Architecture of GPU and CUDA
In this blog, we will introduce the architecture of GPU from the programmers' perspective, and give some examples of CUDA programming. From more details, you should read CUDA Guide - Nvidia.
Intro
In this section, the architecture of GPU will be introduced from two perspective, hardware and software.
Hardware
Compared with CPU, GPU is specialized for highly parallel computations and therefore designed such that more transistors are devoted to data processing rather than data caching and flow control.
- GPU devotes more transistors to data processing, e.g., floating-point computations, is beneficial for highly parallel computations;
- GPU can hide memory access latencies with computation, instead of relying on large data caches and complex flow control to avoid long memory access latencies, both of which are expensive in terms of transistors.
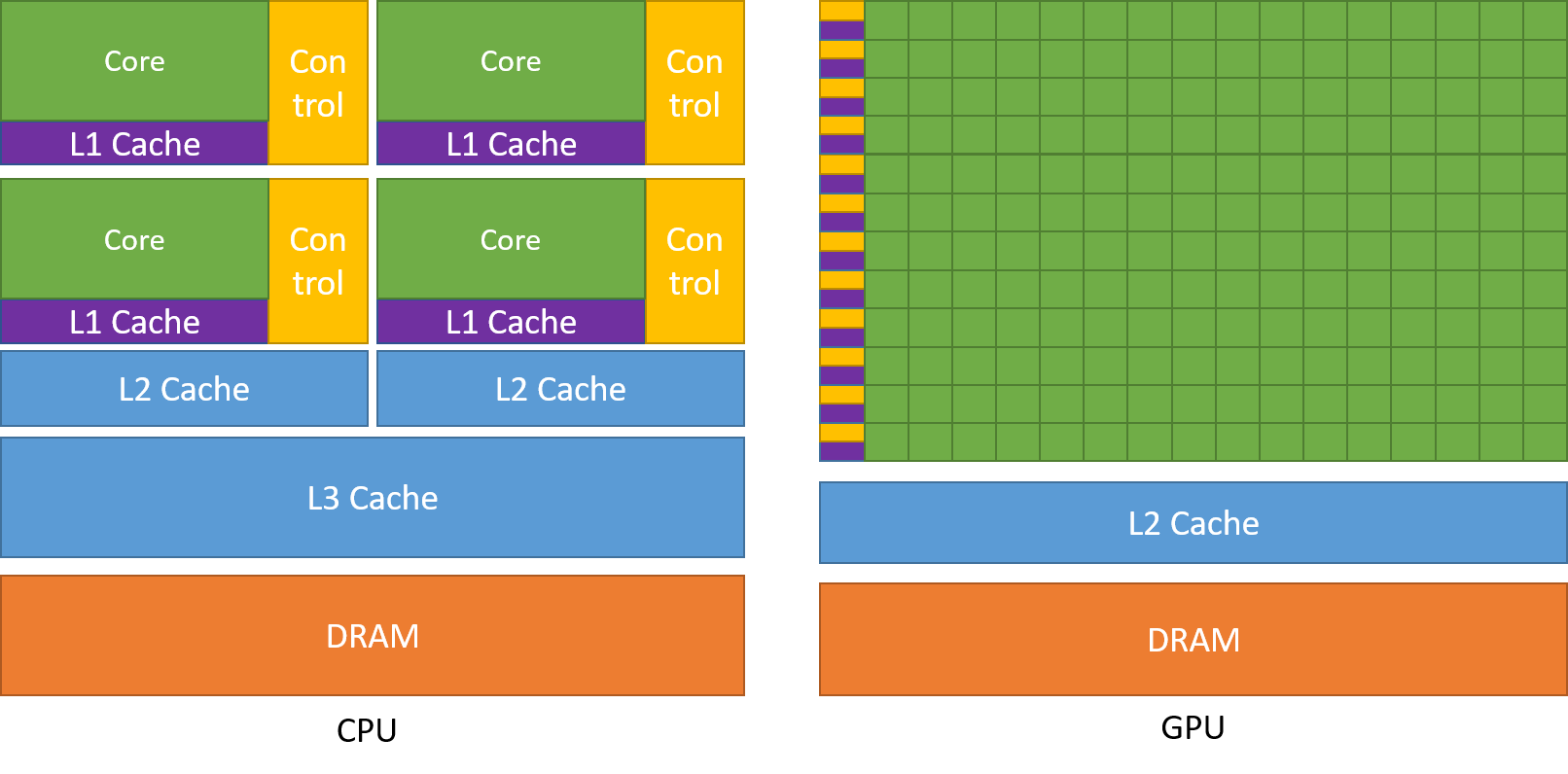
From the perspective of hardware, there are some key words we need to know.
