SQL Server 查询优化器选错了索引
SQL 是声明性语言,查询语句只是在说明你想要的是什么,具体的查询步骤(执行计划)是由查询优化器决定的。在 SQL Server 中,正常情况下,查询优化器会自动生成足够好的执行计划。但有时却生成了看起来及其蠢的执行计划(用错索引之类的),为什么会出现这种情况呢?本文将给予解答。
足够好是指:当可生成的执行计划有多种时,查询计划不会将所有执行计划都对比一遍,而是找到一个它认为足够好的执行计划后,就不再浪费时间找所谓的最优解了。
可以跳过错误重现部分,直接查看下文红色粗体字结论。
一、重现错误
本文使用的工具是 win10,SQL Server 2017,AdventureWorks2017
1.准备工作
1).给数据库启动账号 Lock Pages in memory 权限
2).添加索引
USE [AdventureWorks2017] GO CREATE NONCLUSTERED INDEX [IX_SalesOrderNumber_AccountNumber] ON [Sales].[SalesOrderHeader] ([SalesOrderNumber],[AccountNumber]) GO GO CREATE NONCLUSTERED INDEX [IX_UnitPrice] ON [Sales].[SalesOrderDetail] ([UnitPrice]) GO
3).开启分析工具
a.打开包括实际执行计划

b.设置部分statistics 为 On
set statistics io on set statistics time on
