初识kafka 之 分区策略
kafka 分区策略
1.指明partition的情况下,直接将指明的值作为partition值;
例如partition=0,所有数据写入分区0
2.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值;
例如:key1的hash值=5, key2的hash值=6 ,topic的partition数=2,那么key1对应的value1写入1号分区,key2对应的value2写入0号分区。
例如:要把一张表的数据入到同一个分区,可以指定key的值为该表名
3.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进行使用(如果还是0会继续随机)。
代码实现
package com.lzh.kafka; import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; import java.util.concurrent.ExecutionException; /* kafka 分区策略 1.指明partition的情况下,直接将指明的值作为partition值; 例如partition=0,所有数据写入分区0 2.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值; 例如:key1的hash值=5, key2的hash值=6 ,topic的partition数=2,那么key1对应的value1写入1号分区,key2对应的value2写入0号分区。 例如:要把一张表的数据入到同一个分区,可以指定key的值为该表名 3.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区, 待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。 例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进行使用(如果还是0会继续随机)。 */ public class CustomProducerPartition { public static void main(String[] args) throws ExecutionException, InterruptedException { // 1.配置 Properties properties = new Properties(); // 连接集群 // 给kafka对象添加配置信息 bootstrap.servers // 生产者连接集群所需的 broker 地址清单 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092,bigdata02:9092"); // 指定发送消息的key和value的序列化类型。一定要写全类名。 // key,value序列化 key.serializer,value.serializer // key序列化 // 全类名与下等价: properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // value序列化 properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); // 2.创建 kafka 生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties); // 3.发送数据 // 调用 send 方法,发送消息 // 指定分区 partition for (int i = 1; i < 5; i++) { kafkaProducer.send(new ProducerRecord<String, String>("Mytopic",3,"","" + i), new Callback() { // 有回调函数 public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e == null) { System.out.println("主题"+ recordMetadata.topic() +"已异步发送消息到指定分区"+ recordMetadata.partition()); } } }); } // 指定 key,把同一张的数据入到同一个分区 key就是表名 for (int i = 1; i < 10; i++) { final int n; n=i; kafkaProducer.send(new ProducerRecord<String, String>("Mytopic","tab_name","记录"+i), new Callback() { // 有回调函数 public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e == null) { System.out.println("表tab_name的第"+ n +"条记录已发送到主题" + recordMetadata.topic() + "的指定分区" + recordMetadata.partition()); } } }); } // 4.关闭资源 kafkaProducer.close(); } }
结果
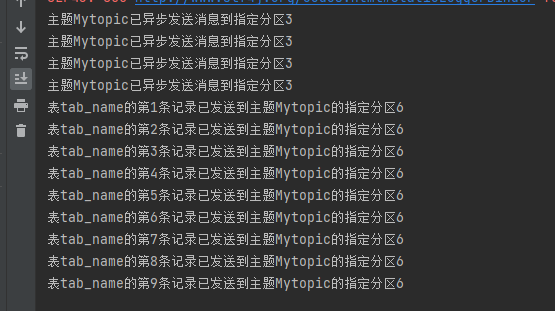
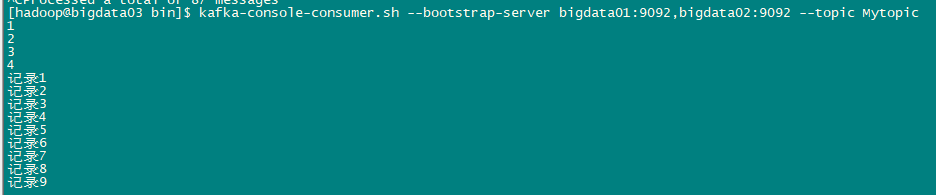
世风之狡诈多端,到底忠厚人颠扑不破;
末俗以繁华相尚,终觉冷淡处趣味弥长。
posted on 2022-04-14 15:23 Simple-Sir 阅读(837) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号