
此作业的要求参见[https://edu.cnblogs.com/campus/nenu/2019fall/homework/7628]
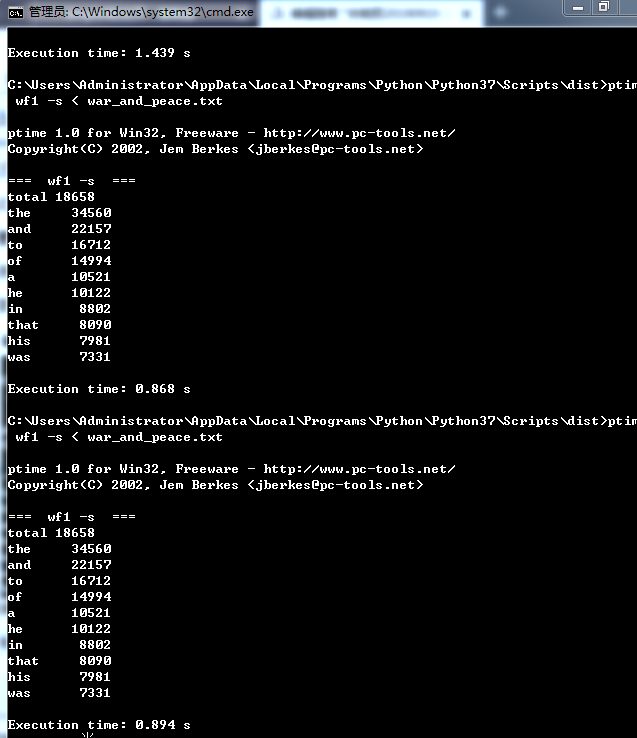
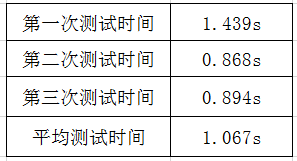
要求0 以《战争与和平》作为输入文件,重读向由文件系统读入。连续三次运行,给出每次消耗时间、CPU参数
测试方法:输入ptime wf -s < war_and_peace.txt
第一次测试时间截图:
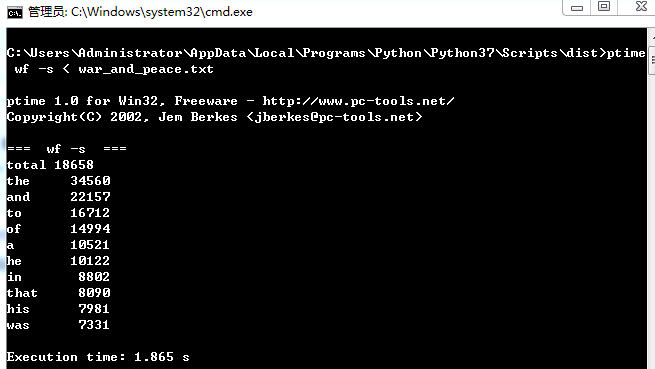
第二次测试时间截图:

第三次测试时间截图:
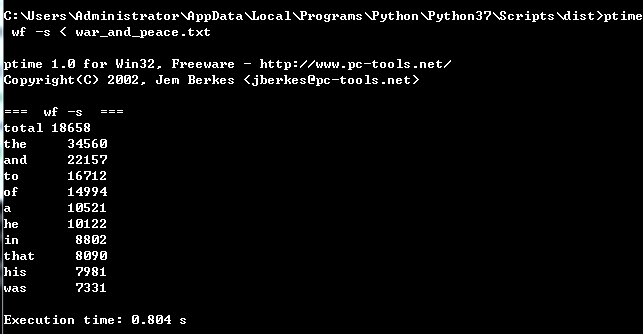
统计表:

