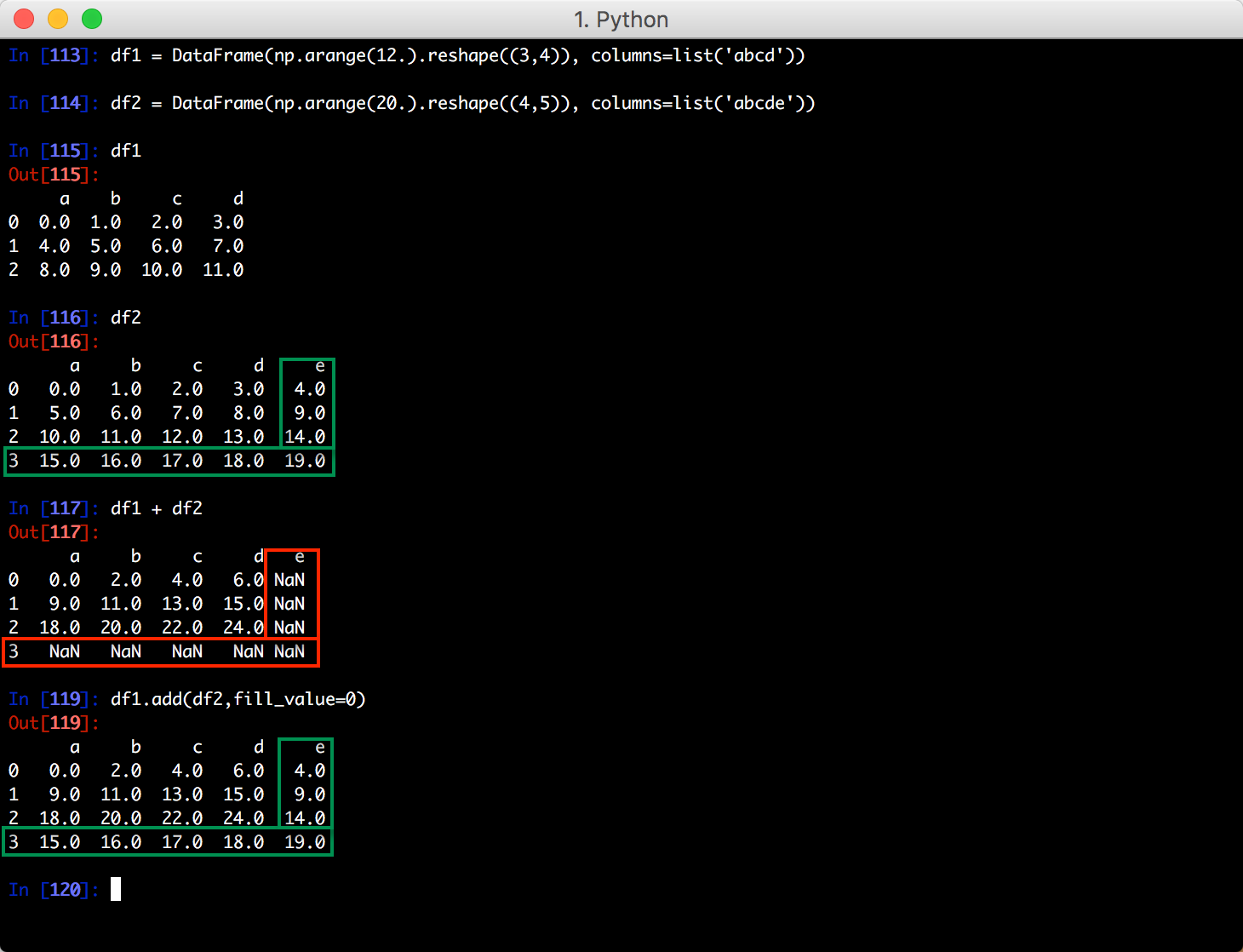
和Series 对象一样,不重叠的索引会取并集,值为 NA;如果不想这样,试试使用 add() 方法进行数据填充:
五、函数应用和映射
将一个 lambda 表达式应用到每列数据里:
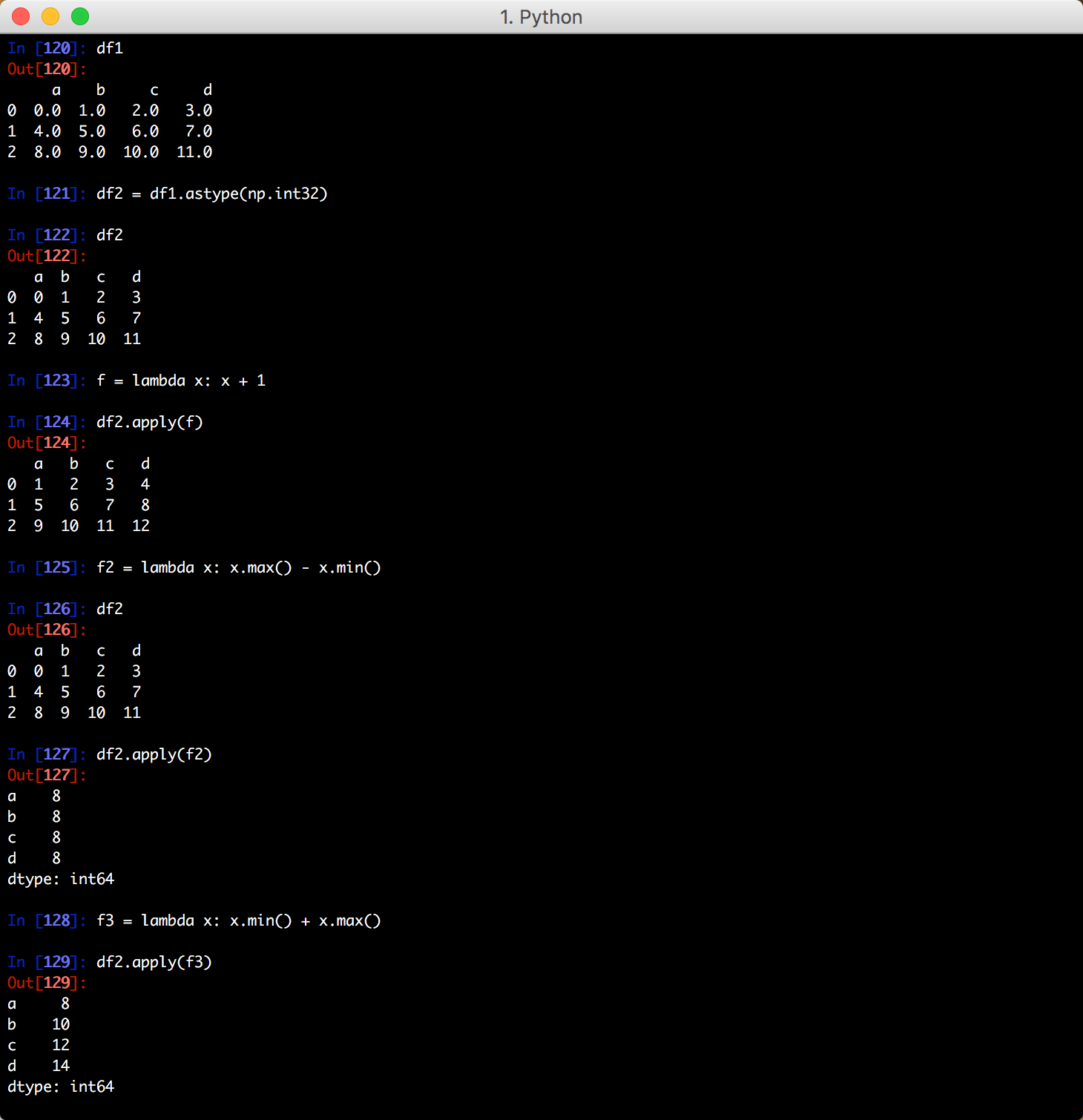