2.执行语句1
go exec sp_executesql N'select * from Sales.SalesOrderHeader header join Sales.SalesOrderDetail detail on header.SalesOrderID = detail.SalesOrderID where header.SalesOrderNumber like @SalesOrderNumber and header.AccountNumber like @AccountNumber and detail.UnitPrice > @UnitPriceFrom and detail.UnitPrice < @UnitPriceTo', N'@SalesOrderNumber nvarchar(100),@AccountNumber nvarchar(100),@UnitPriceFrom money,@UnitPriceTo money', @SalesOrderNumber = 'SO4366%',@AccountNumber = '10-4020-00051%', @UnitPriceFrom = 0, @UnitPriceTo = 3000 go
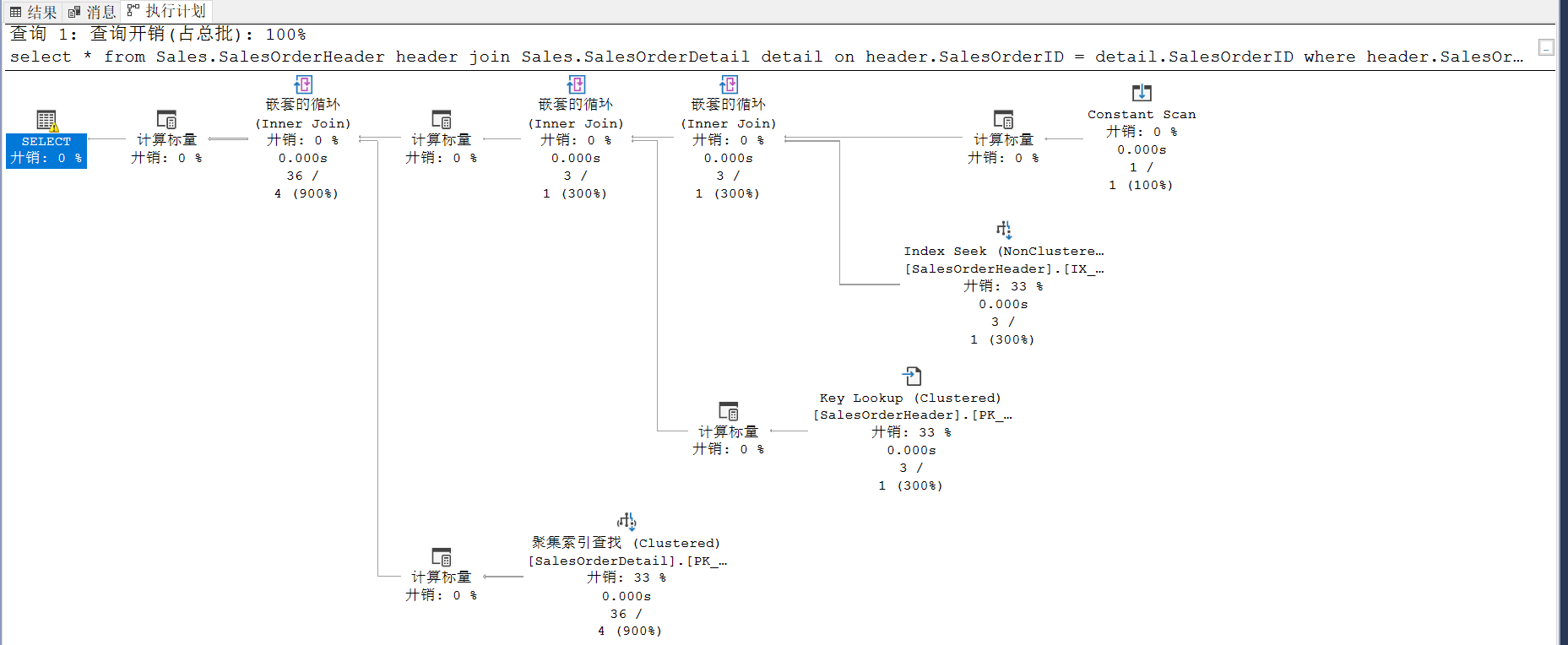
执行计划如下:
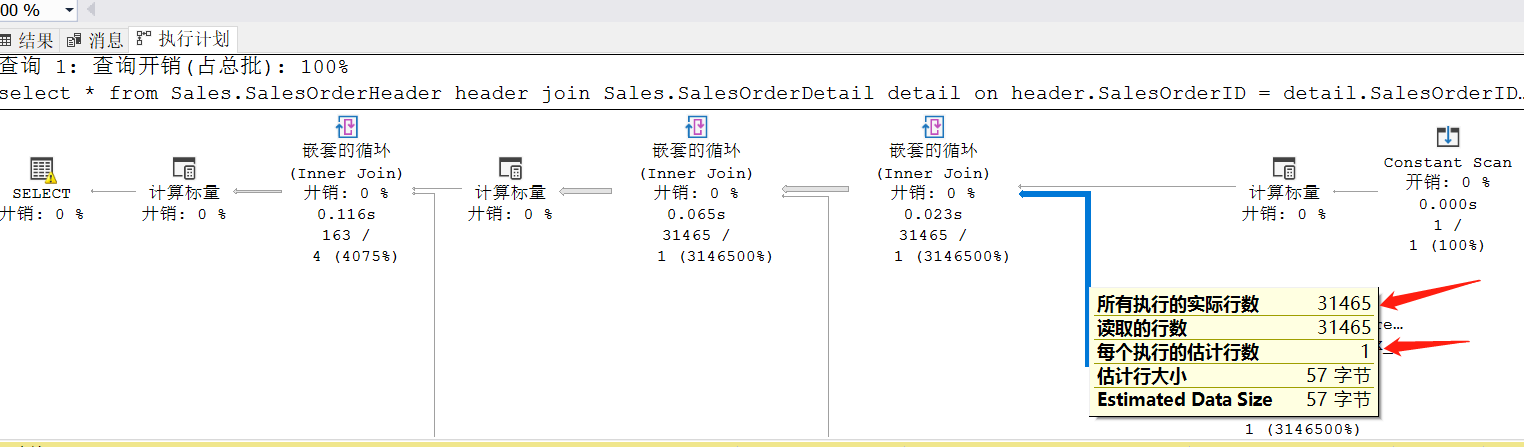
