spark 之 windows下基于IDEA2021.3.3搭建spark开发环境实现wordcount功能
注* [写的很细,内容有点长,可以选择目录跳转]
环境准备
因为Spark是scala语言开发的,scala是java语言开发的,所以需要安装JDK和scala。
JDK1.8
maven-3.8.5
Scala-2.12.15
IDEA-2021.3.3
JDK
注意: 是安装JDK不是JAVA(JRE)
JDK是Java的开发工具
JRE只是Java程序的运行环境
JDK包含JER
安装包: jdk-8u333-windows-x64.exe
下载
https://www.oracle.com/java/technologies/downloads/#java8-windows
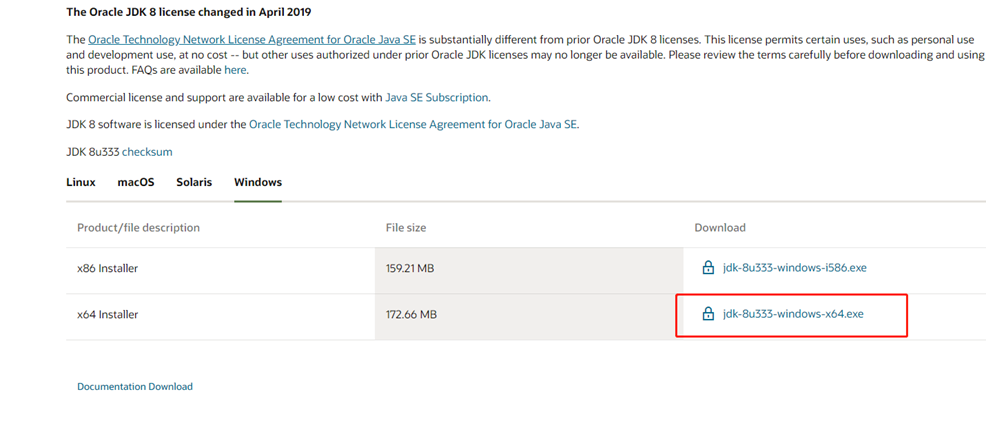
安装
修改JDK安装目录,其他默认
修改JRE安装目录
配置环境变量
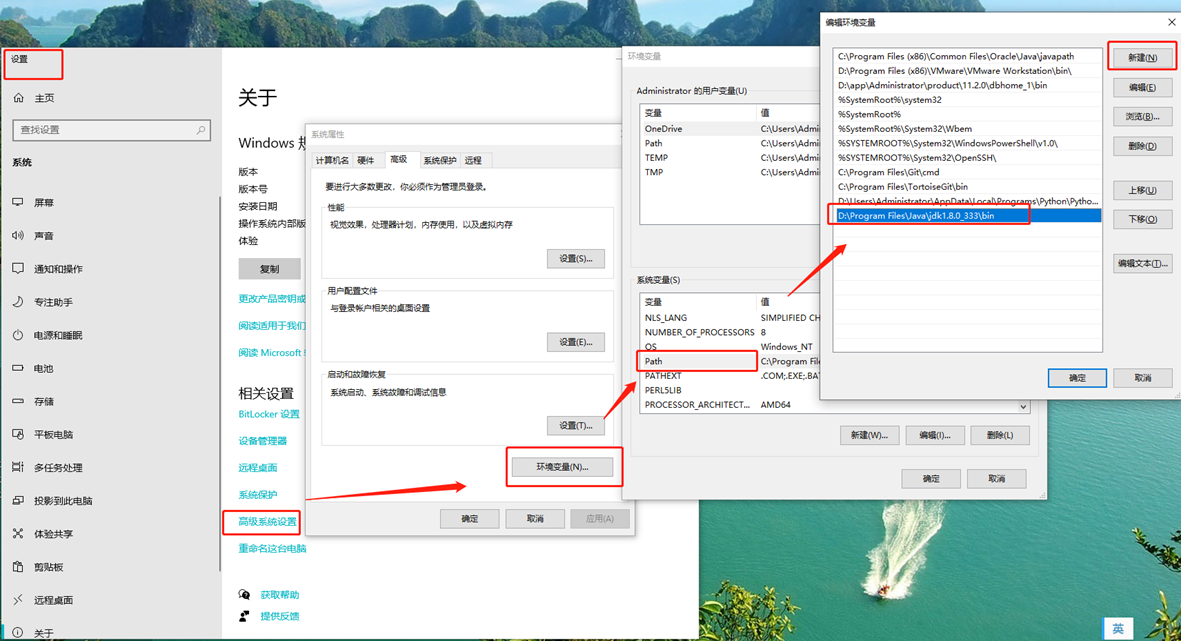
测试java环境是否配置成功
按Win+R,输入cmd进入dos界面
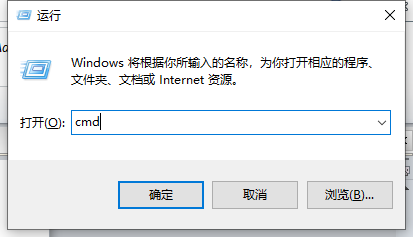
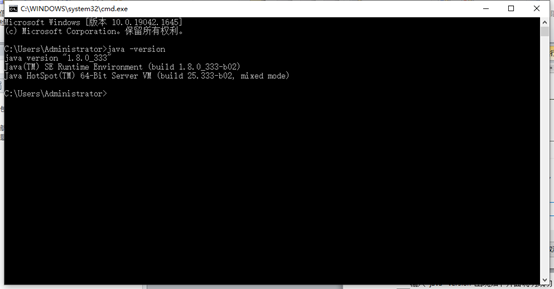
输入 java –version 出现如下界面说明成功。
Maven
下载
https://maven.apache.org/download.cgi
