

之前的工作总结还是写了太多文字了,可能在必要的地方加点图会比较好,所以之后的博客会注意。
1.上一篇文章说到的处理多数据源的问题,虽然用注解的方式切换数据源会十分的方便,但是在实际应用过程中,一个同事发现切换数据源的时间成本相当高,在实际的数据采集过程当中可能切换的比较频繁,所以后来是用了一种新的架构来采集数据,架构设计如下所示:
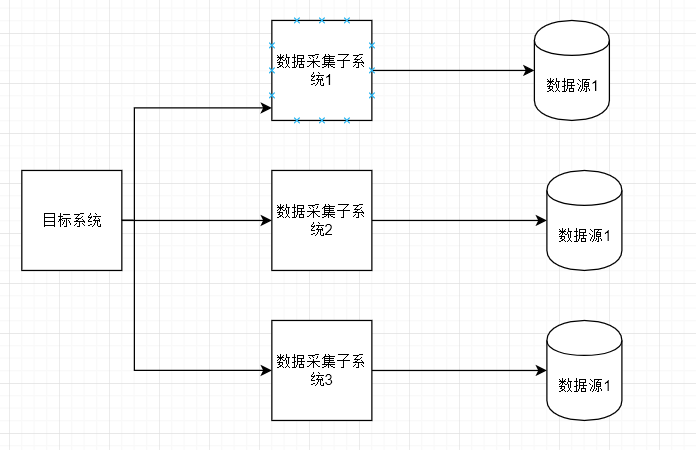
也就是将不同的数据采集系统分离开来,让他们去采集各自的数据源,然后将采集到的结果返回给目标系统,然后目标系统再做入库处理。这样设计的好处有如下几点
a.解决了数据源切换的问题,个子系统独立采集
b.每个采集系统互不影响,一个fail掉了,其它的还可以继续采集。
不好的地方在于:
a.增加了系统的复杂度,系统通信也会增加额外的延时
b.增加了调试的成本
但是我个人也觉得还是这种设计会比较清晰,之后增加新的数据源也只要增加一个子系统就行了。这里虽说是子系统,但是因为只是采集数据,所以业务逻辑是非常简单的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号