文献阅读速记 - CCVAE for Predicting Multi-Path Trajectories in Mixed Traffic
Cheng H , Yang W L M Y , Sester M , et al. Context Conditional Variational Autoencoder for Predicting Multi-Path Trajectories in Mixed Traffic[J]. 2020.
简介
文章不同于SGAN、Sophie、Social-BiGAT等基于GAN网络的模型,使用了带条件的变分自编码器用于实现对轨迹多样性的预测,此外,还在交互编码方案、采样与反向传播的矛盾、采样的筛选方案等方面做了比较细致的创新,为在相关领域后续研究调优提供有效思路。
下图为整个模型的结构,由两个Encoder和一个Decoder组成,两个Encoder分别对应已知轨迹信息——X和未知轨迹信息Y。
- 在训练时,两个Encoder编码得到的轨迹信息传给Random Variables全连接层,用以生成潜码的分布参数,Decoder接受来自EncoderA和Random Variables采样得到的潜在码z,做进一步的轨迹预测。
- 在推理时,模型中灰色部分的内容将被移除,Decoder将接受EncoderA和在先验分布上采样得到的潜在码z,做出轨迹预测,并且模型经过训练后隐式地学习了P(Y|X, z)分布,因而控制潜在码的采样可生成多种可行的轨迹。
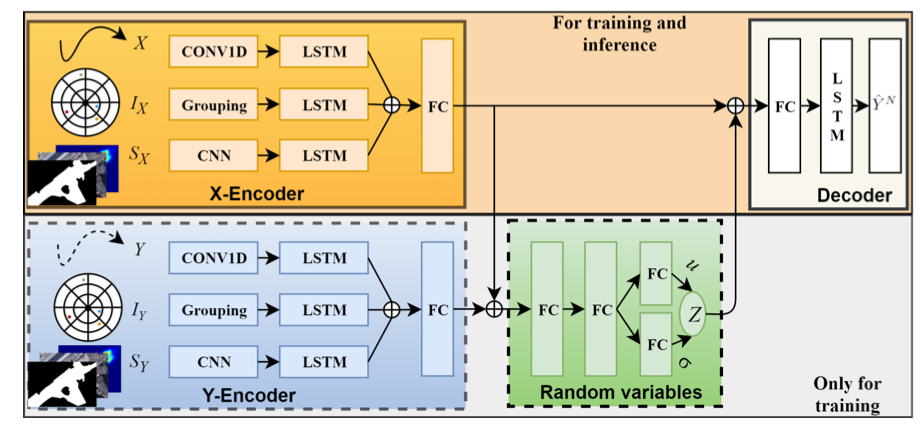
[主要] 有条件的变分自编码器(CCVAE)
此小节涉及较多自编码器原理性的推导,其主要方法引自下述的文章中的教程,由于还在研究不便深入讨论,在此仅作该文献表面上的解读。
Doersch C . Tutorial on Variational Autoencoders[J]. 2016.
鉴于很难刻画出潜编码与已知轨迹X和未知轨迹Y的分布情况P(z|X, Y),模型引入变分估计,将P(z|X, Y)简化为均值与方差已知的高斯分布,训练模型预测假定分布情况后的后验分布 - Q(z|X, Y),并隐式地从轨迹X和Y中建立与预置分布的联系。
存在推到得到的公式:\(logP(Y|X) \ge -KL(Q(z|Y, X) || P(z)) + E_{Q(z|Y, X)}[logP(Y | z, X)]\)
其中:
- 第一项是用于刻画训练后的模型,对于给定的轨迹X,有多大置信度能够预测好。
- 第二项是KL散度(不包含符号),用于衡量两个分布之间的差异程度,值越小则差异越小。
- 第三项是在模型在潜编码z满足的后验分布中预测置信度的期望。
模型设立的目标函数是由不等式右边两项形成的,落实到具体便是KL散度损失值(两个高斯分布容易求出)+L2预测距离的损失值(形式上改变了第三项,不再使用概率),当二者都尽量大后,第一项的下界自然抬升,预测的准确性就上升了。
💡 思考:上述公式中,其实第一项就是最普通的序列模型所用目标函数,但CCVAE模型并不直接使用,粗略地设计了分布形式,并用两个新的项去逼近原目标函数的下界,这样和原目标函数相比损失了“准确性”,而这损失中所含有的不确定性恰恰就是模型所需要的,用以形成多样化的结果。
团队识别与交互编码
和Social LSTM和SS LSTM类似,模型用了圆形的Social Tensor的方法编码目标单位的交互情况,但差异在于,在将周围目标纳入Social Tensor时,新增了筛选目标 —— 团队,模型运用了一个很经典的方法根据一段时间内方位的变化识别团队:
- 当为团队时:Social Tensor不纳入该行人。
- 当不是团队时:Social Tensor纳入该行人。
兼顾采样操作和反向传播
在SGAN文中特意提到了选择预测二维空间节点的原因是因为GAN网络中不可避免地设计到采样操作,而该操作不可微。这篇文章在这个点上找到的新的解决方案re-parameterization,相比于潜码z在\(z \sim N(\mu, \sigma)\)直接采样,本文中的\(z = \mu + \sigma \odot \epsilon\),其中\(\epsilon\)满足高斯分布,但对于在传播中可以理解为常数,避免采样问题。

采样结果筛选
虽然模型预测输出为二维坐标点,但在后期使用了高斯分布的假设用以筛选出最佳/最N佳的轨迹用以实验评估,具体来说,就是对于一个目标在一个时刻的多次预测按随机变量采样的原理拟合高斯分布,按照似然进行排序。
Question:
- 用学习方法替代人工规则,进行团队的识别?
- 对于这个模型解决多样性的思路,在高斯分布上采集潜码用以生成多条轨迹,再将轨迹拟合高斯分布;social lstm,只输入原始轨迹,预测高斯分布参数。这两者最后都落脚于高斯分布,前者的复杂性是否有意义?
- 最终采样结果进行高斯分布的排序时,用的是绝对位置还是相对位置?若是绝对的,属于已经拼接的结果,在用高斯分布在独立性上得不到保证;若是相对的,每一步最大似然的预测不一定是整体上最佳的,因为收前面偏移的影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号