

【Elasticsearch学习】DSL搜索大全
1.复合查询
复合查询能够组合其他复合查询或者查询子句,同时也可以组合各个查询的查询结果及得分,也可以从Query查询转换为Filter过滤器查询。
首先介绍一下Query Context和 Filter Context
1)Query Context查询主要关注的是文档和查询条件的匹配度,Query查询会计算文档和查询条件的相关度评分。
2)Filter Context过滤器主要关注文档是否匹配查询条件,并不关系文档和查询条件的匹配程度,也不会计算文档的相关度评分。过滤器查询速度比普通查询快,经常使用的过滤器将被ES自动缓存。
GET /kibana_sample_data_ecommerce/_search
{
"query": { //query context
"bool": {
"must": [
{ "match": { "customer_first_name": "Eddie"}},
{ "match": { "customer_gender": "MALE" }}
],
"filter": [ // filter context
{ "term": { "currency": "EUR" }},
{ "range": { "order_id": { "gte": "584679" }}}
]
}
}
}
1.1.Boolean Query
Bool查询由一个或多个bool查询子句组成,允许组合任意数量的查询子句,bool查询共有4钟查询类型。
1)must
如果查询子句为must,那么must子句中的所有查询条件都必须在匹配文档中出现。
2)must_not
查询条件中的任何一部分不能在文档中出现。
3)should
查询条件可以在匹配文档中出现也可以不出现,但是出现的数量至少要达到minimum_should_match参数所设置的数量,如果组合中使用了must子句,该值默认为0,如果没有使用该值默认为1.
4)filter
查询条件必须出现在匹配的文档中,但是该查询子句对于文档的评分没有影响,仅对文档进行过滤。
http://127.0.0.1:9200/kibana_sample_data_ecommerce/_search
{
"query": {
"bool" : {
"must" : [
{
"term" : { "day_of_week": "Monday" }
},
{
"term" : {"customer_gender": "FEMALE"}
}
]
}
}
}
1.2Boosting Query
Boosting Query返回和positive查询条件匹配的文档,减少与negative查询条件匹配的文档的分数。注意,只有匹配了positive查询条件的文档才会被返回,negative只是降低同时匹配positive条件和negative查询条件的文档的相关性评分。negative_boost为介于0和1.0之间的浮点数,用于降低与negative查询条件匹配的文档相关性评分。
GET /kibana_sample_data_ecommerce/_search
{
"query": {
"boosting" : {
"positive" : {
"match": {
"customer_first_name" : "Eddie"
}
},
"negative" : {
"match" : {
"customer_last_name" : "Underwood"
}
},
"negative_boost" : 0.5
}
}
}
1.3Constant Score Query
包装filter查询,返回所有匹配的文档,但是文档的相关度评分等于查询传入的boost值,默认值为1.0。
GET /kibana_sample_data_ecommerce/_search
{
"query": {
"constant_score" : {
"filter" : {
"match" : { "customer_first_name" : "Eddie"}
},
"boost" : 1.2
}
}
}
1.4Disjunction Max Query
将与任何一个查询条件匹配的文档作为结果返回,但是采用单个字段上最匹配的评分作为最终评分返回。
首先看一个不使用dis_max查询多查询字段匹配的例子,
GET /test/_search { "query": { "bool": { "should": [ { "match": { "title": "Brown fox" }}, { "match": { "body": "Brown fox" }} ] } } }
返回:可以看到文档2的body字段更加匹配查询条件"body": "Brown fox",但是由于文档1的title字段和body字段都有"brown"所以其评分叠加起来比文档2的评分更高。
{
"hits" : {
"max_score" : 0.90425634,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.90425634,
"_source" : {
"title" : "Quick brown rabbits",
"body" : "Brown rabbits are commonly seen."
}
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.77041256,
"_source" : {
"title" : "Keeping pets healthy",
"body" : "My quick brown fox eats rabbits on a regular basis."
}
}
]
}
}
dis_max不会将查询条件各个字段评分做简单的相加,而是将与查询条件匹配得分最高的单个字段的评分作为文档的评分返回。如下例:
GET /test/_search { "query": { "dis_max": { "queries": [ { "match": { "title": "Brown fox" }}, { "match": { "body": "Brown fox" }} ] } } }
返回:可以看到使用dis_max后文档1的评分降低了。
{
"hits" : {
"max_score" : 0.77041256,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.77041256,
"_source" : {
"title" : "Keeping pets healthy",
"body" : "My quick brown fox eats rabbits on a regular basis."