除了lambda 表达式还可以定义一个函数:
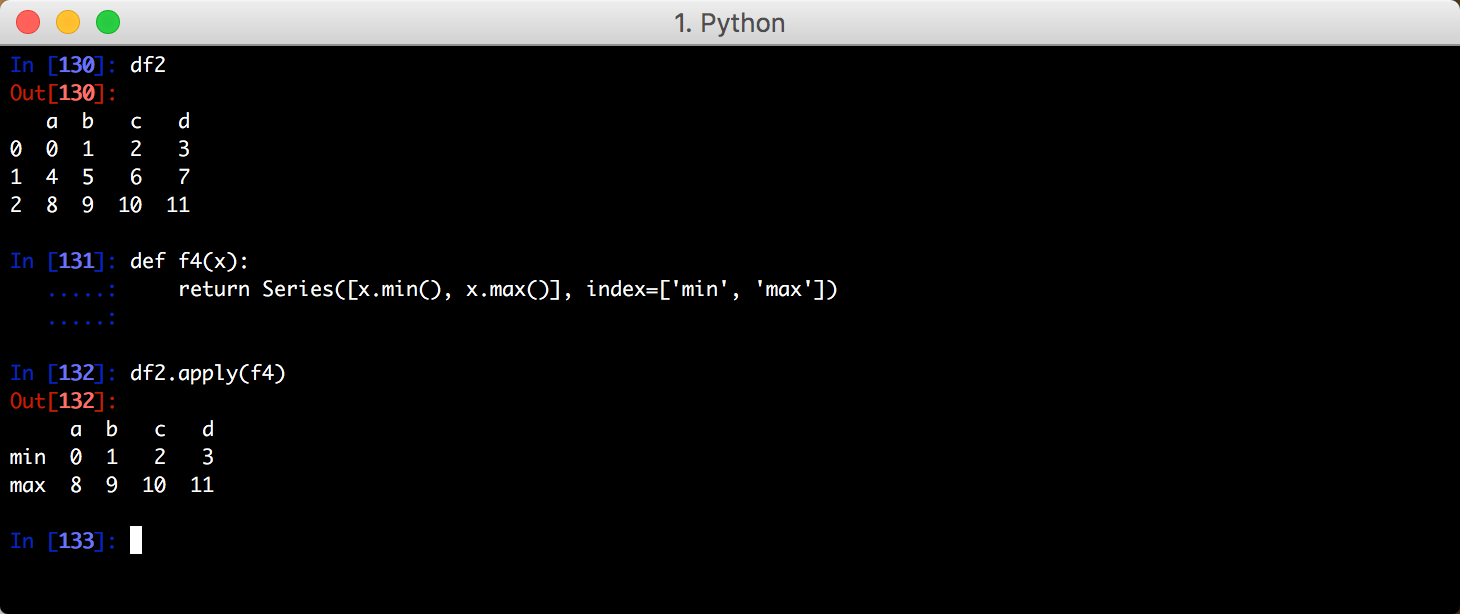
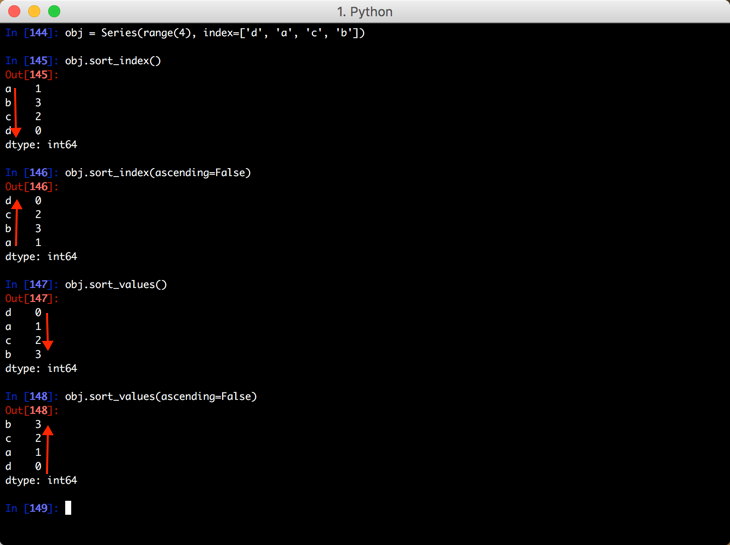
六、排序
针对 Series
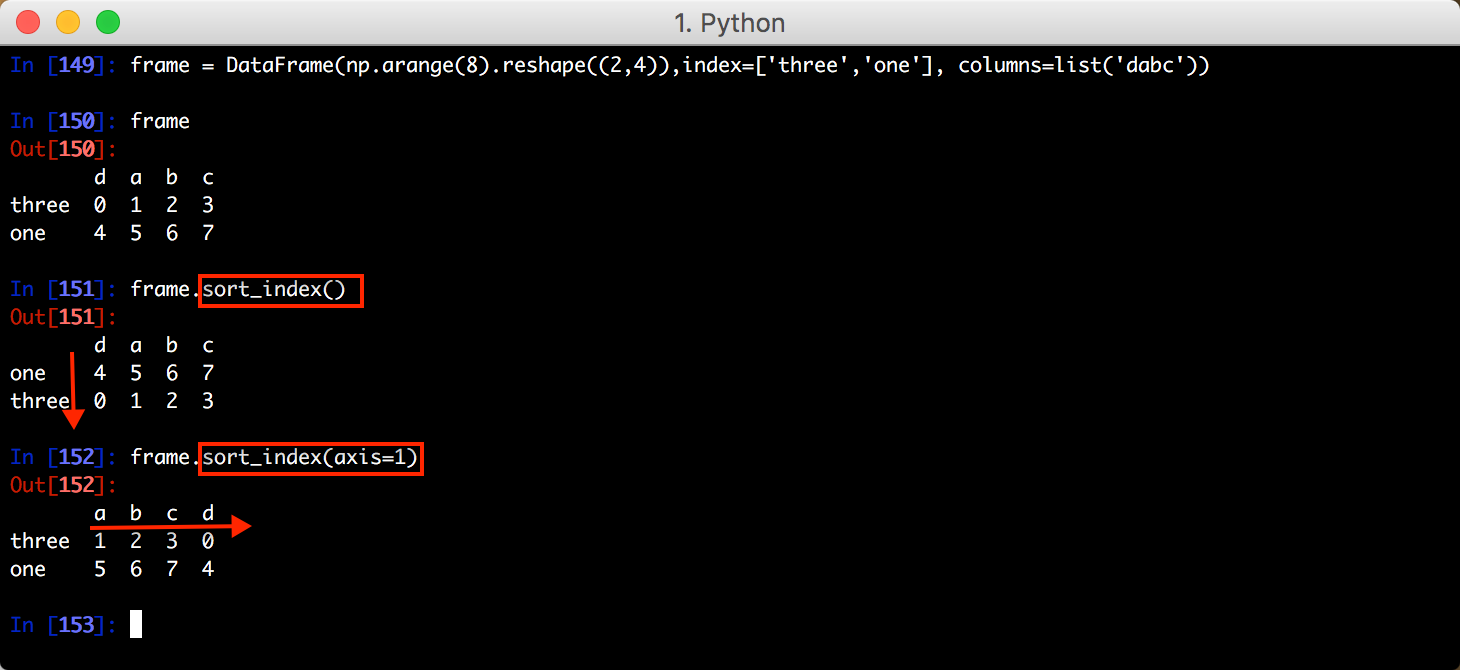
