论文笔记:An Approach of Extracting God Class Exploiting Both Structural and Semantic Similarity(ENASE 2019)
研究动机
God class是一个常见代码气味,它的意思的一个类中承担了太多的责任,它会使整体代码的耦合性增加,内聚性下降。下图就是一个god class的代表。

本文利用增加内聚性的方法,将一个God class提取到新类中。主要是根据对方法在类中的结构关系和语义关系进行分析,并将强相关的方法聚集在一起,建议它们位于同一个类中。实验结果表明,重构后类之间的内聚性得到了增强。
模型
模型的方法分为两个步骤
- 根据结构相似度和语义相似度,构造方法相似矩阵
- 利用层次聚类生成簇
计算相似矩阵
有三个度量方法来计算方法之间的结构相似性
Structural Similarity between Methods
SSM是方法之间的结构相似性,它考虑了方法之间的内聚和传递性内聚的一种度量。对于方法$m_i$和方法$m_j$之间的计算方法如下:
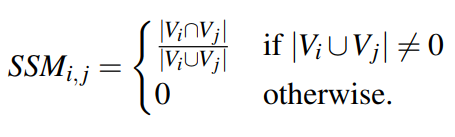
其中$V_i$和$V_j$分别表示方法$m_i$和方法$m_j$表示的实体变量。SSM值越高,说明两个方法可能在同一个类中。
Call based Dependence between Methods
CDM也是方法之间的结构相似性,它通过方法调用来计算两个方法之间的关系。对于方法$m_i$和方法$m_j$之间的计算方法如下:
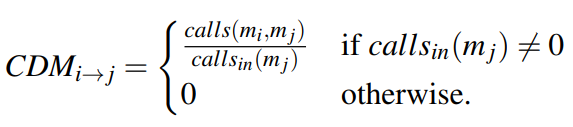
其中$calls(m_i,m_j)$表示方法$m_j$被方法$m_i$调用的次数,$calls_(in)(m_j)$是方法$m_j$的调用总数。最终方法$m_i$和方法$m_j$的CDM为
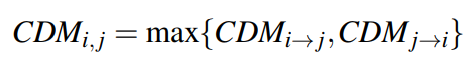
Conceptual Similarity between Methods
CSM是类中每个方法的概念内聚度量。它度量两个方法在语义上的关联程度。在类中的每一个方法首先由Latent Semantic Indexing (LSI)构造的语义空间中的向量表示。然后计算$m_i$和$m_j$两种方法的向量表示$v_i$和$v_j$的余弦相似度,如下所示
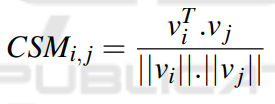
其中$||v_i||$代表向量$v_i$的欧几里德范数。在这篇文章中,作者使用LDA主题模型来表示在向量空间中的每一种方法的主题分布,去掉停止词,空格,下划线等信息,放入LDA模型中,形成两个矩阵:topic-word矩阵和document-topic矩阵。将document-topic矩阵的每一行作为该方法的主题分布,然后将向量放入上面的公式计算方法之间的相似度。
最终,两个方法在同一个类的可能性由下式表示。
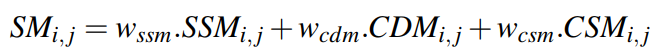
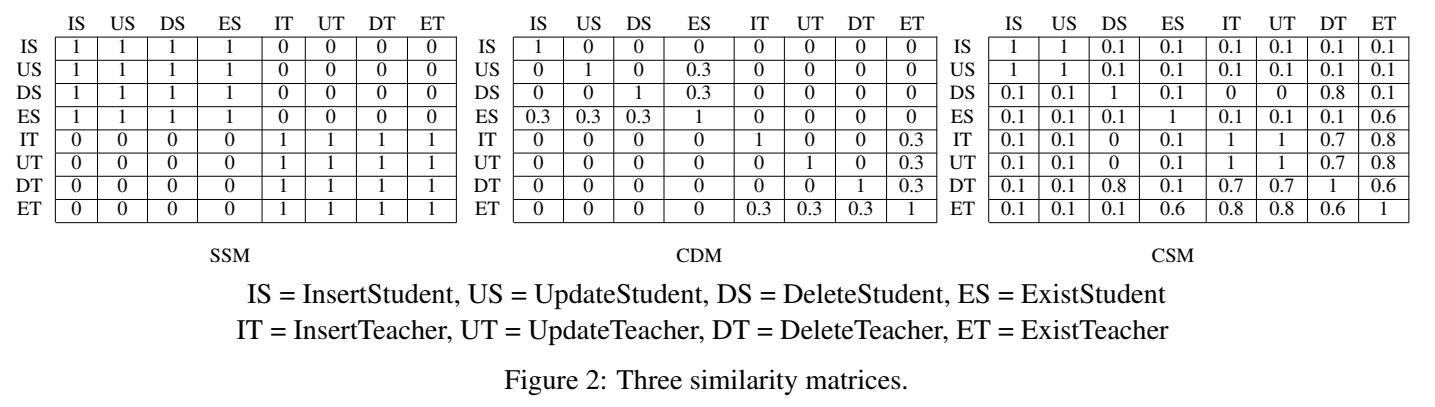
下图就是三个相似度矩阵