}
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"title" : "Quick brown rabbits",
"body" : "Brown rabbits are commonly seen."
}
}
]
}
}
dis_max查询的tie_breaker参数,如果在查询的时候根据查询场景需要考虑到其他查询字段的得分,则可以使用tie_breaker参数[0.0,1.0],使用tie_beaker之后,计算得分的过程将变为:
1.取到与查询条件最匹配的单个字段的评分,2.将与其他查询条件匹配的得分乘以tie_beaker,3.将1中最高分和2中的得分相加作为文档的评分返回。
1.5Function Score Query
function score query可以在查询结束后,对每一个匹配的文档重新算分,根据新生成的分数进行排序。
GET /_search
{
"query": {
"function_score": {
"query": { "match_all": {} },
"boost": "5",
"functions": [
{
"filter": { "match": { "test": "bar" } },
"random_score": {},
"weight": 23
},
{
"filter": { "match": { "test": "cat" } },
"weight": 42
}
],
"max_boost": 42,
"score_mode": "max",
"boost_mode": "multiply",
"min_score" : 42
}
}
}
score_mode:每一个文档将会被定义的函数打分,当有多个函数时由score_mode决定如何去组合各个函数的打分,score_mode的几个方法:multiply,各个得分相乘;sum,分数相加;avg,分数取平均;first,用第一个有match filter的函数的评分;max,选取分数的最大值;min,选取分数的最小值。
weight:因为各个函数的打分范围不同,例如衰减函数打分范围为[0,1],而field_value_factor的打分值是任意的,而且有时候希望不同的函数对文档的分数有不同的影响,用户可以使用weight权重来调整各个函数的得分,在每个function中定义weight的数值,函数计算出文档的得分后将会和其定义的weight值。
max_score:用于限制得分,function算出的新得分会被限制在max_boost内,默认为FLT_MAX。
boost_mode:决定function算出的分和query的得分如何组合:multiply,function和query得分相乘;replace,使用function的得分替换query的得分;sum,两者得分相加;avg,取两者均值;max,取两者较大值;min,取两者较小值。
min_score:用于排除分值低于阈值的文档。
function score支持的几种改变分值的函数:
1)script_score:包装一个子查询,通过自定义脚本的方式完全自定义计算文档的得分。
2)Weight:为每个文档设置一个权重,将文档的得分乘以该权重,该参数和boost类似,boost对文档得分的提升不是线性的,文档得分在乘以boost值后会被归一化(nomalize)处理,所以当不想将得分归一化处理时即可使用Weight来提升文档的得分。
3)random_score:随机均匀的产生在[0,1)之间的得分,可以为该函数提供种子(seed)和计算得分的字段(filed),这样来保证分数的可复制性。最后的得分将基于seed、filed以及salt(salt由索引名和分片id计算得来),所以有相同的值但是存储在不同索引中的文档会有不同的评分。但是在同一个分片中并具有相同字段值的文档将获得相同的分数,因此通常需要使用具有唯一值的字段来进行评分。
4)field_value_factor:可以使用文档中的字段来影响文档的得分
参数:field,用来计算得分的字段;factor,得分的乘数;modifier,得分的计算公式,可以为none(默认值), log, log1p, log2p, ln, ln1p, ln2p, square, sqrt, reciprocal;missing,如果指定的filed字段文档中没有,默认使用的值。如下计算公式为:sqrt(1.2 * doc['likes'].value)
"query": {
"function_score": {
"field_value_factor": {
"field": "likes",
"factor": 1.2,
"modifier": "sqrt",
"missing": 1
}
}
}
5)Decay functions:衰减函数,用户指定一个文档中的字段的值,衰减函数根据距离这个值的距离来进行打分;查询时需要为每个字段定义origin值和scale值,
origin代表的是中心点,用以计算其他值到中心点的距离;
scale代表衰减的范围,衰减的范围为[origin-offset-scale,origin-offset],[origin+offset,origin+offset+scale]
此外有两个可选值:offset、decay
offset表示衰减函数只计算到中心点距离大于offset的文档,即衰减函数计算的范围是[origin-offset-scale,origin-offset],[origin+offset,origin+offset+scale];
