
初识python 之 pyspark读写mysql数据
代码
#!/user/bin env python # author:Simple-Sir # create_time: 2022/6/2 14:20 from pyspark.sql import SparkSession spark = SparkSession.builder.master("local[*]").appName("sparkSql").getOrCreate() sc = spark.sparkContext rdd = sc.textFile('user.txt').map(lambda x:x.split(',')).map(lambda x:(x[0],x[1])) df = rdd.toDF(['name','age']) df.show() # 查看RDD数据 # 保存数据到MySql # jdbc 连接类型 # url dbc:mysql://地址:端口/数据库名 # driver 驱动,固定 # user 用户 # password 密码 # dbtable 表,若表不存在,则新建。 # SaveMode.append 数据保存模式,追加 ''' * `append`: Append contents of this :class:`DataFrame` to existing data. * `overwrite`: Overwrite existing data. * `error` or `errorifexists`: Throw an exception if data already exists. * `ignore`: Silently ignore this operation if data already exists. ''' df.write.format("jdbc")\ .option("url", "jdbc:mysql://bigdata01:3336/hive")\ .option("driver", "com.mysql.jdbc.Driver") \ .option("user", "root") \ .option("password", "123") \ .option("dbtable", "tmp_20220531_2") \ .mode(saveMode='append')\ .save() # 读取mysql数据 tmp_20220531_2 = spark.read\ .format("jdbc")\ .option("url", "jdbc:mysql://bigdata01:3336/hive")\ .option("driver", "com.mysql.jdbc.Driver")\ .option("user", "root")\ .option("password", "123") \ .option("dbtable", "tmp_20220531_2") \ .load()\ .show()
运行结果
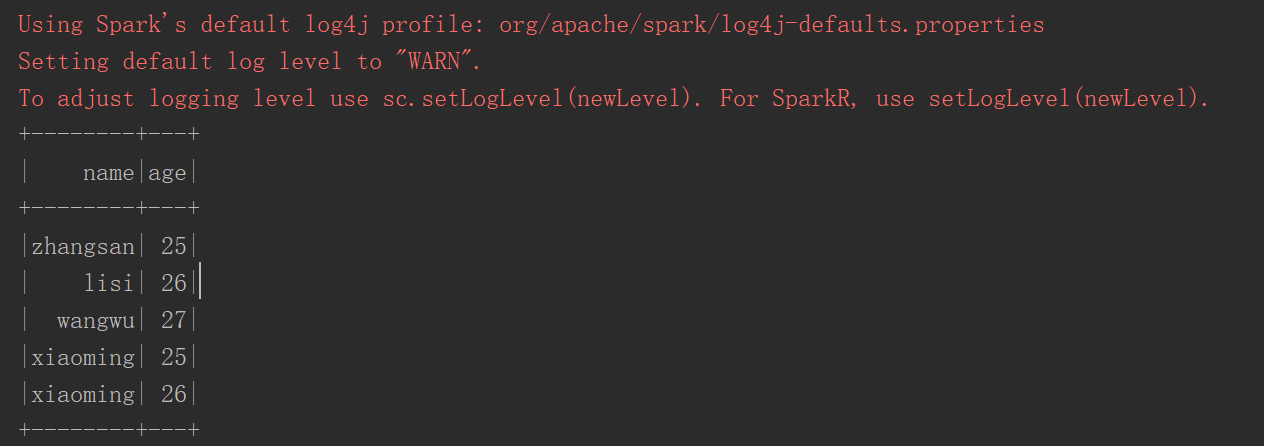
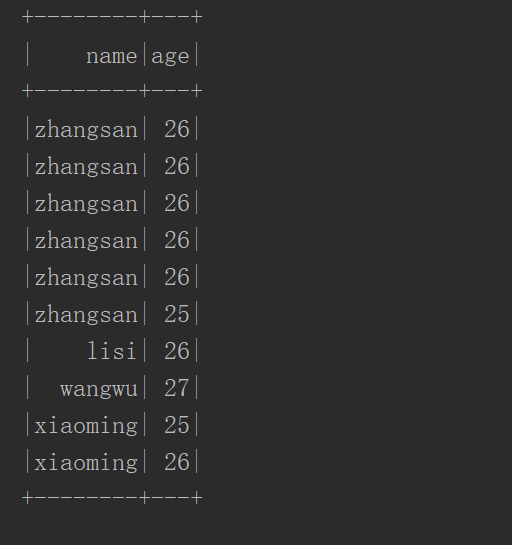
世风之狡诈多端,到底忠厚人颠扑不破;
末俗以繁华相尚,终觉冷淡处趣味弥长。
posted on 2022-06-06 16:26 Simple-Sir 阅读(896) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号