1.过拟合(over-fitting)问题
到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过度拟合(over-fitting)的问题,可能会导致它们效果很差。
下面通过两个例子来解释什么过度拟合问题:
例1:这是一个回归问题的例子。
![在这里插入图片描述]()
- 第一个模型是一个线性模型,欠拟合(under-fitting)(或者说“高偏差”(“High bias”)),不能很好地适应我们的训练集;
- 第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合(或者说“高方差”(“High variance”)),虽然能非常好地适应我们的训练集,但在新输入变量进行预测时可能会效果不好;
- 中间的模型似乎最合适;
例2:这是一个分类问题的例子。
![在这里插入图片描述]()
就以多项式理解,x 的次数越高,拟合的越好,但相应的预测的能力就可能变差。
我们来总结一下什么是过拟合问题:如果我们有非常多的特征(特征少的时候可以通过现有特征构造新特征),我们通过学习得到的假设可能能够非常好地适应训练集(代价函数可能几乎为 0(J(θ)≈0)),但是可能无法泛化到新样本。(泛化:指一个假设模型应用到新样本的能力。)
问题是,如果我们发现了过拟合问题,应该如何处理?
解决过拟合问题方法:
1.丢弃一些不能帮助我们正确预测的特征:
- 可以手工选择保留哪些特征
- 用模型选择算法(Model selection algorithm)帮忙(如PCA)
2.正则化(Regularization):
保留所有的特征,但减少梯度(magnitude)或模型参数θj的大小
2.正则化线性回归(Regularized linear regression)
2.1 正则化线性回归的代价函数
上面的回归问题中如果我们的模型是:
hθ(x)=θ0+θ1x1+θ2x22+θ3x33+θ4x44我们可以从之前的事例中看出,正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于 0 的话,我们就能很好的拟合了。
所以我们要做的就是在一定程度上减小这些参数 θ 的值,这就是正则化的基本方法。
假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度。这样的结果是最终得到了一个较为简单的能防止过拟合问题的假设函数(这里是正则化线性回归的代价函数):
J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λ∗∗j=1∗∗∑nθj2]
其中,λ∑j=1nθj2称为正则化项,λ称为正则化参数(regularization parameter)
总的来说,加入正则化项,可以使我们最终得到一个相对简单的假设模型(“Simpler” hypothesis)。
还是以假设函数hθ(x)=θ0+θ1x1+θ2x22+θ3x33+θ4x44为例,若λ过大,则θ=⎣⎢⎢⎢⎡θ1θ2⋮θn⎦⎥⎥⎥⎤→0,进而hθ(x)→θ0,模型欠拟合。
故为了让正则化起到应有的效果,要选择一个合适的λ。
2.2 正则化线性回归的梯度下降法
梯度下降法的更新公式:
Repeat until convergence{
θ0=θ0−αm1∑i=1m(hθ(x(i))−y(i))x0(i)
θj=θj−α[m1∑i=1m(hθ(x(i))−y(i))xj(i)+mλθj],(j=1,2,…n)
}
对更新公式进行合并整理之后,有:
Repeat until convergence{
θ0=θ0−αm1∑i=1m(hθ(x(i))−y(i))x0(i)
θj=θj(1−αmλ)−αm1∑i=1m(hθ(x(i))−y(i))xj(i),(j=1,2,…n)
}
其中,(1−αmλ)是一个比1略小一点点的数,比如0.99。
2.3 正则化线性回归的正规方程
2.3.1 正则化线性回归的正规方程表示
优化目标:minθJ(θ)
![在这里插入图片描述]()
其中的矩阵是一个(n+1)*(n+1)的矩阵。
2.3.2 正规方程中的不可逆(Non-invertibility)问题(选学)
在多变量线性回归中讲过,假如m≤n,θ=(XTX)−1XTy 中XTX不可逆。
现在在J(θ)中加入正则化项之后,如果λ>0,![在这里插入图片描述]() 中要求逆的矩阵一定是可逆的。
中要求逆的矩阵一定是可逆的。
3.正则化逻辑回归(Regularized logistic regression)
3.1 正则化逻辑回归的代价函数
J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+2mλ∗∗j=1∗∗∑nθj2
3.2 正则化逻辑回归的梯度下降法
梯度下降法的更新规则:
Repeat until convergence{
θ0=θ0−αm1∑i=1m(hθ(x(i))−y(i))x0(i)
θj=θj−α[(m1∑i=1m(hθ(x(i))−y(i))xj(i))+mλθj],(j=1,2,…n)
}
需要注意的三点:
- 虽然这里的的梯度下降和正则化的线性回归中的表达式表面上“看起来”一样,但由于两者的假设函数hθ(x)不同,所以还是有很大差别。 这里的假设函数hθ(x)=1+e−θTx1
- 上述更新规则中,方括号里面的项为∂θj∂J(θ),J(θ)为正则化代价函数
- θ0不参与其中的任何一个正则化
3.3 如何在高级优化算法中使用正则化
在逻辑回归模型的文章中我们提到了,使用优化算法时,那么我们需要做的是编写代码,当输入参数 θ 时,它们会计算出两样东西:
- J(θ)
- ∂θj∂J(θ)(for j=0,1,2,...,n+1)
完成上述编码之后,就可以用梯度下降法或者共轭梯度法、BFGS、L-BFGS等高级优化算法来拟合模型参数θ了。
下图为在Octave中使用fminunc(这一算法的作用是求函数在无约束条件下的最小值)这一高级优化算法来拟合模型参数θ的伪代码:
![在这里插入图片描述]()



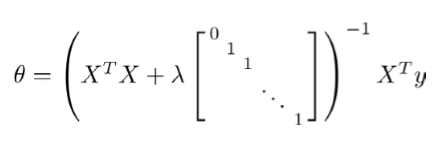
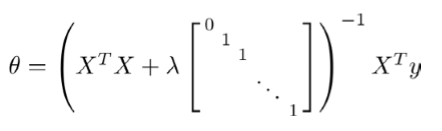 中要求逆的矩阵一定是可逆的。
中要求逆的矩阵一定是可逆的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号