decay表示衰减到两个边界上时origin-offset-scale,origin+offset+scale文档的得分,默认为0.5分。如图:
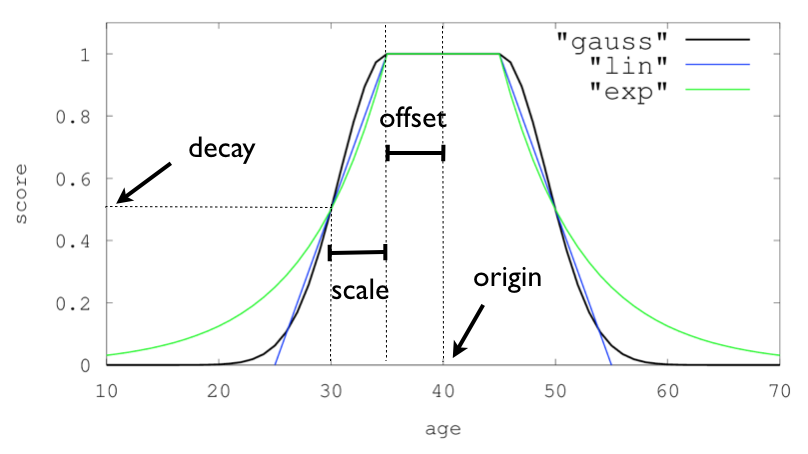
举例说明各参数的作用:假设衰减函数的origin定义为100,scale定义为10,offset定义为10,decay为0.5,那么衰减函数只会计算文档[80,90],[110,120],即介于90与110之间的文档评分与origin得分一样,在[80,90],[110,120]之间文档得分将会进行衰减,在80,120边界上的文档得分是decay:0.5。
如下例所示:DECAY_FUNCTION可以是linear(线性)、exp(指数)、gauss(高斯)这三种衰减函数,FILED_NAME即用来评分的字段必须为数值型、日期型或地理位置型。
"DECAY_FUNCTION": { "FIELD_NAME": { "origin": "11, 12", "scale": "2km", "offset": "0km", "decay": 0.33 } }
日期型衰减函数:
"function_score": { "gauss": { "date": { "origin": "2013-09-17", "scale": "10d", "offset": "5d", "decay" : 0.5 } } }
如果用于计算衰减的字段包含多个值,在默认情况下,将选择最接近原点的值来确定距离,可以通过设置multi_value_mode来改变这个方法:min:衰减距离使用多个字段距离中的最小值,max:衰减距离使用多个字段距离中的最大值,avg:衰减距离使用多个字段距离的平均值,sum衰减距离使用多个字段距离的和。
2.全文检索
全文检索使用户能够搜索分析过的文本,查询的关键字也会被文档索引时使用的分析器进行处理。
2.1Intervals Query
允许对匹配词项的顺序和邻近性进行细粒度控制。用户可以应用一个或多个规则集合在指定的字段上进行操作。
POST _search
{
"query": {
"intervals" : {
"my_text" : {
"all_of" : {
"ordered" : true,
"intervals" : [
{
"match" : {
"query" : "my favorite food",
"max_gaps" : 0,
"ordered" : true
}
},
{
"any_of" : {
"intervals" : [
{ "match" : { "query" : "hot water" } },
{ "match" : { "query" : "cold porridge" } }
]
}
}
]
}
}
}
}
}
interval查询顶层参数:
Field,用户希望查询的字段,上例为my_text。Field的参数为一个基于词项匹配度、顺序、接近度规则的对象用于匹配文档,上例为{"all_of":"...."}。
有如下一些规则:
1)match:match规则匹配分析后的文本。参数:
query:希望在Field字段中匹配的内容。
max_gaps:匹配的词项之间间隔的最大词数,超过max_gaps的被视为不匹配,默认为-1,如果没有设定,则对词项之间的间隔没有限制;如果设置为0,那么匹配的词项之间必须仅仅相邻。
ordered:如果为true,那么匹配的词项出现的顺序必须和查询内容的顺序一致,默认为false。
analyzer:用于分析查询内容的分析器,默认和文档的分析器一致。
filter:intervals filter。
use_field:如果指定该字段,那么此规则将应用于该字段而不是顶层Field字段。
POST /test/_search { "query": { "intervals" : { "body" : { "match" : { "query" : "quick rabbits", "max_gaps" : 10 } } } } }
2)prefix:前缀规则匹配以指定字符集开头的词项,prefix最多可以扩展到匹配128个字符,如果超过128个字符,ES将返回错误。参数:
prefix:希望顶层Field开头的字符。
analyzer:用以处理prefix的分析器。
use_field:如果指定该字段,那么此规则将应用于该字段而不是顶层Field字段。
POST /test/_search { "query": { "intervals" : { "body" : { "prefix" : { "prefix" : "Keeping", "use_field":"title" } } } } }
3)wildcard:wildcard使用通配符模式,最多能匹配128个词项。参数:
pattern:通配符,支持*、?两种通配符。
analyzer:同上。
use_field:同上。
POST /test/_search { "query": { "intervals" : { "body" : { "wildcard" : { "pattern" : "rab?i*" } } } } }
4)fuzzy:模糊规则匹配与提供的term相似的词项。参数:
term:需要匹配的词项。
prefix_length:保持不变的前缀的数量。
transpositions:模糊规则是否包含两个相邻字符的转换,默认为true。
