
Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页
下载下面这个链接的销售数据
https://item.jd.com/6733026.html#comment
1、 翻页的时候,谷歌F12的Network页签可以看到下面的请求。(这里的翻页指商品评价中1、2、3页等)
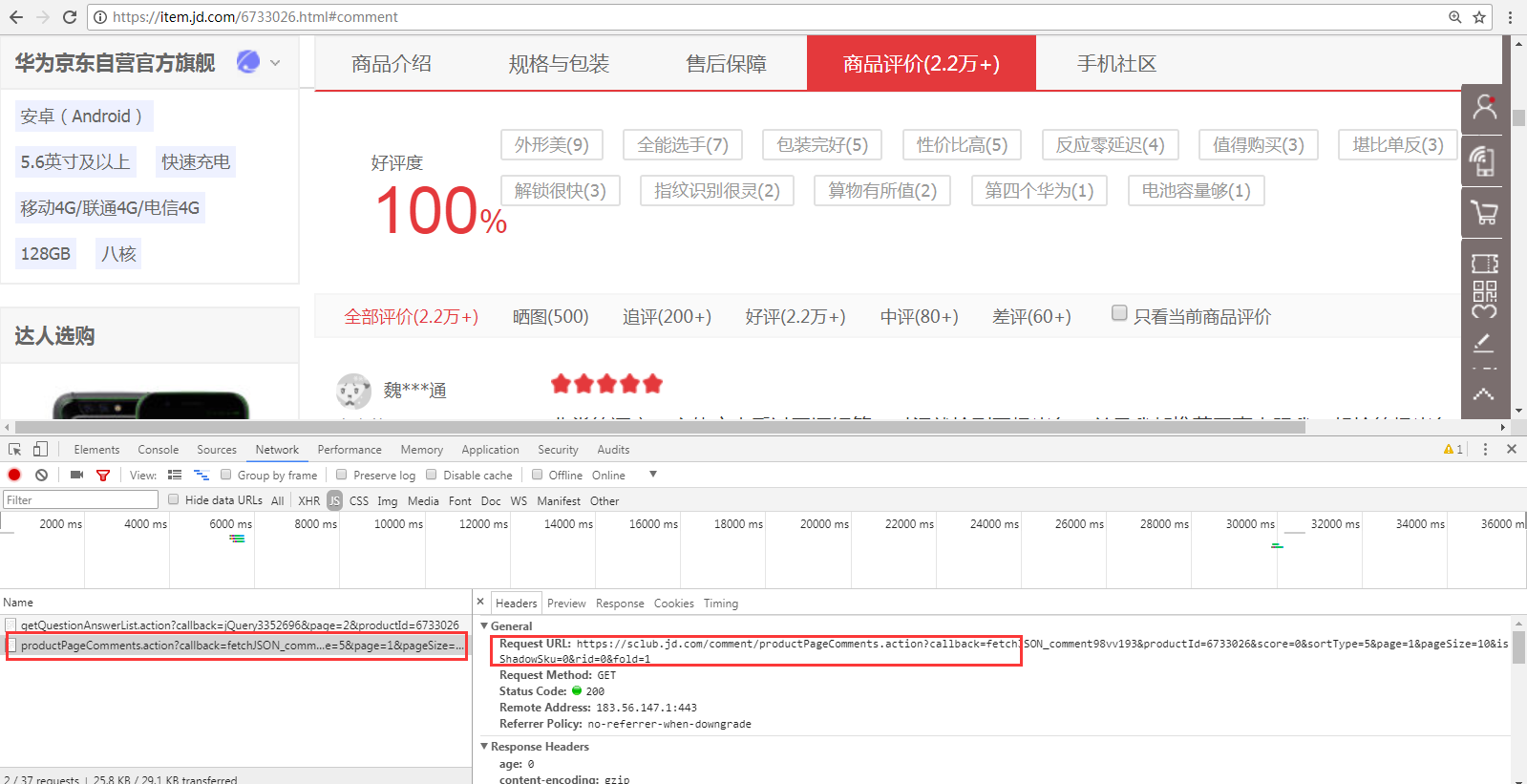
从Preview页签可以看出,这个请求是获取评论信息的
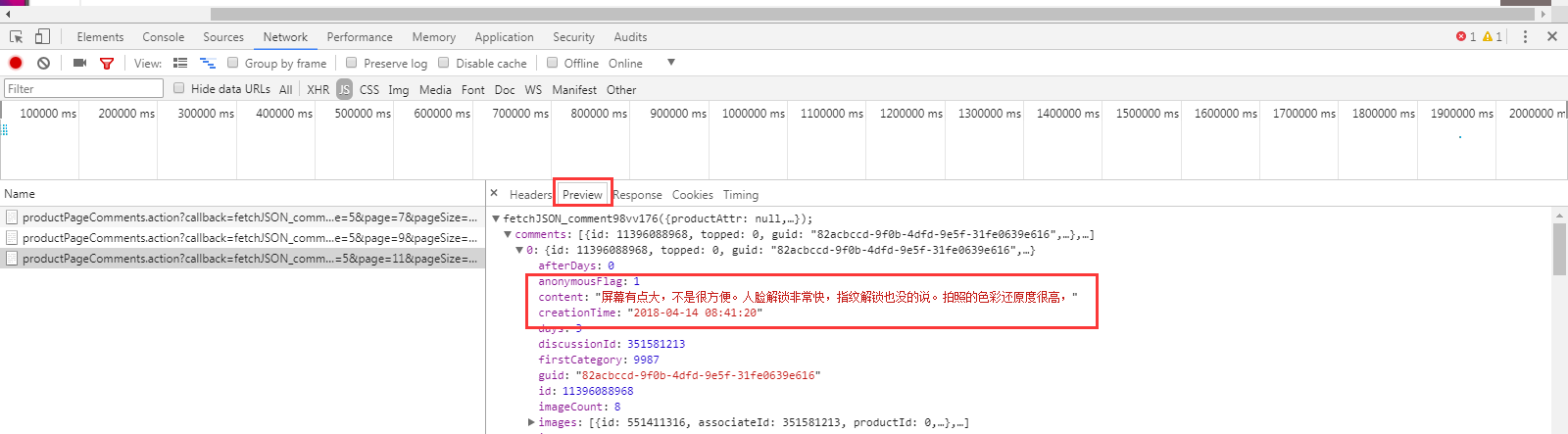
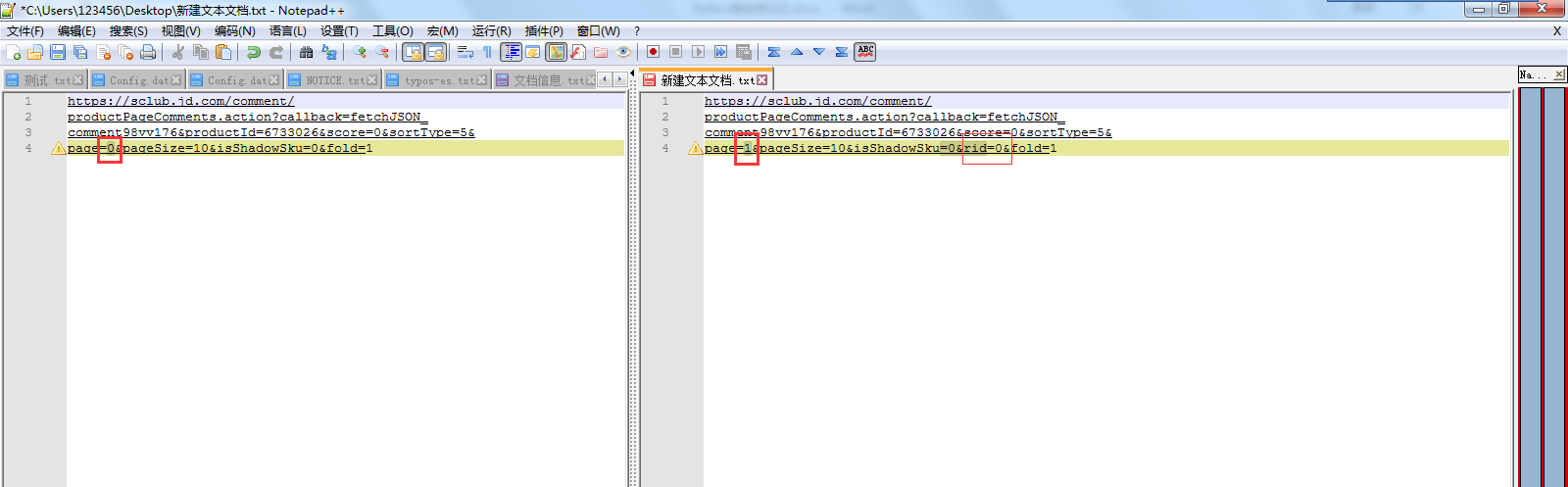
2、 对比第一页、第二页、第三页…请求URL的区别
可以发现 page=0、page=1,0和1指的应该是页数。
第一页的 request url:没有这个rid=0& 。 第二、三页…的request url:多了这个rid=0&
除了上面这2个地方,其他内容都是一样的。
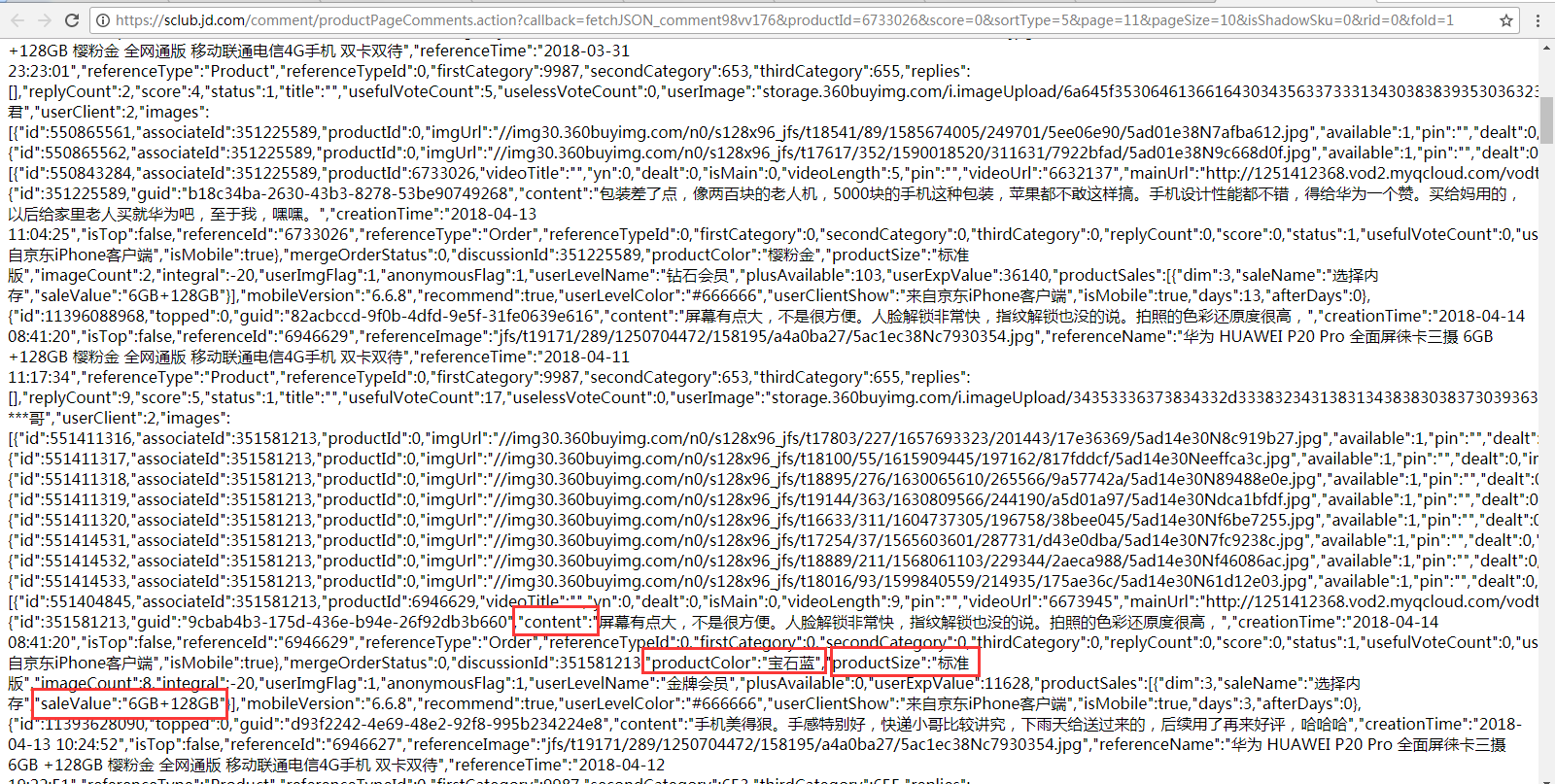
3、 直接在浏览器输入 复制出来的request url,可以看到评论、颜色、版本、内存信息,代码将根据这些信息来写正则表达式进行匹配。
(二) 实现代码
delayed.py的代码和我前面发的是一样的(Python网络爬虫笔记(二)),不限速的话把和这个模块相关的代码删除就行了
1 import urllib.request as ure 2 import urllib.parse 3 import openpyxl 4 import re 5 import os 6 from delayed import WaitFor 7 def download(url,user_agent='FireDrich',num=2,proxy=None): 