这边使用了 SalesOrderHeader 表的 IX_SalesOrderNumber_AccountNumber 索引,命中3条信息,通过 SalesOrderID join SalesOrderDetail 表,
最终结果是36条。
3.执行语句2
语句2和语句1只是改了参数的值,其余部分都是一样的
go exec sp_executesql N'select * from Sales.SalesOrderHeader header join Sales.SalesOrderDetail detail on header.SalesOrderID = detail.SalesOrderID where header.SalesOrderNumber like @SalesOrderNumber and header.AccountNumber like @AccountNumber and detail.UnitPrice > @UnitPriceFrom and detail.UnitPrice < @UnitPriceTo', N'@SalesOrderNumber nvarchar(100),@AccountNumber nvarchar(100),@UnitPriceFrom money,@UnitPriceTo money', @SalesOrderNumber = 'S%',@AccountNumber = '10-%', @UnitPriceFrom = 0, @UnitPriceTo = 2 go
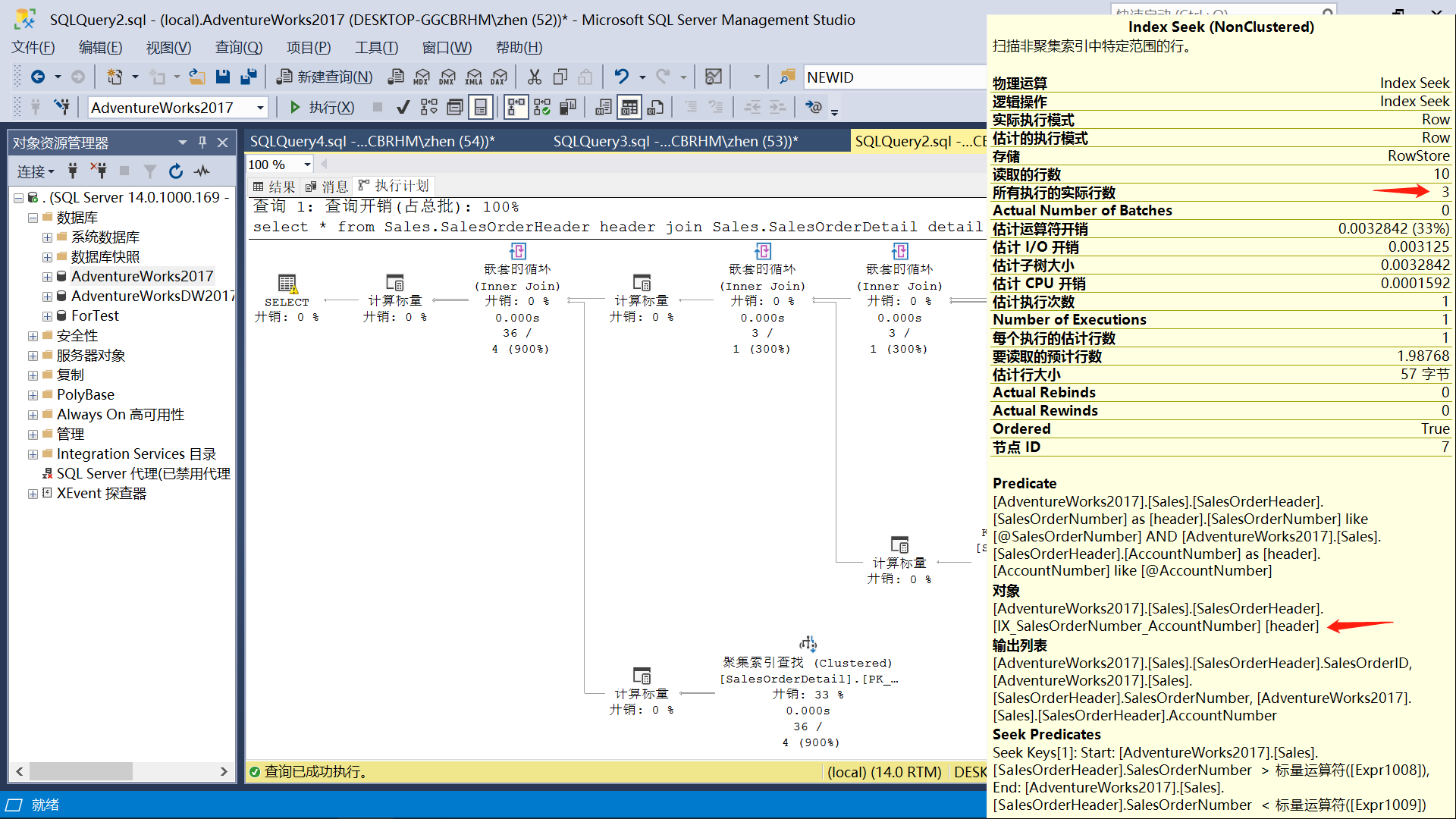
语句2用了和语句1相同的执行计划,但这明显是不合适的。