要求1 给出你猜测程序的瓶颈。
瓶颈1:
readinput=sys.stdin.read()
读入文本所占时间较长
瓶颈2:
lists=findall(r'[a-z0-9^-]+',input.lower()) words=Counter(lists)
通过正则表达式生成单词列表和统计单词个数花费较长时间
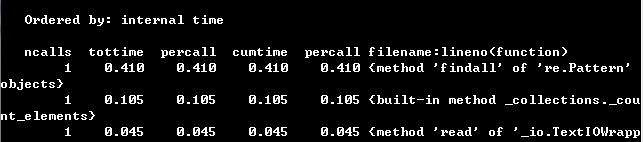
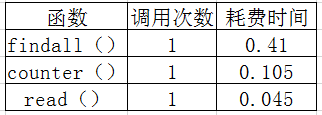
要求2 通过 profile 找出程序的瓶颈。给出程序运行中最花费时间的3个函数(或代码片断)。要求包括截图
方法:输入python -m cProfile -s time wf.py -s < war_and_peace.txt
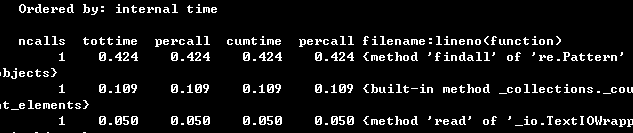
最耗费时间的3个函数:
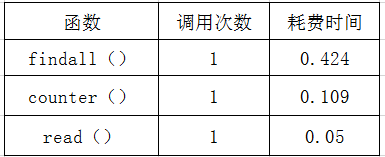
要求3 要求4根据瓶颈,"尽力而为"地优化程序性能。
这三个函数是该功能实现的关键,暂还未找到更好的替代函数,无法直接对这三个瓶颈进行优化。所以在此要求下,我做了两个实验。
实验1:封装函数
原代码
def doinput(input): lists=findall(r'[a-z0-9^-]+',input.lower()) words=Counter(lists) num=0 for key,value in words.items(): num+=1 print('total'+' '+str(num)) maxwords=words.most_common(10) for i in maxwords: print('%-8s%5d'%(i[0],i[1]))
现代码
def tongji(list): words=Counter(list) num=0 for key,value in words.items(): num+=1 print('total'+' '+str(num)) maxwords=words.most_common(10) for i in maxwords: print('%-8s%5d'%(i[0],i[1])) def doinput(input): lists=findall(r'[a-z0-9^-]+',input.lower()) tongji(lists)
再次 profile,给出在 要求1 中的最花费时间的3个函数此时的花费。要求包括截图
修改后的三次测试时间:
结论:与原来相比,封装函数后,三个耗费时间最长的函数运行时间有所下降,平均运行时间也有所下降。
实验2:在实验1的基础上,改变遍历字典的方式
原代码:
for key,value in words.items(): num+=1
现代码:
for i in words: num+=1
再次 profile,给出在 要求1 中的最花费时间的3个函数此时的花费。要求包括截图

修改后的三次测试时间:
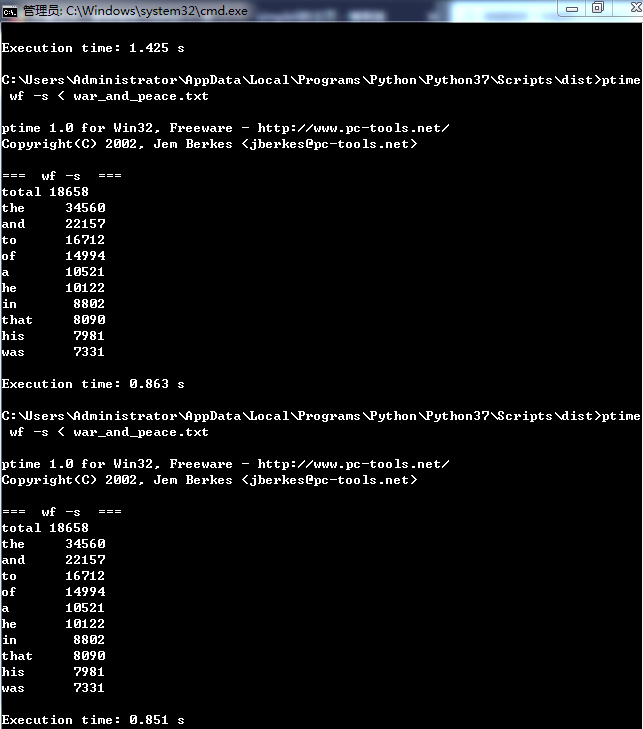

结论:与实验1结果相比,改变字典遍历方式后,counter()运行时间有所下降,findall()和read()运行时间有所上升,平均运行时间有所下降。
要求5 程序运行时间。根据在教师的机器 (Windows8.1) 上运行的速度排名,分为3档。此题得分,第1档20分, 第2档10分,第3档5分。功能测试不能通过的,0分。
供老师测试的git地址为[https://e.coding.net/sxl357/wf.git]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号