fuzziness:通常被解释为莱文斯坦距离也叫做Edit Distance,指的是一个词与另一个词匹配需要编辑的次数,编辑操作替换字符,插入字符,删除字符,需要编辑的次数越多,说明Edit Distance越大。fuzziness的参数:0,1,2表示最大的编辑次数,默认为AUTO参数,表示根据term的长度自动生成编辑次数。
analyzer:同上。
use_field:同上。
POST /test/_search { "query": { "intervals" : { "body" : { "fuzzy" : { "term" : "rabibst",//需要移动两次 "fuzziness":2 //两次edit } } } } }
5)all_of:综合其他的interval规则,返回的文档必须满足所有的intervals规则。参数:
intervals:要组合的规则数组。
max_gaps:
ordered:决定各个规则产生的结果是否排序。
filter:intervals filter。
POST /test/_search
{
"query": {
"intervals" : {
"body" : {
"all_of" : {
"intervals" : [//match、prefix规则均需满足
{
"match" : {
"query" : "quick"
}
},
{
"prefix" : {
"prefix":"My"
}
}
]
}
}
}
}
}
6)any_of:满足任一子规则的文档即可返回。
intervals:匹配的规则数组。
filter:intervals filter。
POST /test/_search
{
"query": {
"intervals" : {
"body" : {
"any_of" : {
"intervals" : [ //match、prefix规则满足其一即可
{
"match" : {
"query" : "commonly"
}
},
{
"prefix" : {
"prefix":"My"
}
}
]
}
}
}
}
}
intervals filter参数:
after:匹配的词项在filter rule后。
before:匹配的词项在filter rule前。
contained_by:匹配的词项由filter rule包含。
not_contained_by:匹配的词项不被filter rule包含。
not_containing:fiter rule不在匹配间隙之间出现。
not_overlapping:匹配的词项和filter rule不重叠。
overlapping:匹配的词项和filter rule有重叠。
script:决定文档是否返回的自定义脚本。
POST /test/_search
{
"query": {
"intervals" : {
"body" : {
"match" : {
"query" : "commonly",
"filter":{
"contained_by" : {
"match" : {
"query" : "Brown seen" //brown seen 必须包含commonly词项
}
}
}
}
}
}
}
}
POST /test/_search
{
"query": {
"intervals" : {
"body" : {
"match" : {
"query" : "brown rabbits",
"max_gaps" : 10,
"filter":{
"not_containing" : {
"match" : {
"query" : "fox" //fox 不能出现在brown rabbits 之间
}
}
}
}
}
}
}
}
POST /test/_search
{
"query": {
"intervals" : {
"body" : {
"match" : {
"query" : "commonly",
"filter":{
"overlapping" : {
"match" : {
"query" : "Brown seen" //match规则查出的结果文档为Brown rabbits are commonly seen 与commonly 有重叠的地方
}
}
}
}
}
}
}
}
2.2Match Query
返回与提供的搜索文本相匹配的文档,搜索文本在匹配之前会被分析器进行分析。
参数:
顶层参数:Filed,表示想要搜索的字段。
Field下的参数:
1.query:想要在Field字段中匹配到的内容,match查询在查询之前会对查询内容进行分析。
2.analyzer:分析器,如果field的mapping中有定义分析器,则使用field的分析器,如果没有,则使用索引默认的分析器。
3.auto_generate_synonyms_phrase_query:是否开启同义词匹配,默认为false。
4.fuzziness:模糊匹配,参数见interval query fuzzy。
5.max_expansions:控制模糊匹配fuzzy能扩展多少个模糊选项。如test在fuzziness为1的时候,能匹配很多模糊选项:tes,tets,etst等,使用max_expansions控制能匹配多少个模糊选项。
6.prefix_length:fuzzy匹配时,保持不变的字符前缀数,默认为0。
7.transpositions:如果true,那么fuzzy匹配允许字符交换位置,ab->ba。
8.fuzzy_rewrite:重写查询的方法,
9.lenient:如果true,则忽略查询格式错误,例如为数值字段提供文本查询值。默认为false。
10.operator:用于解析查询值的bool逻辑。默认为OR,如果Query值为quick brown fox,则匹配规则为quick or brown or fox;此外还有AND值。