层次聚类
根据生成的相似度矩阵,进行层次聚类

实验
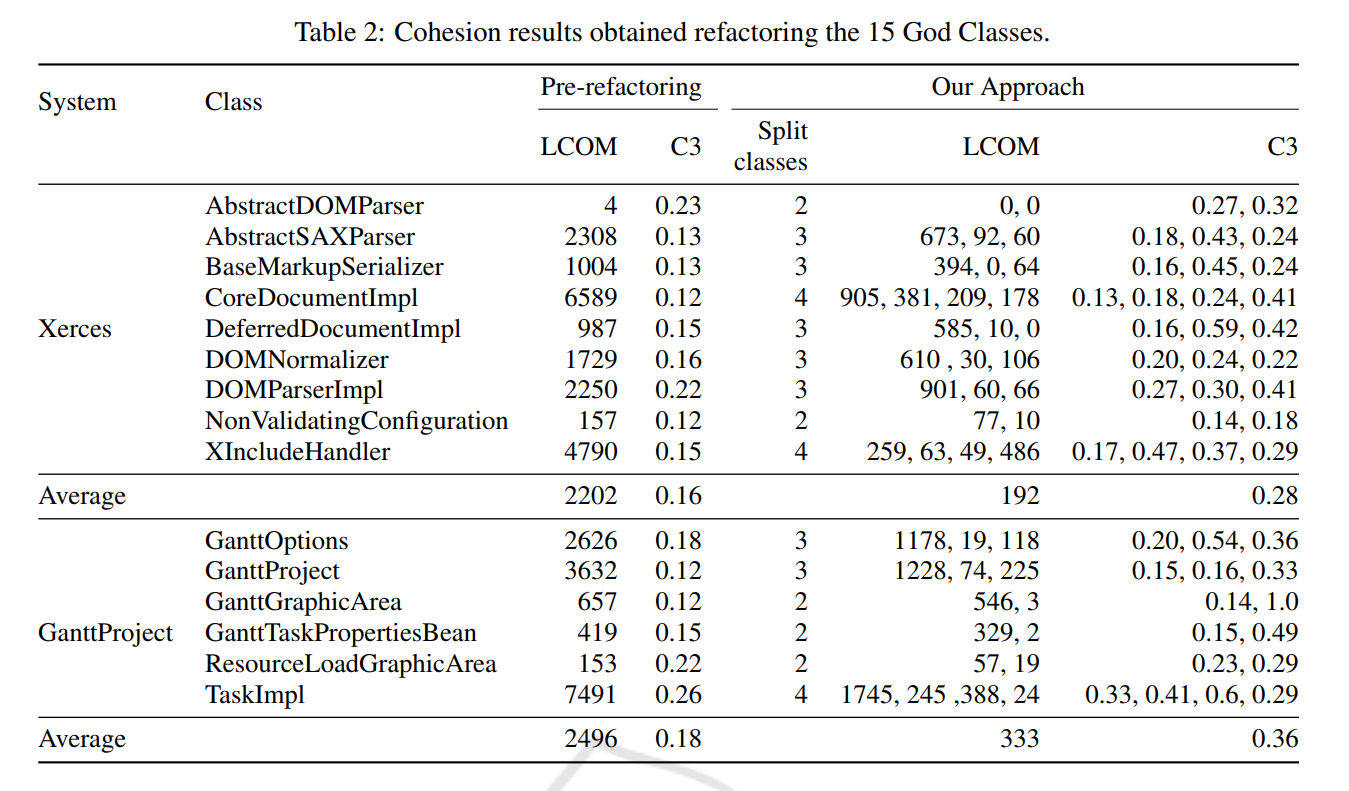
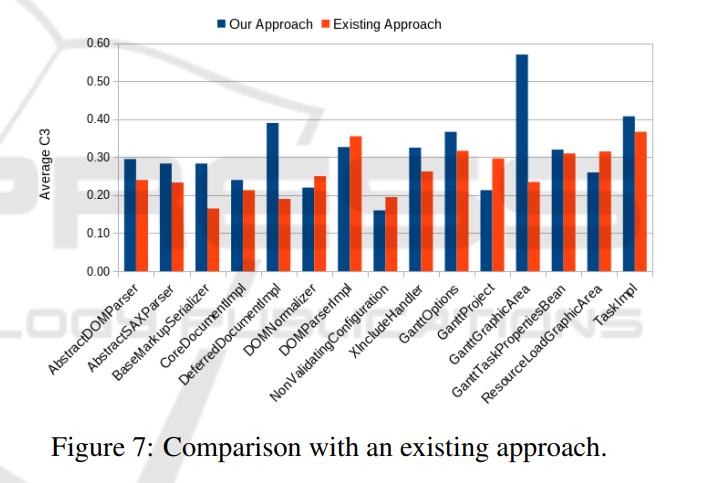
作者选取了2个开源数据集,并用两个内聚度量来评估方法的性能,分别为LCOM(Lack of Cohesion of Methods)和C3(Conceptual Cohesion of Classes),通过我们的方法,对重构前后15个God class的LCOM和C3指标进行了分析,从表中可以看到,对于所有类,本文的方法进行重构之后,内聚性都得到了改进。同时比较了一个文献中的方法,仍然取得了较好的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号