
十一月*项目记录--统计项目问题分析
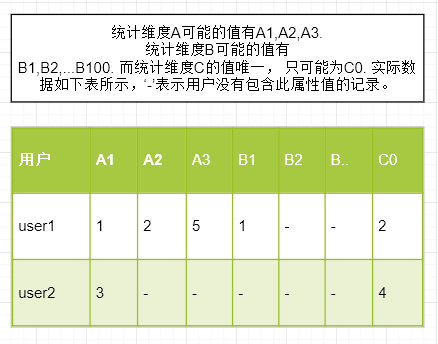
之前的工作总结里面有说到采集数据,那么数据采集过来之后自然也就进入到了统计的阶段。接手之前呢觉得统计应该还挺简单的,无非就是把sql统计出来的结果展示出来。后来发现要处理的细节还是比较多的。先说下业务场景,因为项目中第一个要统计的报表维度非常多,比如境外号码,AJ性质,种类,手段等等,这其中有的字段的值很少甚至唯一,有的值甚至会多达上百个,而且用户可选择的统计维度是不固定的(有可能增加),所以无法设计一张统计表来记录统计的结果, 如图所示1.1。
1.1问题描述
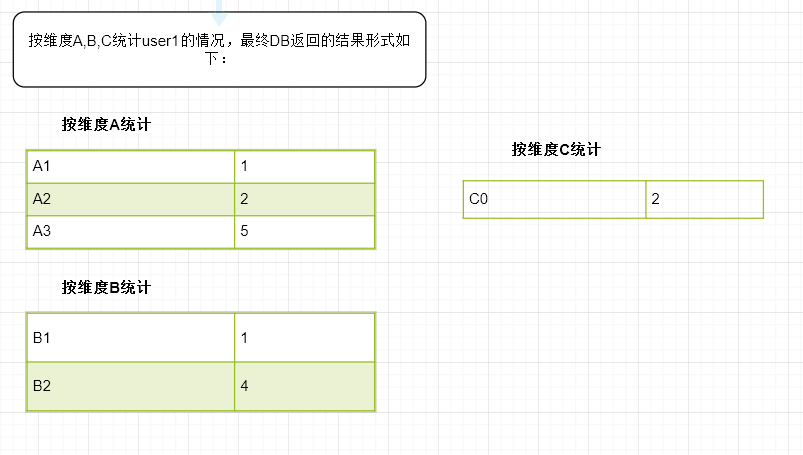
表1.1展示出来的是统计数据的实际情况,但是对于sql来说,我们一次只能按一个用户去统计,而且最后group by后,没有值的字段不会有对应的值,也不会有用户列, 结果大致如下,并且我们一次只能统计单个维度。
1.2问题描述
这种情况下,就带来了下面这些问题。
1.不同的统计维度返回的结果是不一样的, 该如何用统一的数据结构来描述所有的统计结果。同样的,user1和user2返回的结果也不一样,也需要整合后放在一起。
2.确定统计结果的表头,如果单纯统计user1,那么结果的表头应当至少包含(userName, A1,A2,A3,B1,C0), 这里为什么说至少呢,因为对于统计维度B, 还有B2-B100都没有展示,因为user1没有包含这些值的记录;对于这些记录的值,真是食之无味弃之可惜,不展示吧,客户可能觉得你没有统计它们;展示吧,弊端也很明显,这些字段的统计值全部都为零,一百列,99列为0, 展示在页面上用户看了很有可能也会觉得没必要。所以这里确定表头大致分为两种思路:
a.从缓存的字典中获取维度可能值的全集。这种方式适用于统计维度可能的值不是很多的情况。比如按维度A统计,A的值可能只有3种,那么就将这3种值全部列出,没有对应数据的统计主体做补零处理。
b.依据统计出的结果数据确定全集。这种方式是在统计过程中将结果属性用一个set记录下来,然后结果表头只包含set中含有的表头,一句话就是结果有哪些,就展示哪些。
3.统计结果依据表头补零。这个问题很直观了,再确定表头后,比如对于(userName, A1,A2,A3,B1,C0),那么user2不包含A2,A3,B1的数据,则需要补零后加入到user2的统计结果当中。