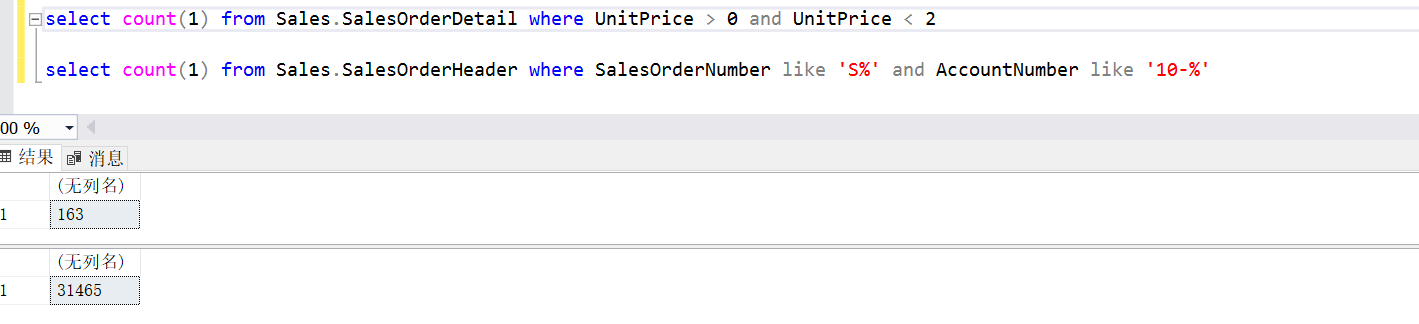
看第二张图,走 SalesOrderDetail 表的 IX_UnitPrice 索引值只会命中 163 条数据,
明显会比 SalesOrderHeader 表的 IX_SalesOrderNumber_AccountNumber 索引的命中 31465 条更优。
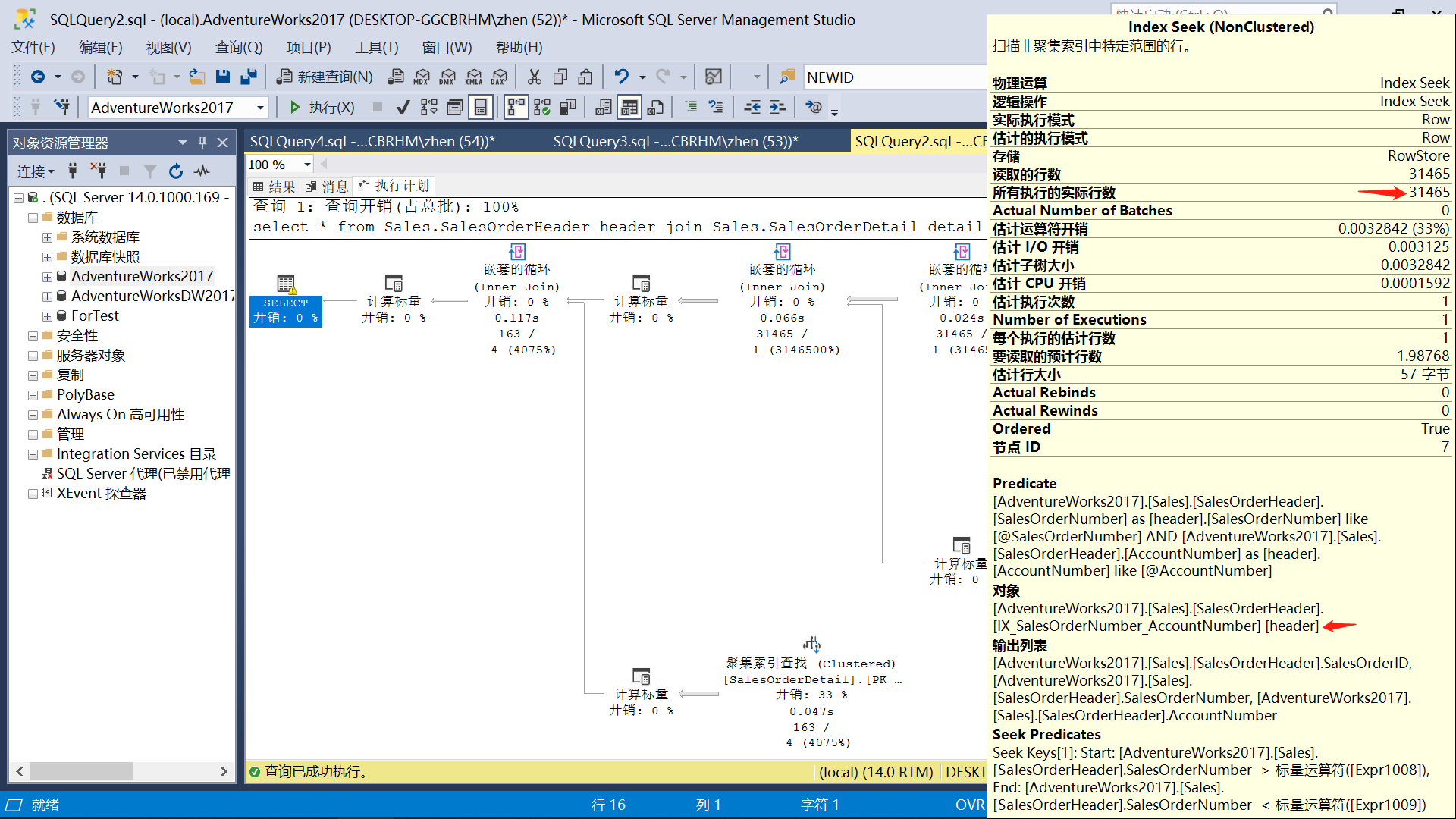
由于IX_SalesOrderNumber_AccountNumber 索引命中了 31465 条数据,之后执行计划对 SalesOrderDetail 表进行了 31465 次扫描,每次扫描通过 SalesOrderID 进行一次聚集索引查找,每次查找大概读取是 3 页数据,总共读了 95941 页。
由于表的数据量不是很大,只能举出命中几万条的数据的例子,执行花时不是很长。但我在实际经历过命中几十万条,最终读取几百万页的情况。

二、错误原因
导致这个的原因是执行语句2时使用了执行计划缓存。
即执行语句1时由于之前没有执行类似语句,没有执行计划缓存,从而生成并缓存了执行计划,执行语句2时直接使用了这个缓存的计划。
这也是为何给数据库启动账号 Lock Pages in memory 权限的原因,不给的话,就没法缓存执行计划了。
生产环境中一般是会缓存执行计划的,只是个人电脑需要手动添加权限。
SELECT图标右键,打开属性,你回发现 Parameter List 中,参数编译值和参数运行时值是不一样的。