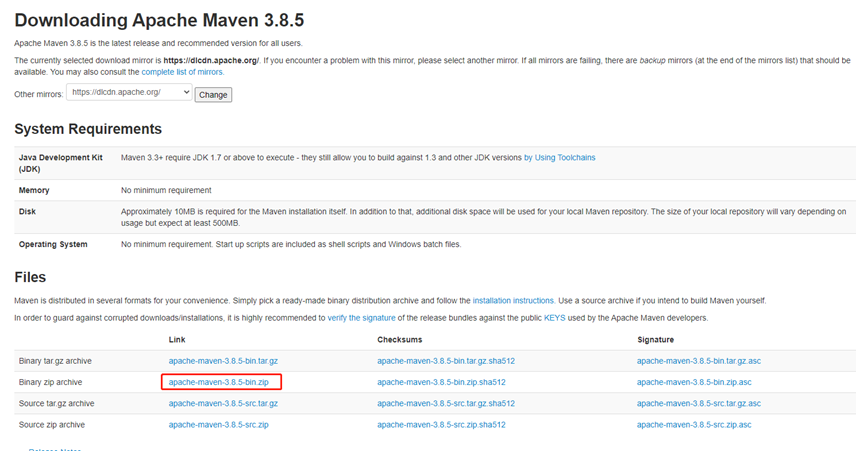
安装
下载之后解压到(目录可自己定)D:\Program Files\apache-maven-3.8.5
配置
并创建本地maven仓库地址((目录可自己定))D:\Program Files\apache-maven-3.8.5\resp

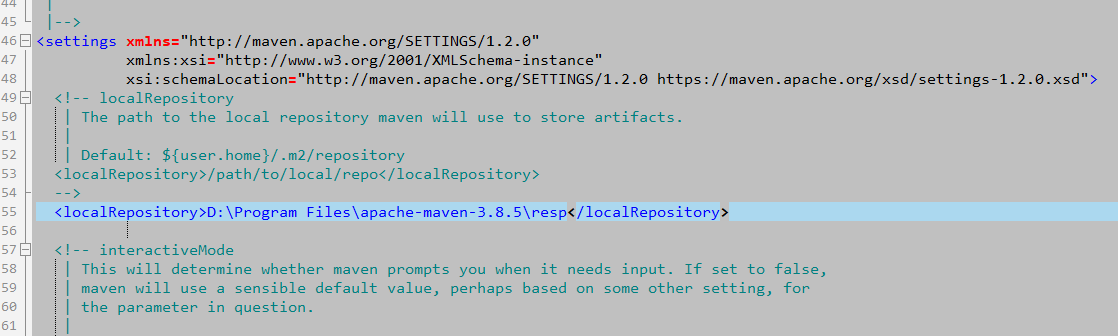
修改配置文件D:\Program Files\apache-maven-3.8.5\conf\settings.xml
设置本地资源库地址(默认${user.home}/.m2/repository)
<localRepository>D:\Program Files\apache-maven-3.8.5\resp</localRepository>
Maven中央存储库与远程存储库配置
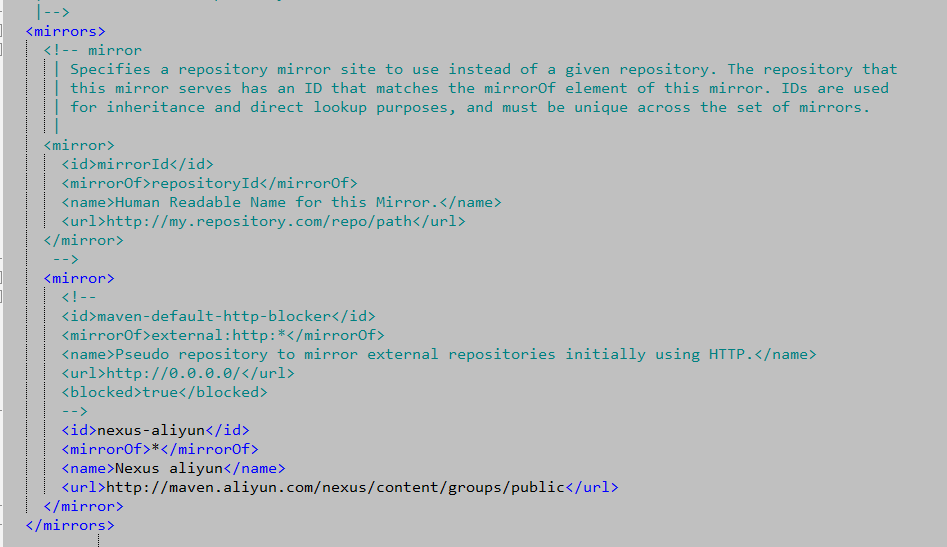
<mirrors> <mirror> <id>nexus-aliyun</id> <mirrorOf>*</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror> </mirrors>
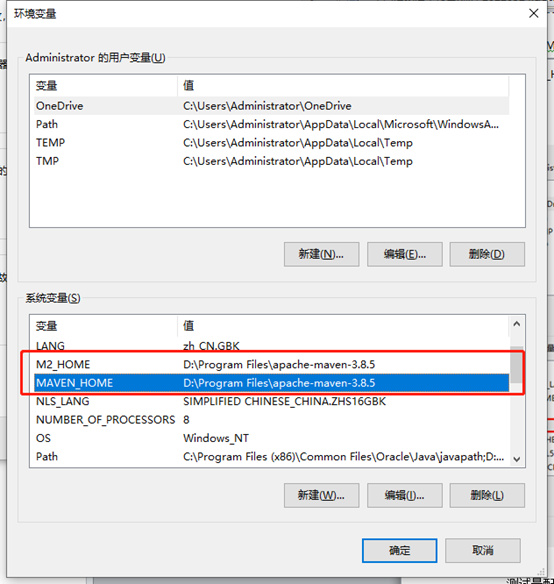
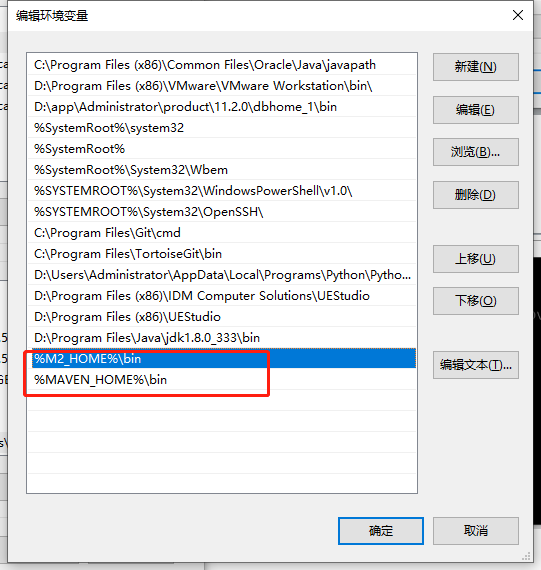
配置maven环境变量
M2_HOME D:\Program Files\apache-maven-3.8.5
