
kafka生产者
Kafka
Kafk是一个流平台,这个平台上可以发布和订阅数据流,并把它们保存起来进行处理。
kafka的数据按照一定的顺序持久化保存,可以按需读取,数据分布在整个系统里,具备数据故障保障和性能伸缩能力。
kafka的数据被称为消息,有字节数组组成,消息通过主题进行分类,可以分为若干个分区,一个分区就是一个提交日志。
消息以追加的方式写入分区,以先进先出的方式顺序读取。一个主题一般包含几个分区,所以无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
kafka通过分区实现数据冗余和伸缩性。分区可以分布在不同的服务器上。
为什么选择kafka
1、多个生产者支持多个生产者,不管客户端使用单个主题还是多个主题。适合用来从多个前端系统收集数据,并以统一的格式对外提供数据。
2、多个消费者支持多个消费者从一个单独的消息流上读取数据,并且消费者之间互不影响。
多个消费者可以组成一个群组,共享一个消息流,保证整个群组对每个给定的消息只处理一次。
3、基于磁盘的数据存储允许消费者非实时的读取。消息被提交到磁盘,并根据设置的保留规则进行保存。
每个主题可以单独设置保留规则。数据持久化可以保证数据不会丢失。消费者可能会因为处理速度慢或者突发的流量高峰导致无法及时的读取消息。
4、伸缩性一个包含多个broker的集群,即使个别broker失效,仍然可以持续的为客户提供服务。
5、高性能通过横向拓展生产者、消费者和broker,kafka可以轻松的处理巨大的消息流。处理大量数据时保证亚秒级的消息延迟。
kafka生产者组件图
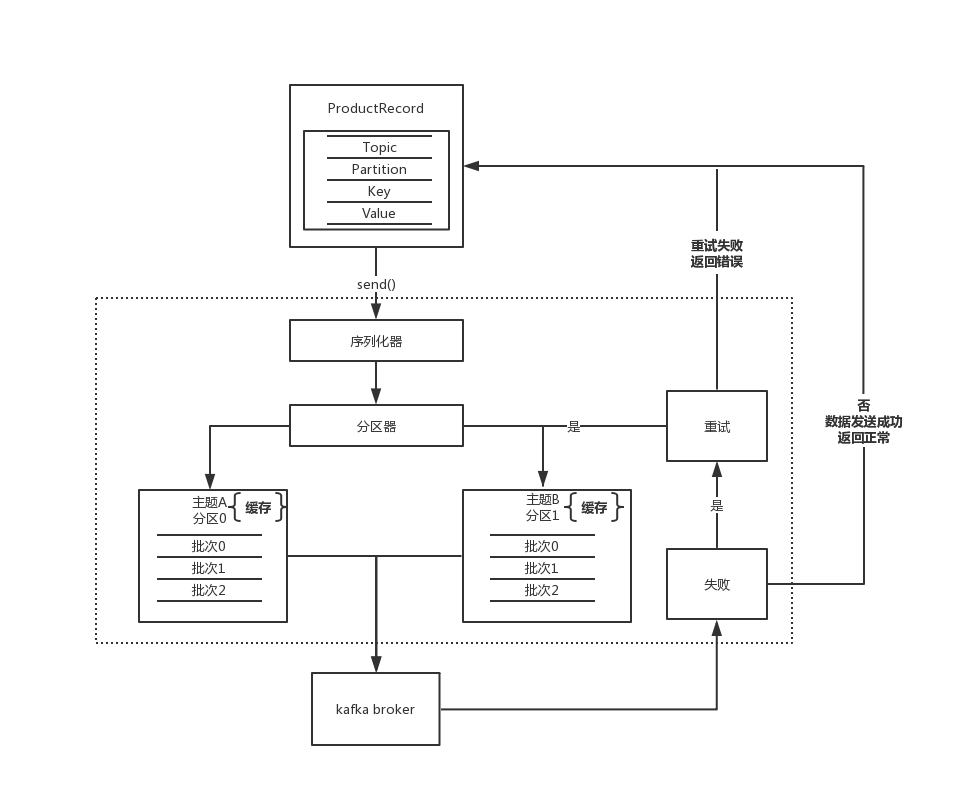
消息发送的3种方式:
1、发送并忘记消息发送后不关心结果,会有消息丢失的可能
2、同步发送返回一个future对象,消息发送后调用get()方法阻塞等待,根据返回结果判断消息发送是否成功。
3、异步发送消息发送后,指定一个回调函数,服务器返回响应会调用该函数。
生产者配置参数:
1、acks
指定有多少个分区副本收到消息,消息才算写入成功。 acks=0:不等待服务器响应,吞吐量高,但会有消息丢失的可能。
acks=1:集群中leader收到消息则返回响应。leader收到消息还未写入就宕机,会造成消息丢失。 吞吐量较高,有较低几率丢失消息 acks=all:所有分区节点收到消息才响应成功。安全系数高,吞吐量低,
2、buffer.memory
设置生产者内存缓冲区大小,kafka的消息都是批次处理的,用以节约网络消耗。缓冲区内有多个批次。
当应用程序发送消息的数据大于消息发送到服务器的速度,send()方法会被阻塞,max.block.ms可以设置阻塞时间。
3、compress.type
压缩算法,有snappy,gzip,lz4。snappy占用较少cpu,但压缩比没有gzip高。