这可以证明,语句2使用的执行计划其实是执行语句1时生成的。

并且这实际行数和估计行数也差得很离谱。
但实际行数和估计行数差得大,并不一定就是使用了执行计划缓存的原因。
有可能单纯就是执行优化器估错了命中率,这其实也是执行优化器选错索引的一个重要原因。
估计命中率和统计信息有关,这边不展开说明。
可以删除执行计划缓存,以下是删除整个数据库的执行计划缓存的方法。也可以删除特定的执行计划缓存,这边不列举。
DBCC FREEPROCCACHE;
也可以给查询语句加个空格,或者改个参数类型。即 sp_executesql 前两个参数有变,就会被认为是不同的查询语句,从而使缓存不适用。
当表的索引发生改动(创建,删除,重建等)时,该表相关的执行计划缓存也会失效。

重新执行语句,则使用了正确的索引
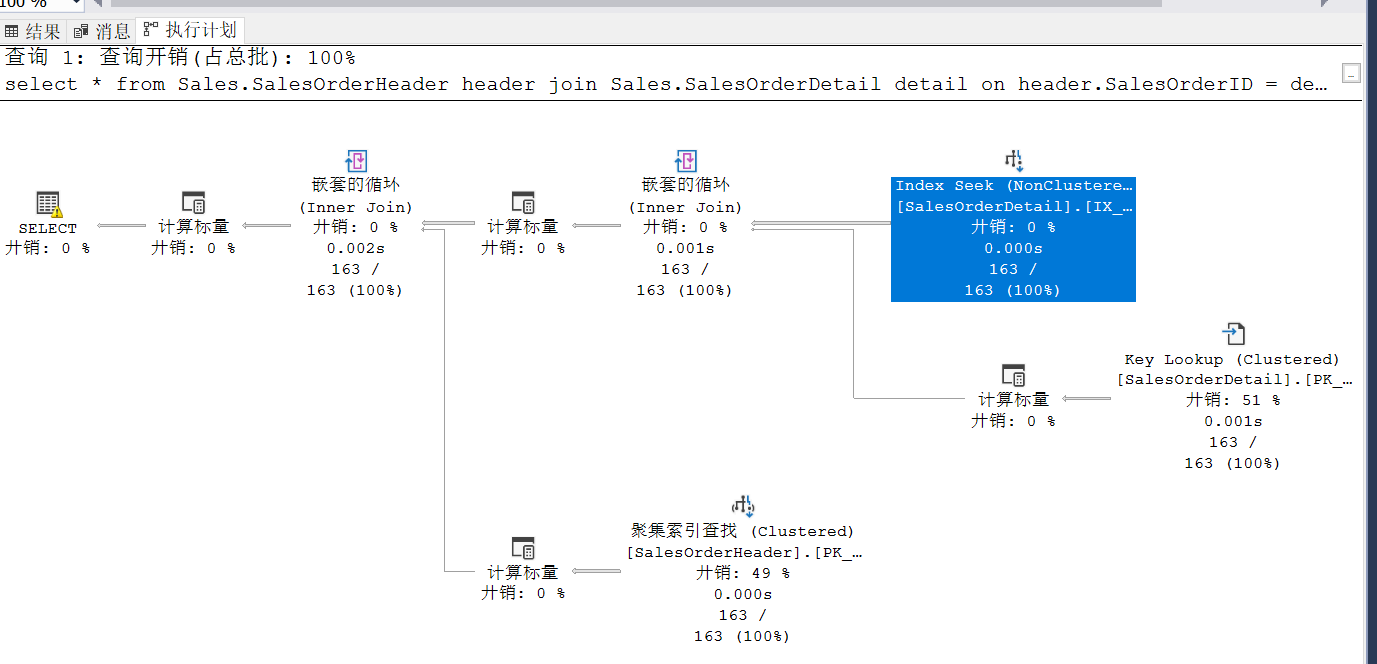

这里发现分析和编译时间只用了 6 毫秒,这里包含分析语句并生成执行计划的时间。就省了 6 毫秒,却带来了执行时间可能增加几秒甚至更多的风险。
执行计划缓存是个双刃剑,当相同语句需要重复几千次几万次执行时,它的效用能得以体现。
三、解决方案
查询语句中添加 OPTION (RECOMPILE),这样每次执行都会重新编译(重新生成执行计划)

exec sp_executesql 形式的查询语句往往是 EF 框架自动生成的,没法直接添加 OPTION (RECOMPILE) 怎么办?
其实是有办法的,比如这个。应该还有其他方法,可以自己网上搜。
四、拓展