MAVEN_HOME D:\Program Files\apache-maven-3.8.5
测试是配置是否成功
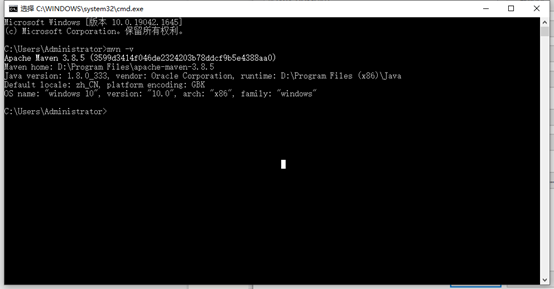
mvn -v
出现如下内容,说明成功
scala
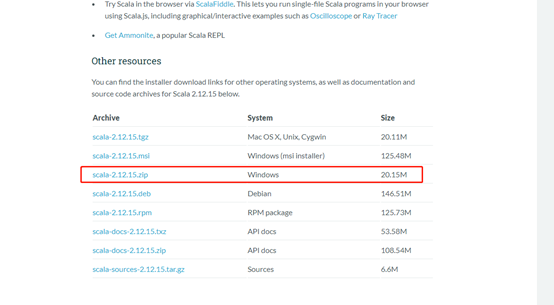
下载
https://www.scala-lang.org/download/2.12.15.html
Scala-2.12.15.zip
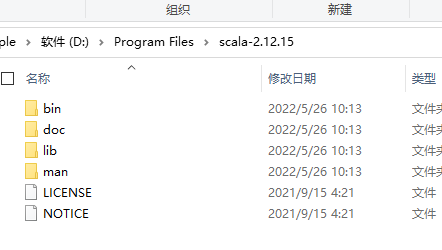
安装
解压到安装目录
D:\Program Files\scala-2.12.15
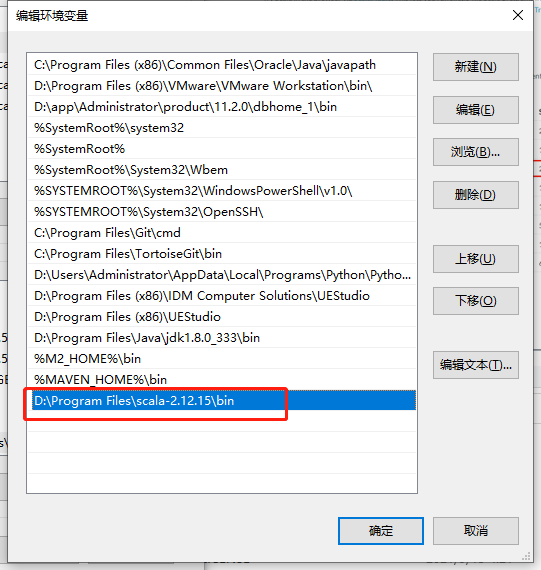
配置环境变量
测试是否安装成功
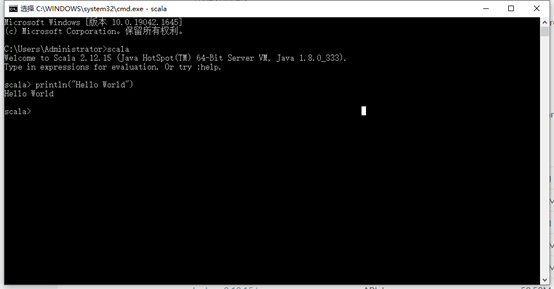
IDEA
下载
官网下载(可选择下载版本)
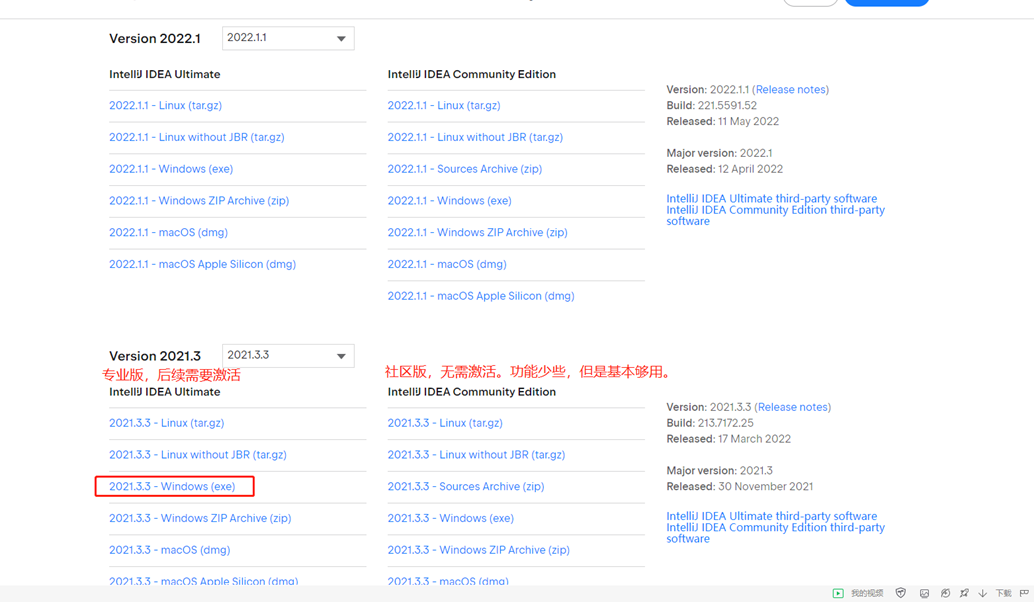
https://www.jetbrains.com/idea/download/other.html
ideaIU-2021.3.3.exe
注意区分专业版和社区版,专业版需要激活使用。我下载的是专业版,后续有激活教程。
安装
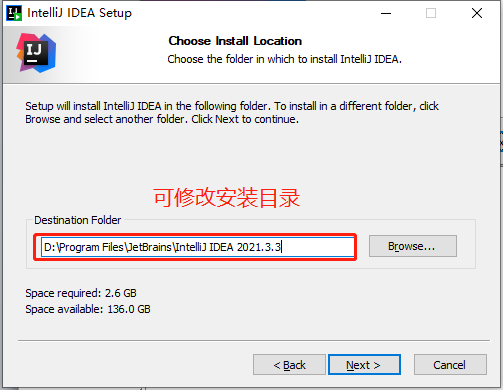
可修改安装目录
是否创建桌面快捷方式