针对 DataFrame
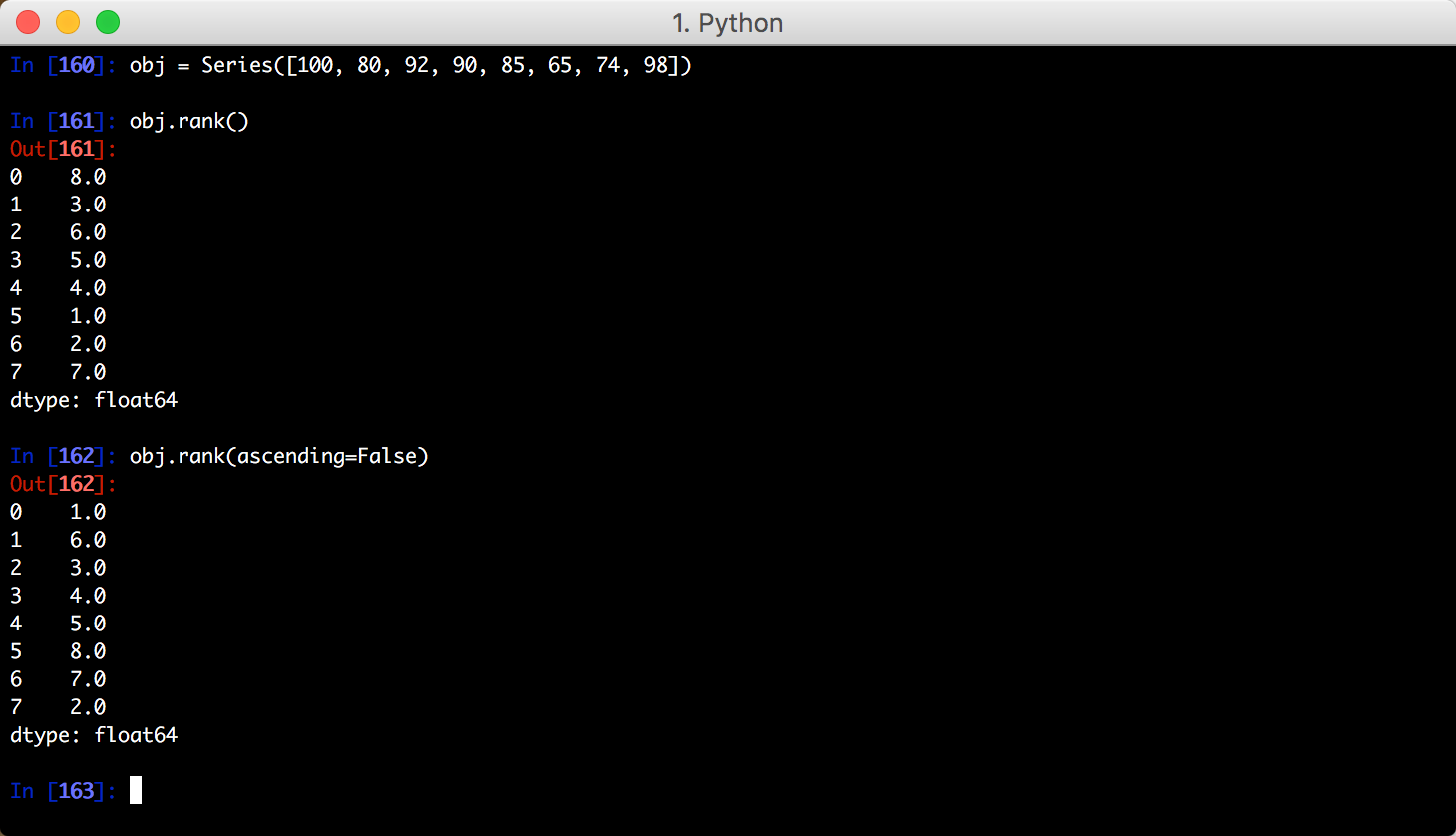
七、排名
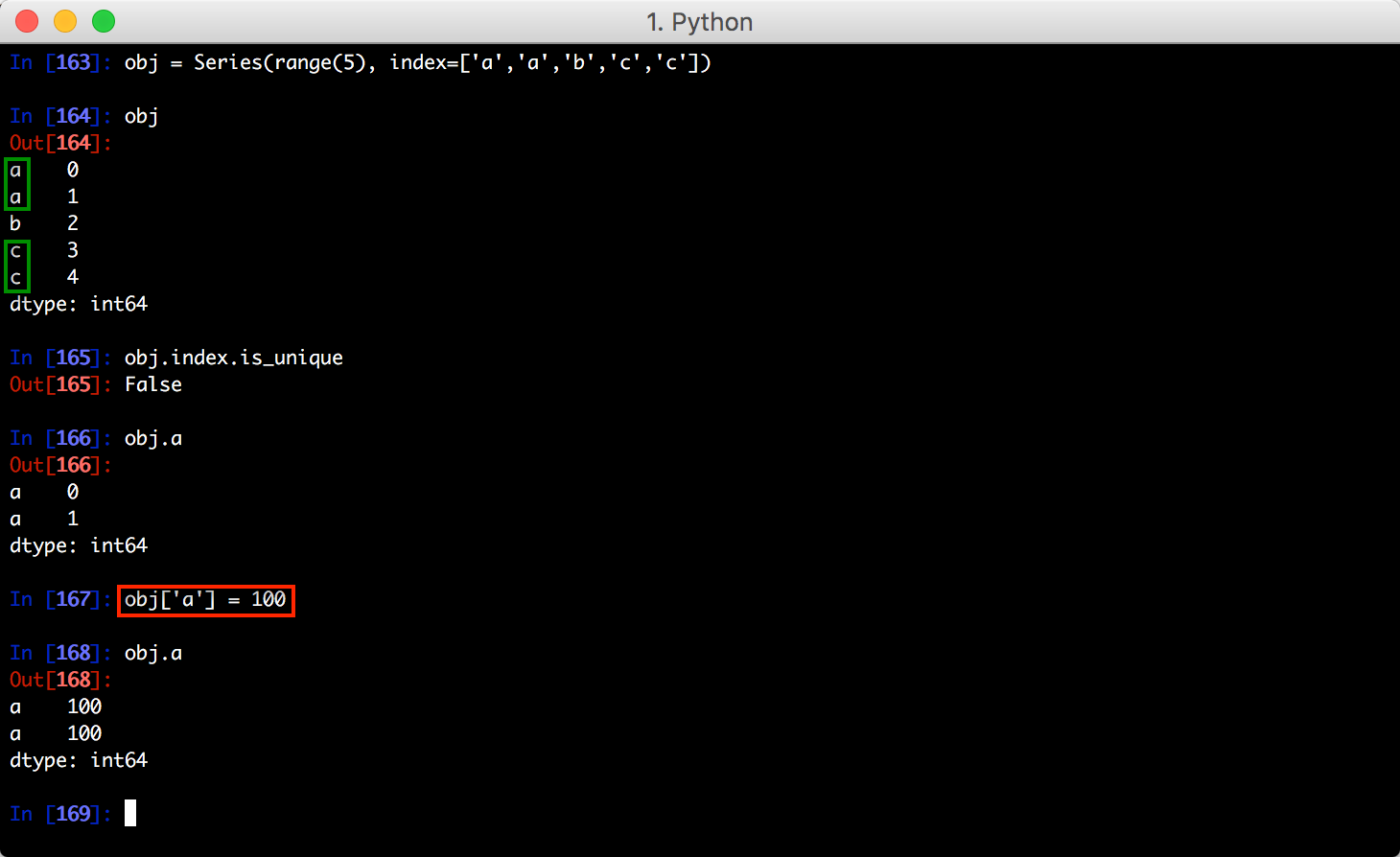
八、带有重复值的轴索引
索引不强制唯一,例如一个重复索引的 Series:
安装步骤已经在首篇随笔里写过了,这里不在赘述。利用Python进行数据分析(1) 简单介绍
接下来一篇随笔内容是:利用Python进行数据分析(9) pandas基础: 汇总统计和计算,有兴趣的朋友欢迎关注本博客,也欢迎大家添加评论进行讨论。
作者:backslash112 (美国CS研究生在读/机器人工程师)
出处:http://sirkevin.cnblogs.com
GitHub:https://github.com/backslash112
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
出处:http://sirkevin.cnblogs.com
GitHub:https://github.com/backslash112
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

posted on 2016-08-07 11:49 backslash112 阅读(30299) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架