如果99%的情况,语句2形式的执行计划都是最优解。(生产环境的参数并不是随机的,而是可预测的,我们可以根据这个进行查询语句的优化,而不需要做到面面俱到。)
那我将 IX_SalesOrderNumber_AccountNumber 这个索引删了,执行优化器是否一定会使用 IX_UnitPrice 索引了呢?
不一定
剩余 1% 不一定使用 IX_UnitPrice 索引,因为可能对 SalesOrderHeader 表进行全表扫描都比对 SalesOrderDetail 表使用 IX_UnitPrice 索引快得多。
如果当没有执行计划缓存时(重启数据库服务或者相关表的索引有改动等原因,都会清空执行计划缓存,或使其失效)首先执行的是剩下的那 1%,剩余的 99% 都没法用最优解了。
那么使用 WITH (INDEX = IX_UnitPrice) 指定使用 IX_UnitPrice 索引可以吗?
这方法也不是很行,因为只是指定了使用 IX_UnitPrice 索引,怎么用还得看查询优化器,指不定会是什么奇葩的用法。。
五、推荐阅读
Slow in the Application, Fast in SSMS?
这篇文章主要在论述为何相同语句,在程序中执行和直接在SSMS中执行花时不同。
这边的相同语句指的是完全相同,连参数也相同,区别只是一个在程序中执行,一个在SSMS中执行。
而上文举的例子是都在SSMS中执行,sp_executesql 的前两个参数相同,但后面的参数有区别(即参数的赋值不同)。
其实都是执行计划缓存的原因。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号