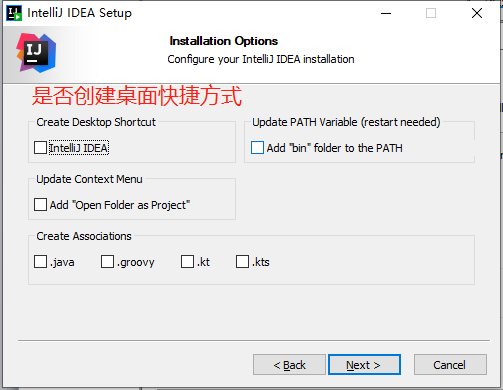
勾选上启动IDEA选项
试用(临时激活)
永久激活需要创建项目之后操作。
下载插件包
链接:https://pan.baidu.com/s/13FLQWAsPj_E1cK29jR96Bw
提取码:f07q
启动
登陆
进入界面,需要注册帐号登陆。
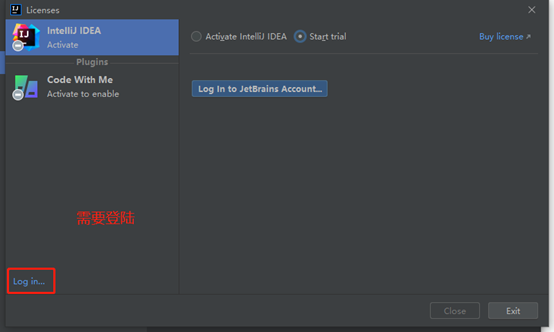
试用
登陆之后,选择试用(30天)。
如果试用期已经到了,这里是无法进入的。需要使用临时激活码激活。
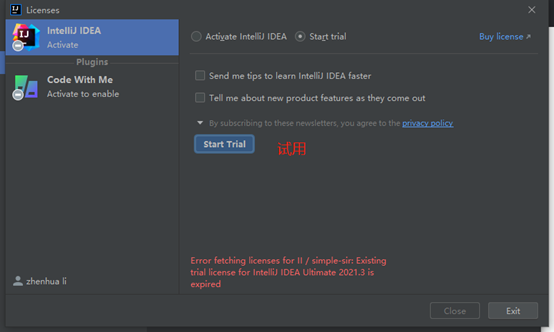
临时激活码
临时激活码(每天更新的),有效期30天。
下载临时激活码
https://www.jihuooo.com/jhm/code1.zip
我的试用期已经到了,输入临时激活码。
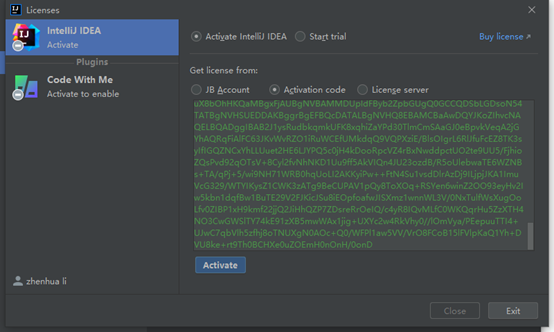
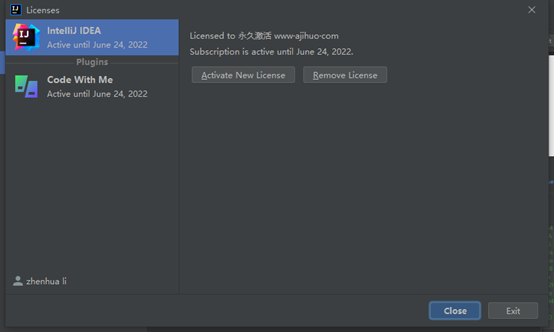
汉化
汉化(不想汉化的,可忽略)
安装汉化插件
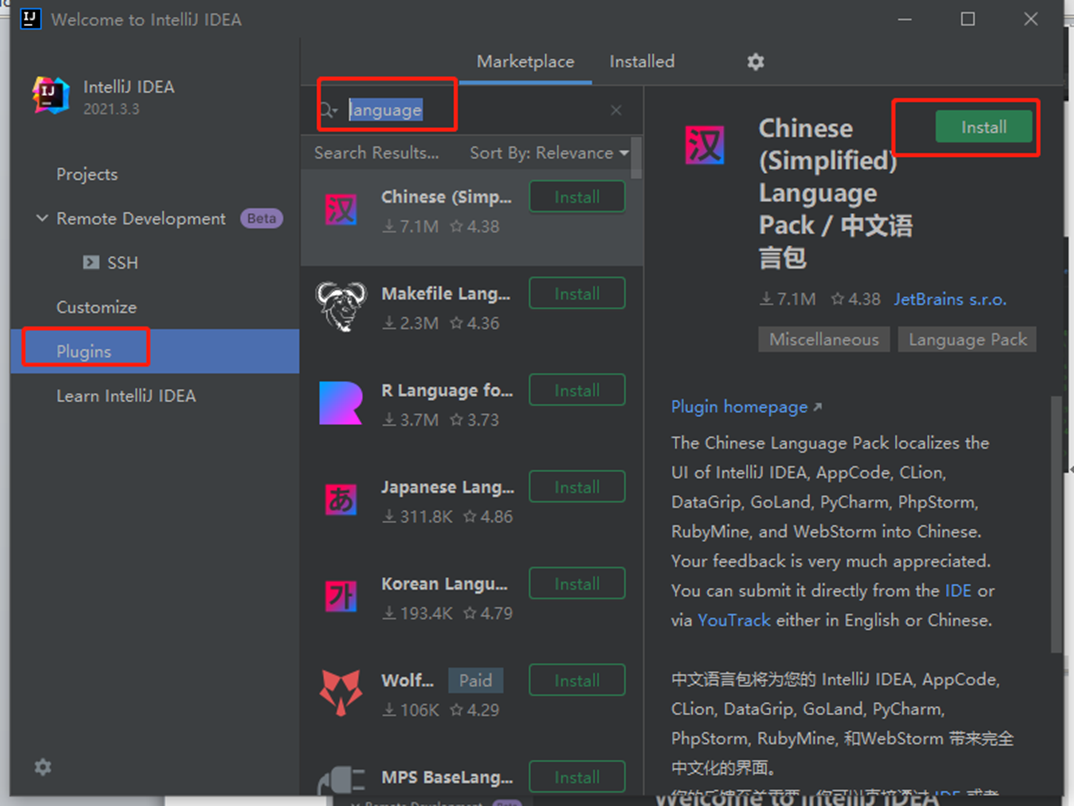
安装好之后,重启IDEA。
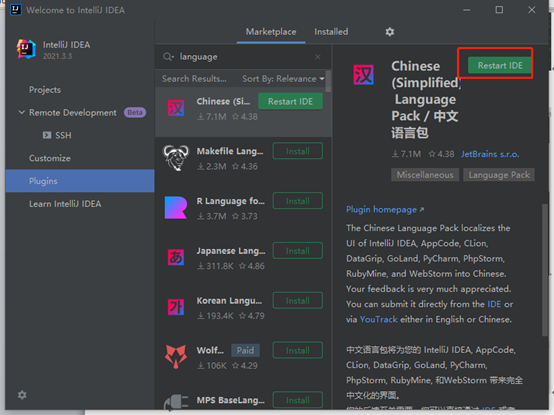
重启之后,显示已汉化
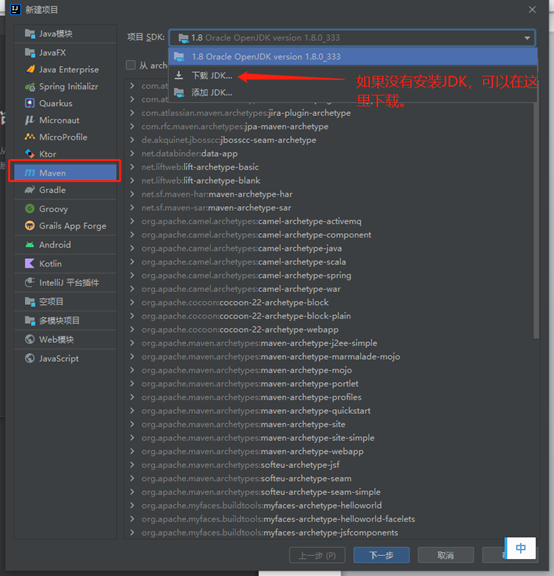
创建项目
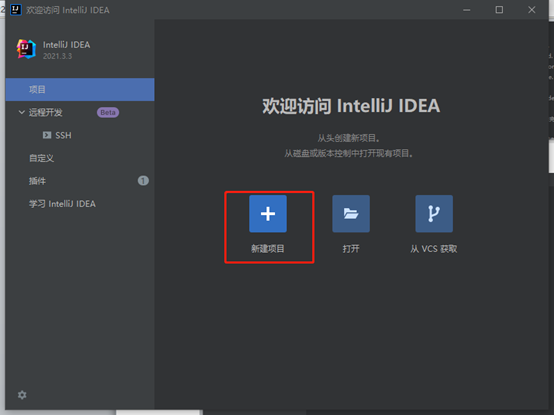
