理解Mysql prepare预处理语句
MySQL 5.1对服务器一方的预制语句提供支持。如果您使用合适的客户端编程界面,则这种支持可以发挥在MySQL 4.1中实施的高效客户端/服务器二进制协议的优势。候选界面包括MySQL C API客户端库(用于C程序)、MySQL Connector/J(用于Java程序)和MySQL Connector/NET。例如,C API可以提供一套能组成预制语句API的函数调用。其它语言界面可以对使用了二进制协议(通过在C客户端库中链接)的预制语句提供支持。对预制语句,还有一个SQL界面可以利用。与在整个预制语句API中使用二进制协议相比,本界面效率没有那么高,但是它不要求编程,因为在SQL层级,可以直接利用本界面:
· 当您无法利用编程界面时,您可以使用本界面。
· 有些程序允许您发送SQL语句到将被执行的服务器中,比如mysql客户端程序。您可以从这些程序中使用本界面。
· 即使客户端正在使用旧版本的客户端库,您也可以使用本界面。唯一的要求是,您能够连接到一个支持预制语句SQL语法的服务器上。
预制语句的SQL语法在以下情况下使用:
· 在编代码前,您想要测试预制语句在您的应用程序中运行得如何。或者也许一个应用程序在执行预制语句时有问题,您想要确定问题是什么。
· 您想要创建一个测试案例,该案例描述了您使用预制语句时出现的问题,以便您编制程序错误报告。
· 您需要使用预制语句,但是您无法使用支持预制语句的编程API。
预制语句的SQL语法基于三个SQL语句:
|
1
2
3
4
5
|
PREPARE stmt_name FROM preparable_stmt; EXECUTE stmt_name [USING @var_name [, @var_name] ...]; {DEALLOCATE | DROP} PREPARE stmt_name; |
PREPARE语句用于预备一个语句,并赋予它名称stmt_name,借此在以后引用该语句。语句名称对案例不敏感。preparable_stmt可以是一个文字字符串,也可以是一个包含了语句文本的用户变量。该文本必须展现一个单一的SQL语句,而不是多个语句。使用本语句,‘?'字符可以被用于制作参数,以指示当您执行查询时,数据值在哪里与查询结合在一起。‘?'字符不应加引号,即使您想要把它们与字符串值结合在一起,也不要加引号。参数制作符只能被用于数据值应该出现的地方,不用于SQL关键词和标识符等。
如果带有此名称的预制语句已经存在,则在新的语言被预备以前,它会被隐含地解除分配。这意味着,如果新语句包含一个错误并且不能被预备,则会返回一个错误,并且不存在带有给定名称语句。
预制语句的范围是客户端会话。在此会话内,语句被创建。其它客户端看不到它。
在预备了一个语句后,您可使用一个EXECUTE语句(该语句引用了预制语句名称)来执行它。如果预制语句包含任何参数制造符,则您必须提供一个列举了用户变量(其中包含要与参数结合的值)的USING子句。参数值只能有用户变量提供,USING子句必须准确地指明用户变量。用户变量的数目与语句中的参数制造符的数量一样多。
您可以多次执行一个给定的预制语句,在每次执行前,把不同的变量传递给它,或把变量设置为不同的值。
要对一个预制语句解除分配,需使用DEALLOCATE PREPARE语句。尝试在解除分配后执行一个预制语句会导致错误。
如果您终止了一个客户端会话,同时没有对以前已预制的语句解除分配,则服务器会自动解除分配。
以下SQL语句可以被用在预制语句中:CREATE TABLE, DELETE, DO, INSERT, REPLACE, SELECT, SET, UPDATE和多数的SHOW语句。目前不支持其它语句。
以下例子显示了预备一个语句的两种方法。该语句用于在给定了两个边的长度时,计算三角形的斜边。
第一个例子显示如何通过使用文字字符串来创建一个预制语句,以提供语句的文本:
|
1
2
3
4
5
6
7
8
9
10
|
mysql> PREPARE stmt1 FROM 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse';mysql> SET @a = 3;mysql> SET @b = 4;mysql> EXECUTE stmt1 USING @a, @b;+------------+| hypotenuse |+------------+| 5 |+------------+mysql> DEALLOCATE PREPARE stmt1; |
第二个例子是相似的,不同的是提供了语句的文本,作为一个用户变量:
|
1
2
3
4
5
6
7
8
9
10
11
|
