
l、scrapy-redis分布式爬虫
scrapy-redis分布式爬虫
1、分布式爬虫
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
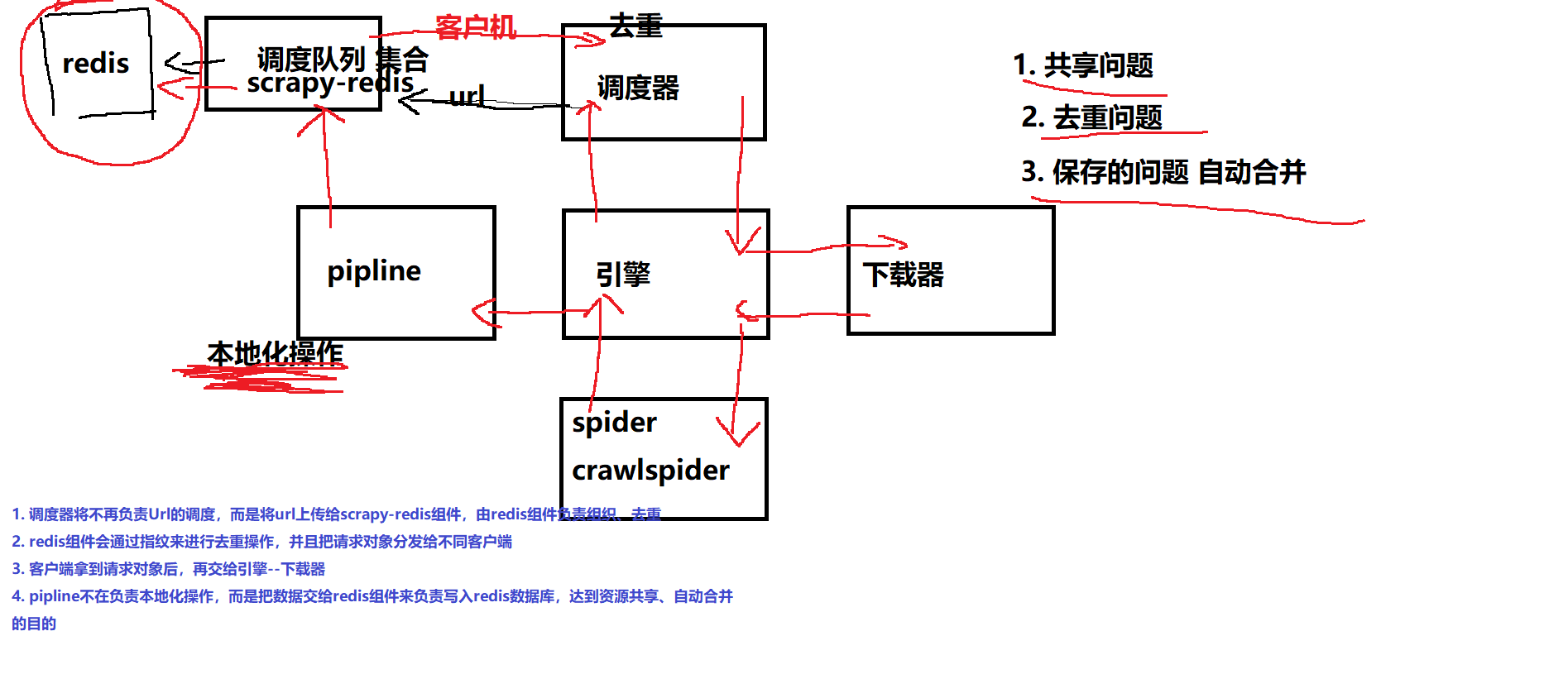
1.1、原理刨析:
-
调度器将不负责URL的调试,由scrapy-redis负责和去重
-
redis组件通过指纹(key) 将url去重,并把请求对象分发给不同的客户端
-
客户端获取请求对象后,再交给引擎->下载器
-
pipeline不负责本地化操作,而是将数据交给redis组件写入到redis库中
1.2、组成
-
Scheduler
调度器Scheduler:Scrapy本身不支持爬虫分布式,scrapy-redis 的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
-
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
-
SCHEDULER_PERSIST = True
-
调度用户的持久性
-
True
- 之前未完成的任务,在爬虫启动时,会继续执行
-
-
-
Duplication Filter
指纹过滤器:Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。
- DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
- 去重的过滤器
-
Item Pipeline
管道:引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。修改过Item Pipeline可以很方便的根据 key 从 items queue 提取item,从⽽实现 items processes集群。
-
Base Spider
蜘蛛基类:不在使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
- scrapy_redis.spiders.RedisSpider
- scrapy_redis.spiders.RedisCrawlSpider
2、安装scrapy-redis
pip install scrapy-redis
redis命令文档:http://redisdoc.com/
3、官方案例分析
git地址:
https://github.com/disenQF/scrapy-redis.git
https://github.com/rmax/scrapy-redis
运行方式:
scrapy crawl xxx
dmoz.py
#css()提取数据
for div in response.css('.title-and-desc'):
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}
#提取标签的属性
css('img::attr(src)').get()
css('.x::attr(href)').get()
#提取标签的文本
css('span::text').get()
- 不需要提取链接的分布式爬虫
myspider_redis.py
运行方式:
scrapy runspider xxx.py
- 需要提取链接的分布式爬虫
mycrawler_redis.py
运行方式:
scrapy runspider xxx.py
-
新增的组件
- from scrapy_redis.spiders import RedisSpider
- from scrapy_redis.spiders import RedisCrawlSpider

 浙公网安备 33010602011771号
浙公网安备 33010602011771号