选择maven
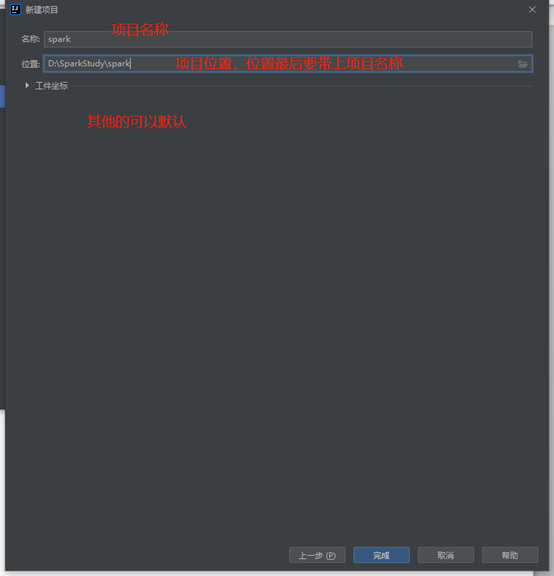
设置项目名称和路径
创建完成,进入主界面会使用有小提示。
永久激活
下载激活插件包
链接:https://pan.baidu.com/s/13FLQWAsPj_E1cK29jR96Bw?pwd=f07q
提取码:f07q
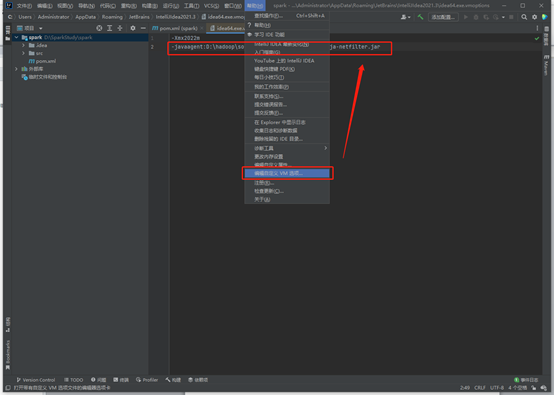
解压到D:\hadoop\software\ja-netfilter-v2.2.2
把ja-netfilter.jar添加到idea64.exe.vmoptions(帮助 => 编辑自定义VM选项)
-javaagent:D:\hadoop\software\ja-netfilter-v2.2.2\ja-netfilter.jar
重启查看到期时间
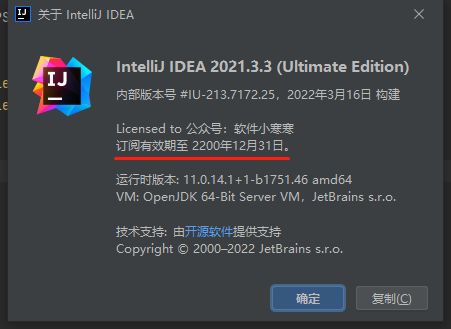
maven设置
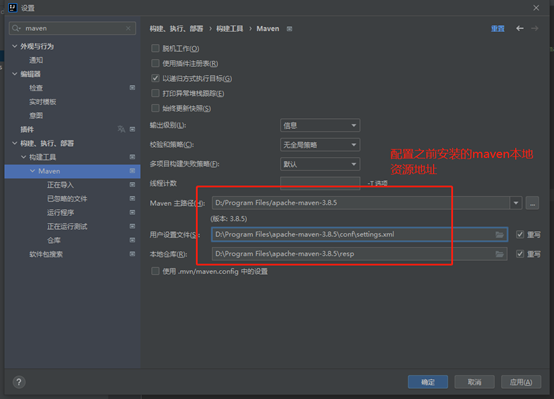
安装scala插件
安装完之后,重启IDEA
重启之后,会自动更新maven资源库
添加scala框架支持

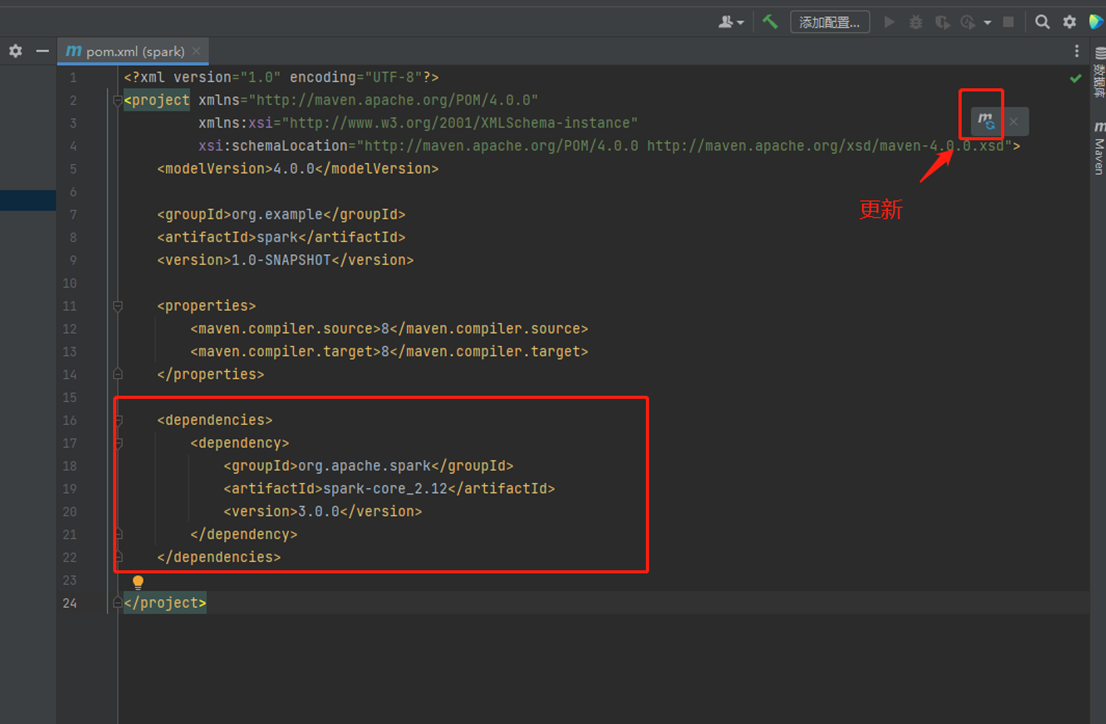
在pom.xml中添加Spark 框架的依赖
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> </dependencies>
目录说明