11.minimum_should_match:返回的文档必须匹配的子句数量。
12.zero_terms_query:决定当分析器移除所有的分词时是否返回文档,如当查询内容中都是停用词时,所有的分词被分析器的停用词过滤器过滤掉时,是否返回文档。默认为none,不返回任何文档,all,返回所有文档。
测试数据: POST /test/_doc/3 { "title": "tets healthy", "body": "My quick brown fox eats rabbits on a regular basis." } POST /test/_doc/4 { "title": "tes healthy", "body": "My quick brown fox eats rabbits on a regular basis." }
测试案例:
POST /test/_search { "query": { "match" : { "title":{ "query":"test", "fuzziness":1, "max_expansions": 1 //最大扩展数,test只允许有一个模糊选项,匹配的结果只有一个 } } } }
2.3Match boolean prefix query
match_bool_prefix分析查询内容,并将分词出来的各个词项组合成为一个bool查询,除了最后一个词项其他的词项都会被用在term query中,最后一个词项被用在prefix query中。
例如:
POST /test/_search { "query": { "match_bool_prefix" : { "message" : "quick brown f" } } }
这个查询类似于:
POST /test/_search { "query": { "bool" : { "should": [ { "term": { "message": "quick" }}, { "term": { "message": "brown" }}, { "prefix": { "message": "f"}} ] } } }
参数:
顶层参数:Filed,表示想要搜索的字段。
1.query:想要在Field字段中匹配到的内容。
2.analyzer:分析器,默认使用字段mapping中的分析器。
3.minimum_should_match:返回的文档最少匹配查询条件的程度。
4.operator:使用AND还是OR去连接词项。
5.模糊查询可以用于所有的分词起器分析出的词项,除了最后一个词项。
POST /test/_search { "query": { "match_bool_prefix" : { "body": { "query": "fox eats", "operator":"AND", "fuzziness":1 } } } }
2.4Match phrase query
match_phrase查询分析搜索内容并创建一个短语查询。
match_phrase的词项之间的间隔为0,analyzer使用查询字段mapping字段定义,如果未定义则使用默认查询分析器。
GET /test/_search
{
"query": {
"match_phrase" : {
"body": {
"query": "quick brown fox",
"analyzer":"whitespace"
}
}
}
}
2.5Match phrase prefix query
返回包含搜索内容的文档,与搜索内容提供的顺序一致。搜索内容的最后一个词项作为前缀匹配任何以前缀开始的词项。
参数:
顶层参数:Filed,表示想要搜索的字段。
query:想要搜索的文本。
analyzer:分析器。
max_expansions:最后一个查询词作为前缀去匹配到的词项最多扩展数。
slop:分词之间的最大间隔数,默认为0。
zero_terms_query:见Match Query。
GET /test/_search { "query": { "match_phrase_prefix" : { "body" : { "query" : "quick brown f", "max_expansions": 2 //为2代表以f开头的词项只会返回两种 } } } }
2.6Multi match query
multi match query以match query为基础,构建多字段的match查询。
参数:
1.query:查询文本。
2.fields:查询字段,支持多个字段,最多查询字段数由indices.query.bool.max_clause_count定义,默认为1024个。
3.type:查询的类型。
best_fields:查找匹配任意field的文档,但是文档的得分来自最匹配的那个字段。
most_fields:组合所有字段的得分,作为文档的评分。
cross_fields:将多个字段组合成一个字段,在组合成的字段里去查询。
phrase:每个字段以match_phrase方式查询,使用最匹配字段的得分作为文档的评分。
phrase_prefix:每个字段以match_phrase_prefix方式查询,,使用最匹配字段的得分作为文档的评分。
bool_prefix:每个字段以match_bool_prefix方式查询,组合所有字段的得分作为文档的评分。
4.tie_breaker:当使用tie_breaker时,best_field会根据tie_breaker定义的值的大小,决定除最佳匹配字段得分以外其他字段的得分。为tie_breaker * (其他字段_score)之和。