mysql> SET @s = 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse';mysql> PREPARE stmt2 FROM @s;mysql> SET @a = 6;mysql> SET @b = 8;mysql> EXECUTE stmt2 USING @a, @b;+------------+| hypotenuse |+------------+| 10 |+------------+mysql> DEALLOCATE PREPARE stmt2; |
对于已预备的语句,您可以使用位置保持符。以下语句将从tb1表中返回一行:
|
1
2
3
4
5
|
mysql> SET @a=1;mysql> PREPARE STMT FROM "SELECT * FROM tbl LIMIT ?";mysql> EXECUTE STMT USING @a; |
以下语句将从tb1表中返回第二到第六行:
|
1
2
3
4
5
|
mysql> SET @skip=1; SET @numrows=5;mysql> PREPARE STMT FROM "SELECT * FROM tbl LIMIT ?, ?";mysql> EXECUTE STMT USING @skip, @numrows; |
预制语句的SQL语法不能被用于带嵌套的风格中。也就是说,被传递给PREPARE的语句本身不能是一个PREPARE, EXECUTE或DEALLOCATE PREPARE语句。
预制语句的SQL语法与使用预制语句API调用不同。例如,您不能使用mysql_stmt_prepare() C API函数来预备一个PREPARE, EXECUTE或DEALLOCATE PREPARE语句。
预制语句的SQL语法可以在已存储的过程中使用,但是不能在已存储的函数或触发程序中使用。
以上就是本文的全部内容,希望对大家的学习有所帮助。
MySQL中Stmt 预处理提高效率问题的小研究
在oracle数据库中,有一个变量绑定的用法,很多人都比较熟悉,可以调高数据库效率,应对高并发等,好吧,这其中并不包括我,当同事问我MySQL中有没有类似的写法时,我是很茫然的,于是就上网查,找到了如下一种写法
代码如下:
DELIMITER $$
set @stmt = 'select userid,username from myuser where userid between ? and ?';
prepare s1 from @stmt;
set @s1 = 2;
set @s2 = 100;
execute s1 using @s1,@s2;
deallocate prepare s1;
$$
DELIMITER ;
用这种形式写的查询,可以随意替换参数,给出代码的人称之为预处理,我想这个应该就是MySQL中的变量绑定吧……但是,在查资料的过程中我却听到了两种声音,一种是,MySQL中有类似Oracle变量绑定的写法,但没有其实际作用,也就是只能方便编写,不能提高效率,这种说法在几个09年的帖子中看到:
http://www.itpub.net/thread-1210292-1-1.html
http://cuda.itpub.net/redirect.php?fid=73&tid=1210572&goto=nextnewset
另一种说法是MySQL中的变量绑定是能确实提高效率的,这个是希望有的,那到底有木有,还是自己去试验下吧。
试验是在本机进行的,数据量比较小,具体数字并不具有实际意义,但是,能用来说明一些问题,数据库版本是mysql-5.1.57-win32免安装版。
本着对数据库不是很熟悉的态度^_^,试验过程中走了不少弯路,此文以结论为主,就不列出实验的设计过程,文笔不好,文章写得有点枯燥,写出来是希望有人来拍砖,因为我得出的结论是:预处理在有没有cache的情况下的执行效率都不及直接执行…… 我对自己的实验结果不愿接受。。如果说预处理只为了规范下Query,使cache命中率提高的话个人觉得大材小用了,希望有比较了解的人能指出事实究竟是什么样子的——NewSilen
实验准备
第一个文件NormalQuery.sql
Set profiling=1;
Select * From MyTable where DictID = 100601000004;
Select DictID from MyTable limit 1,100;
Select DictID from MyTable limit 2,100;
/*从limit 1,100 到limit 100,100 此处省略重复代码*/
......
