hadoop 之 spark on yarn 安装
目录规划
Hadoop、spark都放在/apps下。
角色规划

官网下载
https://spark.apache.org/downloads.html
压缩包存放目录
/apps/software/spark-3.0.1-bin-hadoop2.7.tgz
开始安装
解压
cd /apps/software/ tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz -C /apps/
重命名
mv spark-3.0.1-bin-hadoop2.7 spark-3.0.1
配置Yarn历史服务器并关闭资源检查
vi /apps/hadoop-2.10.1/etc/hadoop/yarn-site.xml
<!-- 开启日志聚合功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置聚合日志在hdfs上的保存时间 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://bigdata02:19888/jobhistory/logs</value> </property> <!-- 关闭yarn内存检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
配置Spark的历史服务器和Yarn的整合spark-defaults.conf
cd /apps/spark-3.0.1/conf/ mv spark-defaults.conf.template spark-defaults.conf vi spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://ns1/sparklog/ spark.eventLog.compress true spark.yarn.historyServer.address bigdata02:18080
修改spark-env.sh
cd /apps/spark-3.0.1/conf/ mv spark-env.sh.template spark-env.sh vi spark-env.sh
## 设置JAVA安装目录 JAVA_HOME=/apps/jdk1.8.0_271 ## HADOOP、yarn配置文件目录,读取HDFS上文件和运行Spark在YARN集群时需要 HADOOP_CONF_DIR=/apps/hadoop-2.10.1/etc/hadoop YARN_CONF_DIR=/apps/hadoop-2.10.1/etc/hadoop ## 指定spark老大Master的IP和提交任务的通信端口 # SPARK_MASTER_HOST= SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=1g SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata01:2181,bigdata02:2181,bigdata03:2181 -Dspark.deploy.zookeeper.dir=/spark-ha" ## 配置spark历史日志存储地址 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://ns1/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
创建spark日志目录
hadoop fs -mkdir -p /sparklog
修改日志级别(可忽略)
cd /apps/spark-3.0.1/conf mv log4j.properties.template log4j.properties vi log4j.properties
#log4j.rootCategory=INFO, console
log4j.rootCategory=WARN, console
配置依赖的Spark的jar包(上传spark的所有jar包到集群)
在HDFS上创建存储spark相关jar包的目录
hadoop fs -mkdir -p /spark/jars/
上传$SPARK_HOME/jars所有jar包到HDFS
hadoop fs -put /apps/spark-3.0.1/jars/* /spark/jars/
修改spark-defaults.conf
vi /apps/spark-3.0.1/conf/spark-defaults.conf
spark.yarn.jars hdfs://ns1/spark/jars/*
启动
启动集群 (bigdata01操作)
start-all.sh
启动yarn (bigdata02, bigdata03操作)
yarn-daemon.sh start resourcemanager
启动MRHistoryServer服务 (bigdata02操作)
mr-jobhistory-daemon.sh start historyserver
启动Spark HistoryServer服务(bigdata02操作)
/apps/spark-3.0.1/sbin/start-history-server.sh
查看WEB UI页面
MRHistoryServer服务WEB UI页面:
Spark HistoryServer服务WEB UI页面:
测试
自带测试例子,圆周率PI计算程序:
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar
client模式
10 是指要求的pi值的精度
SPARK_HOME=/apps/spark-3.0.1 ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode client \ --driver-memory 512m \ --driver-cores 1 \ --executor-memory 512m \ --num-executors 2 \ --executor-cores 1 \ --class org.apache.spark.examples.SparkPi \ ${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \ 10
结果直接在当前窗口查看

cluster模式
SPARK_HOME=/apps/spark-3.0.1 ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --driver-memory 512m \ --executor-memory 512m \ --num-executors 1 \ --class org.apache.spark.examples.SparkPi \ ${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \ 10
结果在yarn日志查看
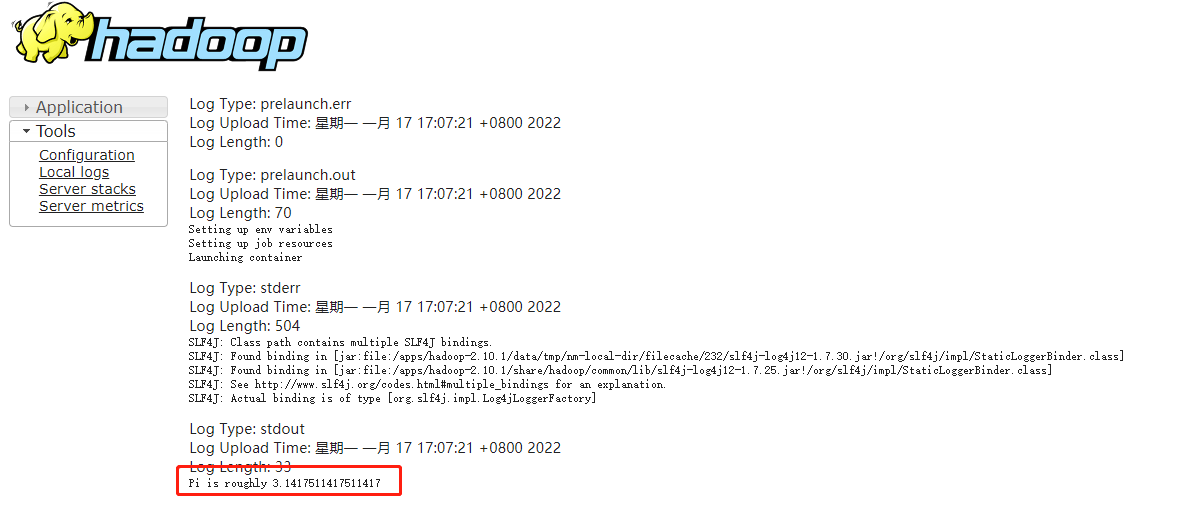
OK,安装完成!
世风之狡诈多端,到底忠厚人颠扑不破;
末俗以繁华相尚,终觉冷淡处趣味弥长。
posted on 2022-01-17 18:00 Simple-Sir 阅读(835) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号