5.其他参数:analyzer, boost, operator, minimum_should_match, fuzziness, lenient, prefix_length, max_expansions, rewrite, zero_terms_query, cutoff_frequency, auto_generate_synonyms_phrase_query and fuzzy_transpositions。
GET /test/_search { "explain": true, "query": { "multi_match" : { "query": "brown fox", "type": "best_fields", "fields": [ "title", "body" ] } } }
GET /_search { "query": { "multi_match" : { "query": "Will Smith", "type": "cross_fields", "fields": [ "first_name", "last_name" ], "operator": "and" } } }
这个查询类似与:
(+first_name:will +first_name:smith) | (+last_name:will +last_name:smith)
所有的搜索词项都必须在单独的字段(也可以是多个字段组合成的单个字段,如first_name+last_name)中出现。
2.6Common Terms Query
使用语法基于操作符如:AND OR来解析和分割查询字符串,然后用分析器对分割的部分就行分析,并与文档进行匹配。
参数:
1.query:查询字符串。
2.default_field:当query_string没有指定查询字段时候,默认查询的字段。默认值为索引设定的index.query.default_field值,index.query.default_field默认值为*。
3.allow_leading_wildcard:true的时候,通配符*,?可以被作为查询字符串的首个字符。默认为true。
4.analyze_wildcard:true的时候,查询会分析查询字符串中的通配符。
5.analyzer:用于分析查询字符串的分析器,默认为文档索引时候的分析器。
6.auto_generate_synonyms_phrase_query:true的时候,自动创建多同义词查询。
7.boost:浮点数用于增加或减少查询的相关度评分。
8.default_operator:如果没有定义operator,默认被用作解析查询字符串的操作符。OR(默认)
9.enable_position_increments:
10.fields:希望查询的字段的集合。
11.模糊匹配相关:fuzziness,fuzzy_max_expansions模糊匹配最大扩展数,fuzzy_prefix_length模糊匹配前缀数,fuzzy_transpositions,lenient。
12.max_determinized_states:确定一个查询需要的最大的自动机的数量。解释:https://www.jianshu.com/p/9edca9474663?utm_source=desktop&utm_medium=timeline
13.minimum_should_match:返回的文档最少匹配查询条件的程度。
14.quote_analyzer:用于分析在引号中的查询文本。
15.phrase_slop:匹配的两个分词之间间隔的最大词项数。
16.quote_field_suffix:附加到引号查询文本的后缀。
17.rewrite:用于重写查询的方法。
18.time_zone:时区,用于转换日期参数。
2.7Simple Query String
返回匹配查询字符串的文档,使用有限制的但是容错的语法去解析查询字符串。该查询使用简单的语法基于操作符去解析和分割查询字符串,在查询之前分别分析各个词项。因为对语法有更多的限制,索引当有不合规的语法时不会返回错误,忽略查询字符串中不合法的部分。
参数:
1.Query:搜索内容。
2.Fields:搜索的字段集合。
3.default_operator:如果没有定义operator,默认被用作解析查询字符串的操作符。OR(默认)
4.analyze_wildcard:true的时候,查询会分析查询字符串中的通配符。
5.analyzer:用于分析查询字符串的分析器,默认为文档索引时候的分析器。
6.auto_generate_synonyms_phrase_query:true的时候,自动创建多同义词查询。
7.flags:查询操作可以使用的操作符列表。合法操作符:AND、ESCAPE、FUZZY、NEAR、NONE、NOT、OR、PHRASE、PRECEDENCE、PREFIX、SLOP、WHITESPACE。
8.其他参数:fuzzy_max_expansions、fuzzy_prefix_length、fuzzy_transpositions、lenient、minimum_should_match、quote_field_suffix。
3.词条查询-Term Query
词条查询是基于文档值精确匹配的查询,比如说日期、IP地址,价格,物品ID等;和全文检索不一样,词条查询不对搜索词项进行分析,词条查询匹配字段中存储的真实值。
3.1.Exits Query