- SP (Streaming Processor/Streaming Core) - It's similar to a scalar core in CPU. One thread will run on one SP.
- SM (Streaming Multiprocessor) - A SM contains one fetch-decode-unit, multiple SPs (execution units), multiple groups of registers, and cache.
- It is very similar to CPU. As we know, one physical CPU contains multiple core. One CPU core can execute multiple threads.
- One physical contains multiple SMs, and one SM can execute multiple GPU-threads.
- Device - "Device" usually refers to a physical GPU on the machine.
ls /dev/nvidia*, you will see/dev/nvidia0, /dev/nvidia1, ..., that represents to the physical GPU.

Software
From the perspective of software, there are 4 key concepts:
- Grid, block, and thread
- From the perspective of programmer, we can group the threads into 2D shape (3D shape is okay if you want).
- e.g. define
gird = (2x3)andblock = (4x5),grid[i, j]denotes one block,block[i, j]denotes one thread. So there are20 x 6 = 120threads. - See the figure as follows.
- Warp - A group of 32 threads in thread block is called a warp.
- Warp is the unit of GPU scheduler. For each scheduling, it will put some warps into SMs.
- Suppose I have 1024 threads per block (i.e. 32 warps). Most GPUs (excepting Turing) allow a hardware limit of 64 warps per SM, as well as 2048 threads per SM (these are consistent).
- One block can be executed on different SMs at the same time, since it may contains multiple warps. See the figure as follows.
We can have the conclusion that "gird > block > warp > thread".
| Grid, block and thread | Scheduler on SMs |
|---|---|
 |
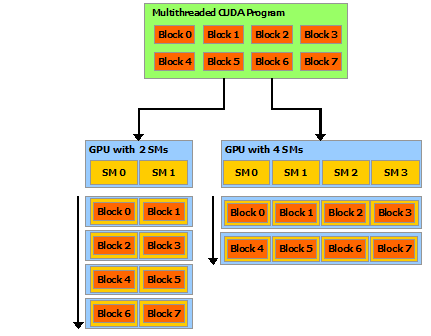 |
Example: Nvidia V100

Programming Model
At its core are three key abstractions:
- a hierarchy of thread groups,
- shared memories, and
- barrier synchronization - that are simply exposed to the programmer as a minimal set of language extensions.
Memory Hierarchy
- Each thread has private local memory.
- Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block.
- All threads have access to the same global memory.