描述完问题后来看下解决方案,首先说下比较宏观层面的设计思路:对于这种统计问题,首先要明确的是,不管什么样的统计维度,结果一定会包含对应的统计结果表头信息和结果数据信息。但是不同的统计维度,他们返回的表头和数据可能做的处理是不一样的, 比如有的表头需要从字典中获取全集,有的是根据统计结果确定,有的需要进行翻译,有的直接就是中文。考虑到这些问题,应该将统计维度分类处理,这个比较直观的分类依据就是sql, 类似的统计维度,都会是针对相同的表操作(不一定是一张表),往往它们只是换了一个统计字段,那么这种情况就可以用一个统一的Service去实现这类维度的统计,建议不同类别的统计维度有自己的Service, 这样会比较利于维护和扩展。 其次就是,把表头和表数据做了分离的获取。 这里主要是因为结果统计需要汇总,如果表头和数据信息都放在一起,那么会增加汇总的难度,而且部分统计维度的表头需要再统计数据完成后才能确定。所以的一个方案是,把单个维度的统计结果定为最终结果子集,包括表头子结果集以及表数据子结果集。
有了上述的铺垫后,再来看看如何解决对应的问题,
对于问题1,这个问题比较简单,统计的最终结果一定是包含user信息,和对应的记录信息的,所以这里用的是Map<String, JSONObject>的形式,String表示对应user, JSONObject描述统计字段的code和值;当然用Map<String, Map<String, Integer>>也是类似的,但是个人觉得没有前一种直观。这里要注意的是,JSONObject是在所有的统计维度完成后,根据所有的子结果集生成的,子结果集的描述同样也是Map<String, JSONObject>.
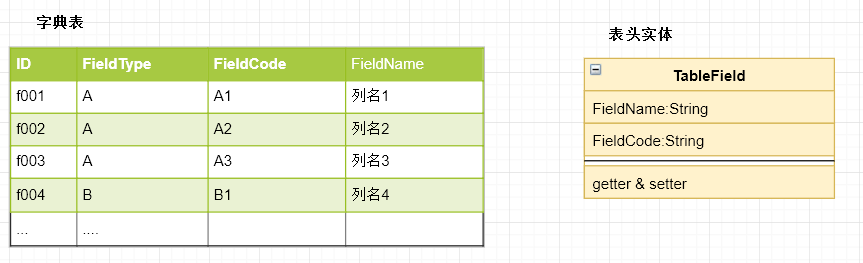
对于问题2, 其实在有了表头和数据分开获取的设计后,问题2也比较好解决了,这里说下字典表的设计以及表头的实体类设计吧。
2.1 字典表设计以及表头实体类设计
这里字典表主要有两个用途:1.获取某个统计维度可能值的全集。2.翻译统计字段。 对于实体表头的设计,也很简单,无非就是表字段名称,和字段代码, 这里采用FieldType_FieldCode的形式来形成唯一的表头代码。例如,{FieldCode:“A_A1”, FieldName:“ 列名1”}。针对上面说到的两种表头获取方式,因为每个统计维度有自己的Service,调用时,只需要传入对应的ServiceBean的名称,然后从spring容器中获取相应的bean再调用相应的方法就OK了, 设计如图2.2。 对于之前说到的表头获取方式,我把两种方式做了结合。举例来说就是对于A维度的统计,结果中会包含A1,A2,A3. 但是对于B维度的统计,结果中只会包含B1。 这样两种方式都实现的话,之后阶段性验收也可以供用户选择切换。

2.2统计Service设计
3.结果补零的话,基本思路就是依据最终的表头结合,以及每个用户的结果表头结合做差集,结果就是缺失的字段,把这些字段的值设置成0,加入到对应用户的统计结果就行了。
项目还有很多值得优化的地方,后续还会持续更新。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号