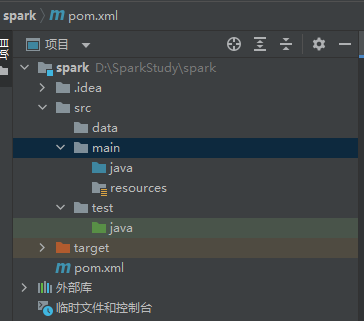
创建的项⽬在以项⽬名称为名的⽂件夹下,⽂件夹下有以下内容:
1 .idea ⽂件夹 :存放项⽬的控制信息,包括版本信息,历史记录等等。(上传SVN以及分享代码给别⼈时不需要)
2 src 项⽬的代码存放⽂件夹
3 main 项⽬正式代码⽂件
3 java 默认存放java代码的⽂件夹
4 resource 资源⽂件夹,存放配置⽂件和⼀些数据
5 test 项⽬测试⽂件夹
6 java 测试的java代码
7 pom⽂件 项⽬的maven依赖包和⼀些插件的配置
WordCount
需求说明:通过spark实现词频统计
目录准备
在main下面新建spark目录
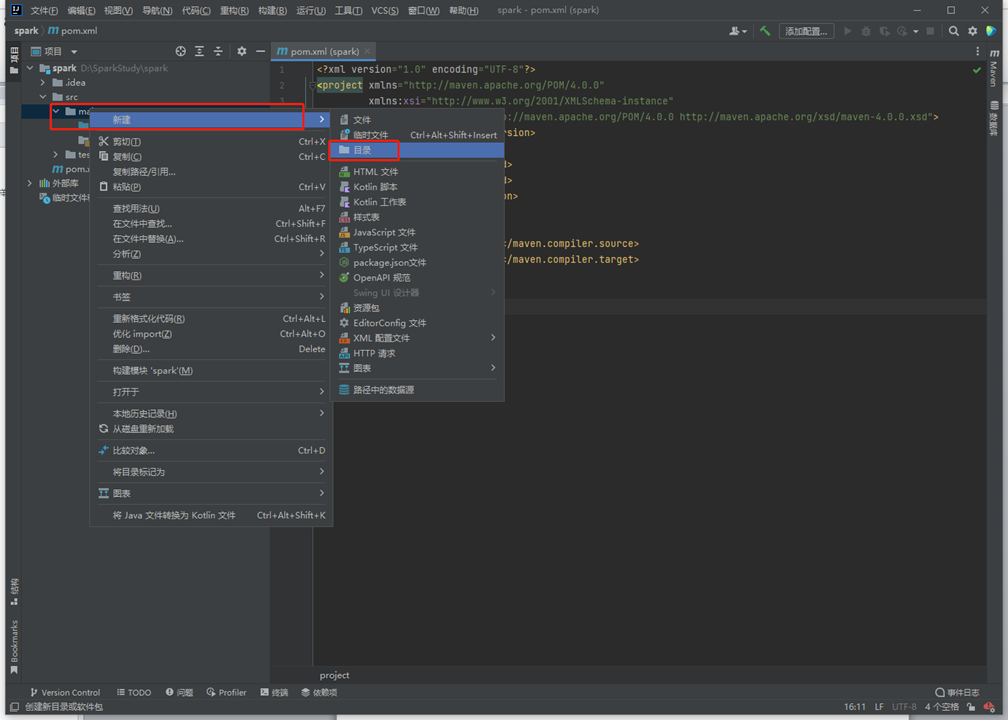
将目录转为源文件类型
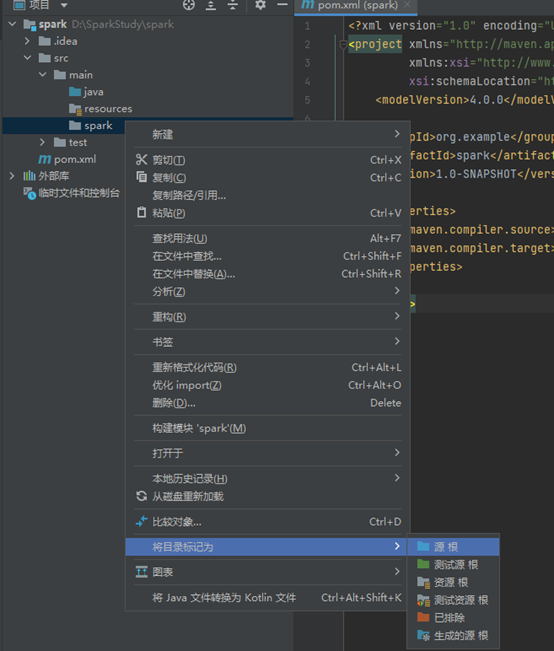
在spark下新建scala类
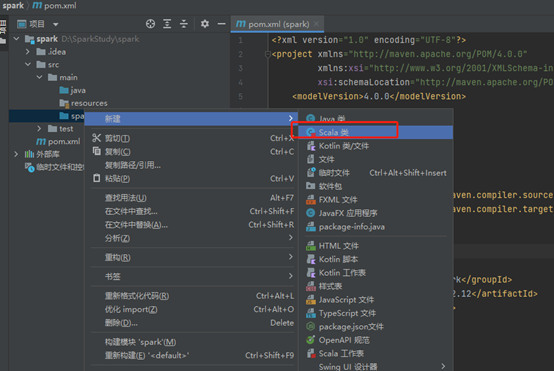
命名为wordCount,选择Object

数据准备
在项目下,创建datas/words/data1.txt、data2.txt文件
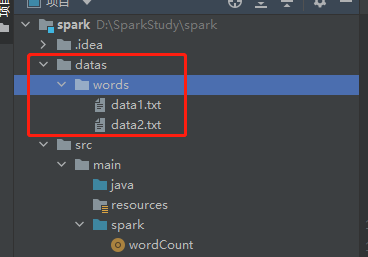
data1.txt文件内容为
hello world
hello scala
hello spark
data2.txt文件内容为
hello world
hello scala
处理流程