Select DictID from MyTable limit 100,100;
SELECT query_id,seq,STATE,10000*DURATION FROM information_schema.profiling INTO OUTFILE 'd:/NormalResults.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
第二个sql文件 StmtQuery.sql
Set profiling=1;
Select * From MyTable where DictID = 100601000004;
set @stmt = 'Select DictID from MyTable limit ?,?';
prepare s1 from @stmt;
set @s = 100;
set @s1 = 101;
set @s2 = 102;
......
set @s100 =200;
execute s1 using @s1,@s;
execute s1 using @s2,@s;
......
execute s1 using @s100,@s;
SELECT query_id,seq,STATE,10000*DURATION FROM information_schema.profiling INTO OUTFILE 'd:/StmtResults.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
做几点小说明:
1. Set profiling=1; 执行此语句之后,可以从information_schema.profiling这张表中读出语句执行的详细信息,其实包含不少内容,包括我需要的时间信息,这是张临时表,每新开一个会话都要重新设置profiling属性才能从这张表中读取数据
2. Select * From MyTable where DictID = 100601000004;
这行代码貌似和我们的实验没什么关系,本来我也是这么认为的,之所以加这句,是我在之前的摸索中发现,执行过程中有个步骤是open table,如果是第一次打开某张表,那时间是相当长的,所以在执行后面的语句前,我先执行了这行代码打开试验用的表
3. MySQL默认在information_schema.profiling表中保存的查询历史是15条,可以修改profiling_history_size属性来进行调整,我希望他大一些让我能一次取出足够的数据,不过最大值只有100,尽管我调整为150,最后能够查到的也只有100条,不过也够了
4. SQL代码我没有全列出来,因为查询语句差不多,上面代码中用省略号表示了,最后的结果是两个csv文件,个人习惯,你也可以把结果存到数据库进行分析
实验步骤
重启数据库,执行文件NormalQuery.sql,执行文件StmtQuery.sql,得到两个结果文件
再重启数据库,执行StmtQuery.sql,执行文件NormalQuery.sql,得到另外两个结果文件
实验结果
详细结果在最后提供了附件下载,有兴趣的朋友可以看下
结果分析
每一个SQL文件中执行了一百个查询语句,没有重复的查询语句,不存在查询cache,统计执行SQL的平均时间得出如下结果
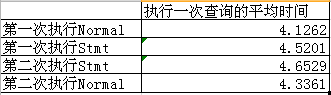
从结果中可以看出,无论是先执行还是后执行,NormalQuery中的语句都比使用预处理语句的要快一些=.=!
那再来看看每一句查询具体的情况,Normal和Stmt的query各执行了两百次,每一步的详细信息如下:
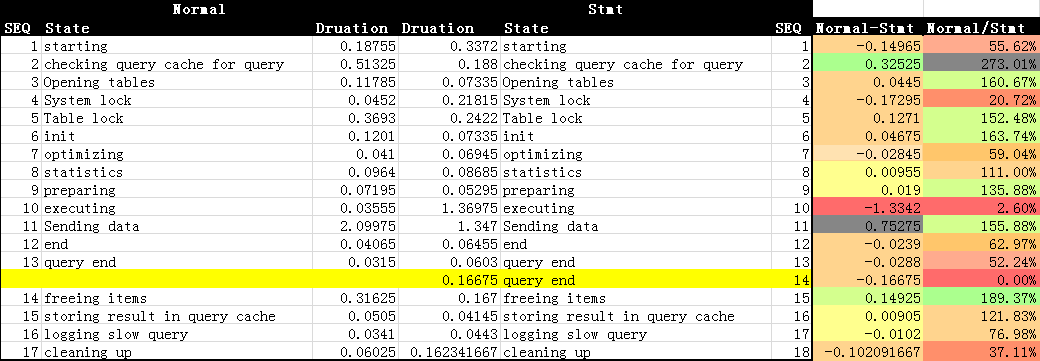
从这里面可以看出,第一个,normalquery比stmtquery少一个步骤,第二个,虽然stmt在不少步骤上是优于normal的,但在executing一步上输掉太多,最后结果上也是落败
最后,再给出一个查询缓存的实验结果,具体步骤就不列了

在查询缓存的时候,Normal完胜……
写在最后
大概情况就是这样,我回忆了一下,网上说预处理可以提高效率的,基本都是用编程的方式去执行查询,不知道这个有没有关系,基础有限,希望园子里的大牛能看到,帮忙解惑
实验结果附件
by simpman

 浙公网安备 33010602011771号
浙公网安备 33010602011771号