8 print('下载:'+url) 9 #设置用户代理 10 headers = {'user_agent':user_agent} 11 request = ure.Request(url,headers=headers) 12 #支持代理 13 opener = ure.build_opener() 14 if proxy: 15 proxy_params = {urllib.parse.urlparse(url).scheme: proxy} 16 opener.add_handler(ure.ProxyHandler(proxy_params)) 17 try: 18 #下载网页 19 # html = ure.urlopen(request).read() 20 html = opener.open(request).read() 21 except ure.URLError as e: 22 print('下载失败'+e.reason) 23 html=None 24 if num>0: 25 #遇到5XX错误时,递归调用自身重试下载,最多重复2次 26 if hasattr(e,'code') and 500<=e.code<600: 27 return download(url,num=num-1) 28 return html 29 def writeXls(sale_list): 30 #如果Excel不存在,创建Excel,否则直接打开已经存在文档 31 if 'P20销售情况.xlsx' not in os.listdir(): 32 wb =openpyxl.Workbook() 33 else: 34 wb =openpyxl.load_workbook('P20销售情况.xlsx') 35 sheet = wb['Sheet'] 36 sheet['A1'] = '颜色' 37 sheet['B1'] = '版本' 38 sheet['C1'] = '内存' 39 sheet['D1'] = '评论' 40 sheet['E1'] = '评论时间' 41 x = 2 42 #迭代所有销售信息(列表) 43 for s in sale_list: 44 #获取颜色等信息 45 content = s[0] 46 creationTime = s[1] 47 productColor = s[2] 48 productSize = s[3] 49 saleValue = s[4] 50 # 将颜色等信息添加到Excel 51 sheet['A' + str(x)] = productColor 52 sheet['B' + str(x)] = productSize 53 sheet['C' + str(x)] = saleValue 54 sheet['D' + str(x)] = content 55 sheet['E' + str(x)] = creationTime 56 x += 1 57 wb.save('P20销售情况.xlsx') 58 59 page = 0 60 allSale =[] 61 waitFor = WaitFor(2) 62 #预编译匹配颜色、版本、内存等信息的正则表达式 63 regex = re.compile('"content":"(.*?)","creationTime":"(.*?)".*?"productColor":"(.*?)","productSize":"(.*?)".*?"saleValue":"(.*?)"') 