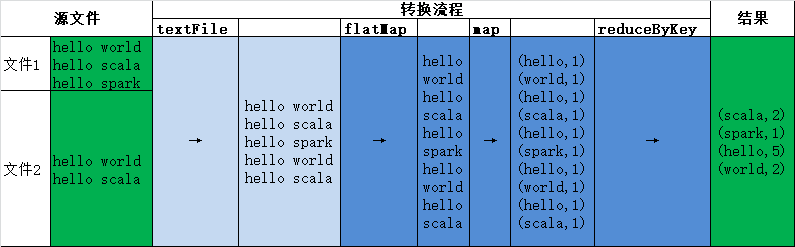
wordCount代码


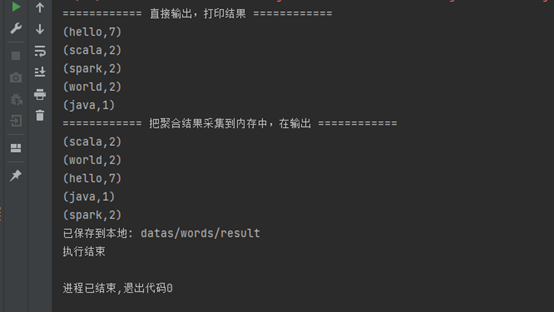
1 import org.apache.spark.{SparkConf, SparkContext} 2 3 object wordCount { 4 def main(args: Array[String]): Unit = { 5 // 创建spark运行配置对象 初始化环境 6 val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount") 7 8 // 创建连接对象 9 val sc = new SparkContext(conf) 10 11 // 设置日志类型 12 sc.setLogLevel("WARN") 13 14 // 读取文件 15 val fileRDD = sc.textFile("datas/words") 16 17 // 将文件数据进行分词,按空格切分为单个词 18 val wordRDD = fileRDD.flatMap(_.split(" ")) 19 20 // 转换数据结构 word => (word,1),每个词标记为1 21 val word2OneRDD = wordRDD.map((_,1)) 22 23 // 分组聚合,按词分组计数 24 val word2CountRDD = word2OneRDD.reduceByKey(_ + _) 25 26 // 