返回字段索引值不为空的文档。
字段索引值为空的原因:字段在源数据中是null或者[];字段配置了index:false属性;字段值的长度超过了ignore_above配置值;字段值格式不对,而且定义了ignore_malformed(忽略格式不对的值)。
参数:
field:想要查询的字段。
GET /test/_search
{
"query": {
"exists": {
"field": "body"
}
}
}
3.2.Fuzzy Query
返回文档中词项与搜索词项相似的文档。
参数:
顶层参数:field,想要查询的字符串。
field的参数:
1.value:想要在field中查询到的值。
2.fuzziness:通常被解释为莱文斯坦距离也叫做Edit Distance,指的是一个词与另一个词匹配需要编辑的次数,编辑操作替换字符,插入字符,删除字符,需要编辑的次数越多,说明Edit Distance越大。fuzziness的参数:0,1,2表示最大的编辑次数,默认为AUTO参数,表示根据term的长度自动生成编辑次数。
3.max_expansions:模糊规则最大的扩展数,默认为50。
4.prefix_length:fuzzy匹配时,保持不变的字符前缀数,默认为0。
5.transpositions:如果true,那么fuzzy匹配允许字符交换位置,ab->ba。
6.rewrite:重写查询的方法。
3.3.IDs
基于IDs返回文档,使用存储在_id字段中的IDs。
GET /test/_search
{
"query": {
"ids" : {
"values" : ["1", "4", "5"]
}
}
}
3.4.Prefix Query
返回字段值以查询值为前缀的文档。
参数:field,field的参数(value,rewrite)
GET /test/_search
{
"query": {
"prefix": {
"body": {
"value": "bro"
}
}
}
}
3.5.Range Query
返回包含词项在提供的范围内的文档。
参数:
顶层参数,field,想要查询的参数。
field的参数:
1.gt 大于。
2.gte 大于等于。
3.lt 小于。
4.lte 小于等于。
5.format 用于转化日期的格式。
6.relation 表示范围查询如何匹配range类型的字段值。
INTERSECTS:返回range字段值和查询范围相交的文档。(默认)
CONTAINS:返回range字段值匹配完全包含查询范围的文档。
WITHIN:返回range字段值完全在查询范围内的文档。
7.time_zone:查询UTC时间时,用于将查询时间转换为UTC时间的偏移量。
8.boost:浮点数用于增加或减少查询的相关度评分。
测试一下range字段的搜索,range field有以下六种类型:integer_range、float_range、long_range、double_range、date_range、ip_range
PUT range_index
{
"mappings": {
"properties": {
"integer_range_test": {
"type": "integer_range"
},
"float_range_test": {
"type": "float_range"
},
"long_range_test": {
"type": "long_range"
},
"double_range_test": {
"type": "double_range"
},
"date_range_test": {
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"ip_range_test": {
"type": "ip_range"
}
}
}
}
插入数据:
PUT range_index/_doc/1
{
"integer_range_test" : {
"gte" : 10,
"lte" : 20
},
"date_range_test" : {
"gte" : "2015-11-01",
"lte" : "2015-11-30"
},
"ip_range_test":{
"gte" : "255.255.1.1",
"lte" : "255.255.1.255"
}
}
GET /range_index/_search
{
"query": {
"range" : {
"integer_range_test" : {
"gte" : 5,
"lte" : 15,
"relation":"INTERSECTS" //[5,15]和[10,20]相交,返回一条结果
}
}
}
}
GET /range_index/_search
{
"query": {
"range" : {
"ip_range_test" : {
"gte" : "255.255.1.10",
"lte" : "255.255.1.220",
"relation":"CONTAINS" //[255.255.1.1,255.255.1.255]完全包含[255.255.1.10,255.255.1.220] 返回一条记录
}
}
}
}
GET /range_index/_search
{
"query": {
"range" : {
"date_range_test" : {
"gte" : "2015-10-15",
"lte" : "2015-12-15",
"relation":"WITHIN" //[2015-11-01,2015-11-30]在[2015-10-15,2015-12-15]之内,返回一条记录
