Kafka与Spark的集成
在本章中,我们将讨论如何将Apache Kafka与Spark Streaming API集成.
关于 Spark
Spark Streaming API支持实时数据流的可扩展,高吞吐量,容错流处理.数据可以从注入Kafka,Flume,Twitter等许多源中提取,并且可以使用复杂的算法来处理.例如地图,缩小,连接和窗口等高级功能.最后,处理的数据可以推送到文件系统,数据库和活动仪表板.弹性分布式数据及(RDD)是Spark的基本数据结构.它是一个不可变的分布式对象集合.RDD中的每个数据集划分为逻辑分区,可以在集群的不同节点上计算.
与Spark集成
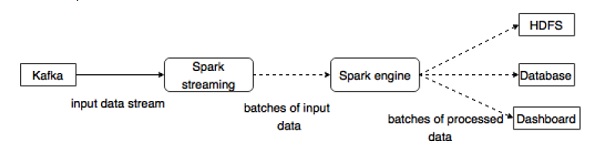
Kafka是Spark流式传输的潜在消息传递和集成平台.Kafka充当实时数据流的中心枢纽.并使用Spark Streaming中的复杂算法进行处理.一旦数据被处理,Spark Streaming可以将结果发布到另一个Kafka主题或存储在HDFS,数据库或仪表板中,下图描述概念流程.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号