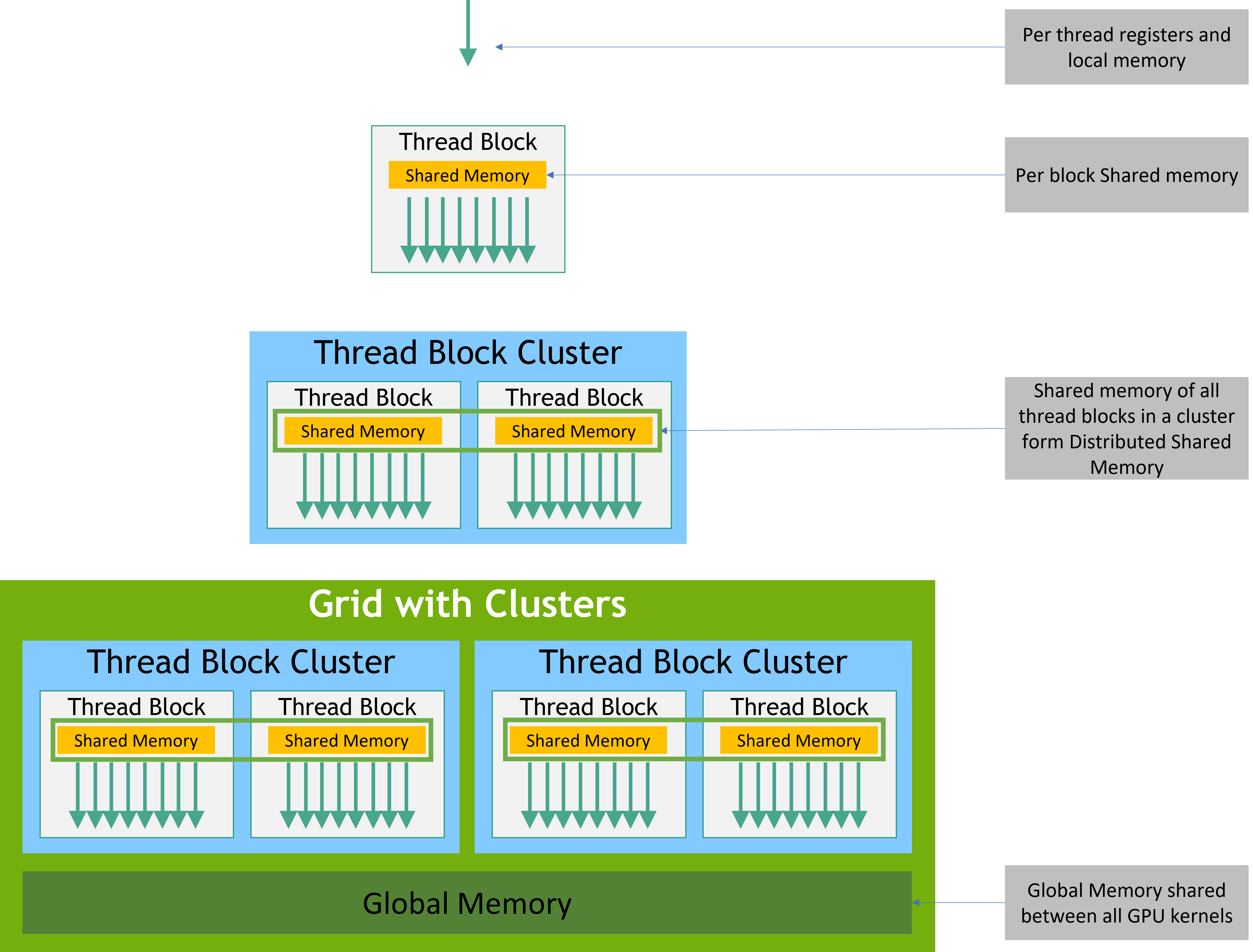
We will introduce this in details by some examples in the latter blogs.
Thread Hierarchy
The index of a thread and its thread ID relate to each other in a straightforward way:
- For a one-dimensional block, they are the same;
- For a two-dimensional block of size
(Dx, Dy),the thread ID of a thread of index(x, y)is(x + y * Dx); it's similar to a two-dimension-array. - For a three-dimensional block of size
(Dx, Dy, Dz), the thread ID of a thread of index(x, y, z)is(x + y * Dx + z * Dx * Dy).
As an example, the following code adds two matrices A and B of size N x N and stores the result into matrix C:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
There is a limit to the number of threads per block, since all threads of a block are expected to reside on the same processor core and must share the limited memory resources of that core. On current GPUs, a thread block may contain up to 1024 threads.
