初识kafka 之 自定义分区器
需求
通过一个分区器实现,发送过来的数据中如果包含kafka,就发往0号分区,不包含kafka,就发往1号分区。
代码实现
分区器
package com.lzh.kafka; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; // 自定义分区器 /* 需求 通过一个分区器实现,发送过来的数据中如果包含kafka,就发往0号分区,不包含kafka,就发往1号分区。 代码写好之后,复制类全面: com.lzh.kafka.MyPartitioner 在序列化时,指定分区器。 */ public class MyPartitioner implements Partitioner { public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) { // 获取数据 // 把获取到的数据转为String类型 String msgValues = o1.toString(); // 创建partition int partition; if (msgValues.contains("kafka")) { partition=0; }else { partition=1; } return partition; } public void close() { } public void configure(Map<String, ?> map) { } }
主体使用
package com.lzh.kafka; import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; import java.util.concurrent.ExecutionException; // 自定义分区器 /* 需求 通过一个分区器实现,发送过来的数据中如果包含kafka,就发往0号分区,不包含kafka,就发往1号分区。 代码写好之后,复制类全面: com.lzh.kafka.MyPartitioner 在序列化时,指定分区器。 */ public class CustomProducer自定义分区器 { public static void main(String[] args) throws ExecutionException, InterruptedException { // 1.配置 Properties properties = new Properties(); // 连接集群 // 给kafka对象添加配置信息 bootstrap.servers // 生产者连接集群所需的 broker 地址清单 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092,bigdata02:9092"); // 指定发送消息的key和value的序列化类型。一定要写全类名。 // key,value序列化 key.serializer,value.serializer // key序列化 // 全类名与下等价: properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // value序列化 properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); // 指定自定义分区器 properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.lzh.kafka.MyPartitioner"); // 2.创建 kafka 生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties); // 3.发送数据 // 调用 send 方法,发送消息 for (int i = 1; i < 5; i++) { final String msg; if (i % 2 == 0) { msg="hello kafka"; }else { msg="hello java"; } kafkaProducer.send(new ProducerRecord<String, String>("Mytopic", msg), new Callback() { public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e == null) { System.out.println(msg + "已发送到主题"+recordMetadata.topic() +"的"+ recordMetadata.partition() +"分区"); } } }); } // 4.关闭资源 kafkaProducer.close(); } }
附,类全名复制方法。
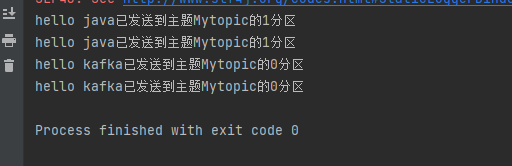
结果

世风之狡诈多端,到底忠厚人颠扑不破;
末俗以繁华相尚,终觉冷淡处趣味弥长。
posted on 2022-04-14 15:32 Simple-Sir 阅读(278) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号