直接输出,打印结果 27 println("============ 直接输出,打印结果 ============") 28 word2CountRDD.foreach(println) 29 30 // 把聚合结果采集到内存中,在输出 31 println("============ 把聚合结果采集到内存中,在输出 ============") 32 val collect = word2CountRDD.collect().toBuffer 33 collect.foreach(println) 34 35 // 保存到本地 , repartition指定分区个数为1时,结果为文件,否则为文件夹。 36 word2CountRDD.repartition(1).saveAsTextFile("datas/words/result") 37 // word2CountRDD.saveAsTextFile("datas/output/result") 38 39 println("已保存到本地: datas/words/result") 40 41 // 关闭连接 42 sc.stop() 43 44 println("执行结束") 45 } 46 }
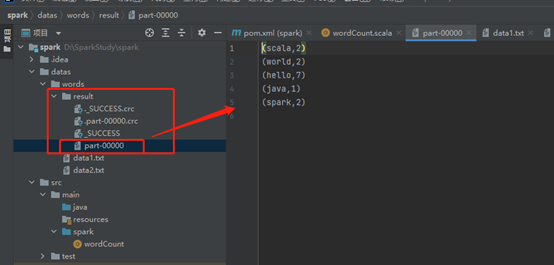
执行结果
posted on 2022-05-26 13:50 Simple-Sir 阅读(809) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号