}
}
}
}
3.5.Regexp Query
返回词项匹配查询正则表达式的文档。
参数:
顶层参数:field想要查询的字段。
field的参数:
1.value:想要查询的正则表达式。默认正则表达式限制在1000个字符,可以通过index.max_regex_length改变该值。
2.flags:可以使用flag参数让正则查询能够使用除标准正则表达式外可选的正则表达式符号。使用多个正则表达式符号,使用|分割;flag的值:ALL-可以使用所有的操作符,COMPLEMENT-可以使用~符号,~表示非操作;INTERVAL-可以使用<>符号,表示匹配一个数值的范围;INTERSECTION:可以使用&符号,表示与操作;ANYSTRING-可以使用@符号,表示匹配整个字符串。
3.max_determinized_states:确定一个查询需要的最大的自动机的数量。使用此参数防止查询中消耗太多资源,当有复杂正则表达式时需要增加这个数量。
4.rewrite:重写查询的方法。
3.6.Term Query
返回字段值中准确包含查询词项的文档。
参数:
顶层参数:field想要查询的字段。
1.value:想要在field字段中查询到的值。查询值必须准确匹配文档中字段的值。
2.boost:用于增加或减少查询的相关度评分。
GET /test/_search
{
"query": {
"term": {
"body": {
"value": "fox"
}
}
}
}
注:避免使用term查询查询text类型的字段,因为默认情况下,es分析器会改变text类型字段的值,如标准分析器将会对text类型字段进行如下的改动:
1).去除大部分的标点符号
2).将内容分割为不同的分词
3).将分词最小化
所以搜索text类型字段时,推荐使用match query,match query会将在查询之前会将查询内容进行分析,可以较好的匹配经过分析后的text类型字段的内容。
3.7.Terms Query
返回字段值中包含一个或多个准确词项的文档。
参数:
1.field:想要查询的字段,该参数的值是想要搜索的词项的数组。默认es限制最大可以查询65,536个词,可以通过index.max_terms_count设置该限制。
2.boost:用于增加或减少查询的相关度评分。
Terms lookup:
Terms lookup提取某个文档的字段值,作为查询的词项数组,适合于搜索词项数组很大的情况;mapping的_source必须设置为enabled:true。
Terms lookup的参数:
1.index:提取字段值的索引。
2.ID:想要提取字段值的文档的ID。
3.path:提取值的字段。ES使用这个值去做terms query。
4.rounting:如果文档索引时有routing值,那么抓取文档值时需要提供routing value,去定位文档位置。
GET my_index/_search?pretty
{
"query": {
"terms": {
"color" : {
"index" : "my_index",
"id" : "2", //提取文档id为2的color字段的值,将其作为term query的查询值去搜索
"path" : "color"
}
}
}
}
3.8.Terms Set Query
Terms Set Query和terms query类似,但是Terms Set Query可以定义放回的文档需要有多少个匹配的词项。
大多数情况下,terms set query需要在索引中包含一个数值型的字段,这个数值型的字段存放返回文档需要匹配的词项数。
参数:
顶层参数:field想要查询的字段。
field的参数:
1.terms:想要在field字段中查找到的词项数组,词项必须和文档字段内容精确匹配。
2.minimum_should_match_field:指定文档返回需要匹配的词项数量的字段。
3.minimum_should_match_script:自定义脚本指定文档返回需要匹配的词项数量。
PUT /job-candidates
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"programming_languages": {
"type": "keyword"
},
"required_matches": { //存放返回文档需要匹配的词项数
"type": "long"
}
}
}
}
PUT /job-candidates/_doc/1?refresh
{
"name": "Jane Smith",
"programming_languages": ["c++", "java"],
"required_matches": 2 //返回该文档需要匹配两个词项
}
GET /job-candidates/_search
{
"query": {
"terms_set": {
"programming_languages": {
"terms": ["c++", "java", "php"],
"minimum_should_match_field": "required_matches"
}
}
}
}
3.9.Wildcard Query
返回内容匹配查询通配符的文档。
参数:
顶层参数:field想要查询的字段。
field的参数:
1.value:用来匹配field字段值的通配符表达式。支持两种通配符:?匹配一个任意的字符,*匹配0个或多个任意字符。
2.boost。
3.rewrite。