64 #这里只下载20页数据,可以设置大一些(因为就算没评论信息,也能下载到一些标签信息等,所以可以if 正则没匹配的话就结束循环,当然,下面没处理这个) 65 while page<20: 66 if page==0: 67 url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv176&productId=6733026&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&fold=1' 68 else: 69 url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv176&productId=6733026&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&rid=0&fold=1' 70 waitFor.wait(url) 71 html = download(url) 72 html = html.decode('GBK') 73 #以列表形式返回颜色、版本、内存等信息 74 sale = regex.findall(html) 75 #将颜色、版本、内存等信息添加到allSale中(扩展allSale列表) 76 allSale.extend(sale) 77 page += 1 78 79 writeXls(allSale)
(三) 数据分析
1、 下载后的数据如下图所示。

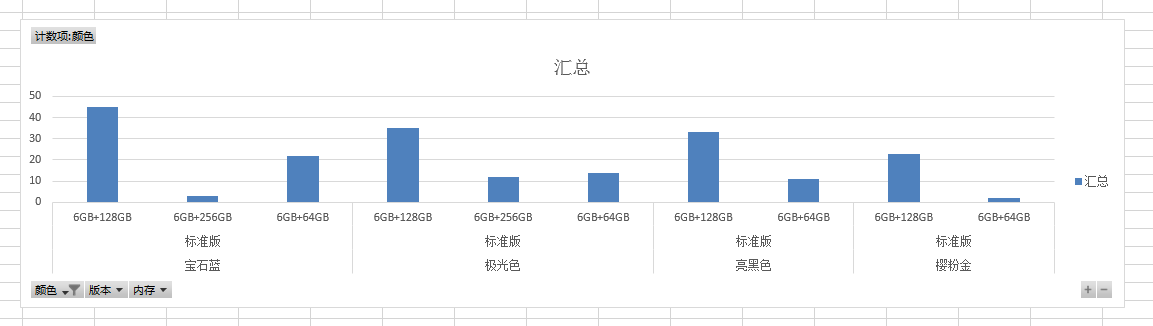
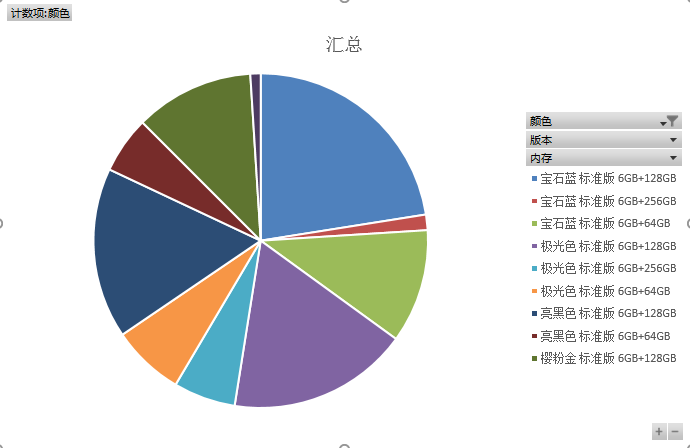
2、 生成图表。
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3ff1njli6hwk0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号