4、retries
最大重试次数,在一些临时性的错误,如超时、leader不存在等,生产者会自动进行消息重发,当重试次数达到最大值则放弃重试返回错误。
默认情况下,每次重试间隔100ms。可以通过retry.backoff.ms进行修改,注意,总的重试时间应该大于重新选举出leader的时间。
5、batch.size
一个批次使用的最大内存大小,按字节数计算。批次中的消息填满后会发送出去。但是在规定时间内,即使没有填满也会发送。通过linger.ms设置等待时间
6、linger.ms
等待批次填满的时间。批次填满或者linger.ms达到上限,消息就会被发送出去。
7、max.in.flight.requests.per.connection
生产者在收到服务器响应之前可以发送多少个消息。设为1可以保证消息时按照发送的顺序写入服务器,即使发生重试。
8、request.timeout.ms、metadata.fetch.timeout.ms、timeout.ms request.timeout.ms:
生产者发送消息时等待服务器响应的时间。
metadata.fetch.timeout.ms:生产者获取元数据(目标分区leader)时等待服务器响应的时间。
timeout.ms:broker同步副本等待消息确认的时间。
9、max.block.ms
send()和partitionFor()的阻塞时间。缓冲区已满或者没有可用元数据时,方法会被阻塞,阻塞时间达到该值抛出异常
10、max.request.size
生产者发送请求的大小,既指单个消息的最大值,也指单个请求的所有消息总的大小。例如,假设这个值为lMB,那么可以发送的单个最大消息为lMB,或者生产者可以在单个请求里发送一个批次,该批次包含了1000个消息,每个消息大小为1KB。另外,broker对可接收的消息最大值也有自己的限制(l'lessage.l'lax.bytes),所以两边的配置最好可以匹配,避免生产者发送的消息被broker拒绝.
11、receive.buffer.bytes、send.buffer.bytes
receive.buffer.bytes:接收TCP Socket的数据包缓冲区大小
send.buffer.bytes:发送TCP Socket的数据包缓冲区大小
如果都设为-1,则使用操作系统的默认值。
序列化器
kafka的消息存储格式为字节数组,所以kafka需要对生产者的数据进行序列化存储。
分区器
productRecord中存储的是k-v键值对,key为空时,使用默认分区器,采用轮询方式选择主题内的某个分区。当key不为空,则会对key进行散列算法,根据散列值映射到某个分区。
参考:
《kafka权威指南》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号