Host and Device
There are two roles in CUDA program, host and device.
- "Host" denote the thread running in CPU environment. It usually refers to the
mainthread. - "Device" denote those threads running on GPU cores.
These two types of threads are parallelized, the host will NOT wait for device to finish its job. If we want to let host wait for device to finish the kernel functions, cudaDeviceSynchronize should be called in host code.
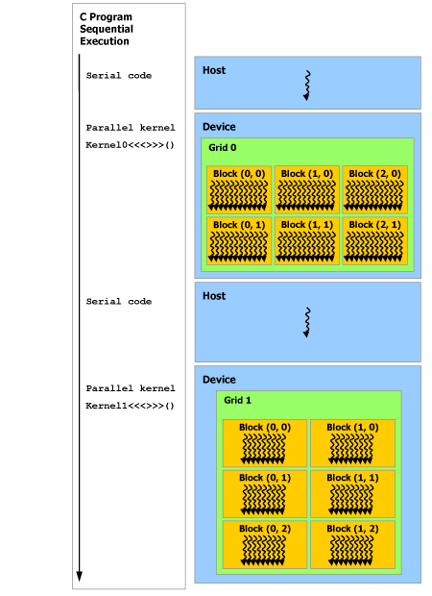
Example: Vector Addition
Here is some naive examples of CUDA. Generally speaking, there are usually 3 steps to write a CUDA program.
- Copy data from host-memory to device-memory.
- Execute
__global__declared funtions on GPU. - Copy data from device-memory to host-memory.
Here is an example of vector addition.
/* Add two vectors: C = A + B */
#include <cuda_runtime.h>
#include <cstdio>
#include <cassert>
__global__ void VectorAdd(float *da, float *db, float *dc, int N)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N)
dc[idx] = da[idx] + db[idx];
}
int main()
{
const int N = 1 << 16;
size_t size = N * sizeof(float);
/* memory in host */
float *A = new float[N];
float *B = new float[N];
float *C = new float[N];
assert(A != nullptr && B != nullptr && C != nullptr);
/* initialization */
for (int i = 0; i < N; ++i)
{
A[i] = rand() / (float)RAND_MAX;
B[i] = rand() / (float)RAND_MAX;
}
/* memory in GPU device, 'd' means device */
float *da = nullptr, *db = nullptr, *dc = nullptr;
assert(cudaMalloc(&da, size) == cudaSuccess);
assert(cudaMalloc(&db, size) == cudaSuccess);
assert(cudaMalloc(&dc, size) == cudaSuccess);
/* memory copy from host to device */
assert(cudaMemcpy(da, A, size, cudaMemcpyHostToDevice) == cudaSuccess);
assert(cudaMemcpy(db, B, size, cudaMemcpyHostToDevice) == cudaSuccess);
/* blockSize is the number of threads per block, 1D-block */
int blockSize = 512;
/* number of blocks per grid, 1D-grid */
int numBlocks = (N + blockSize - 1) / blockSize;
printf("blockSize = %d, numBlocks = %d \n", blockSize, numBlocks);
/* package in dim3 */
dim3 gridDim(numBlocks, 1);
dim3 blockDim(blockSize, 1);
/* execute worker-threads on GPU */
VectorAdd<<<gridDim, blockDim>>>(da, db, dc, N);
/* check validity */
cudaDeviceSynchronize();
assert(cudaMemcpy(C, dc, size, cudaMemcpyDeviceToHost) == cudaSuccess);
for (int i = 0; i < N; ++i)
{
printf("%d: %f + %f = %f \n", i, A[i], B[i], C[i]);
assert(fabs(A[i] + B[i] - C[i]) < 1e-6);
}
/* free resource */
free(A), free(B), free(C);
cudaFree(da), cudaFree(db), cudaFree(dc);
/* reset cuda device */
cudaDeviceReset();
}

