kafka特性和集群
kafka特性和集群
一: kafka特性介绍
-
Topic
让我们首先深入了解下Kafka的核心概念:提供一串流式的记录
Topic 就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka中的Topics是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
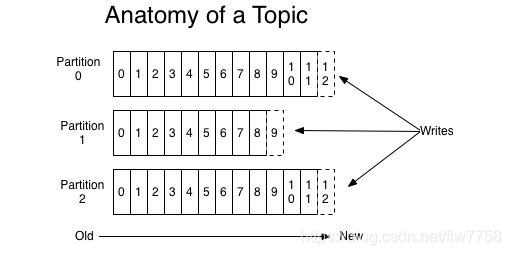
对于每一个topic, Kafka集群都会维持一个分区日志,如下所示:
![]()
每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的commit log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset,offset用来唯一的标识分区中每一条记录。
Kafka 集群保留所有发布的记录—无论他们是否已被消费—并通过一个可配置的参数——保留期限来控制. 举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被抛弃并释放磁盘空间。Kafka的性能和数据大小无关,所以长时间存储数据没有什么问题.
事实上,在每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置.偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从"现在"开始消费。
这些细节说明Kafka 消费者是非常廉价的—消费者的增加和减少,对集群或者其他消费者没有多大的影响。比如,你可以使用命令行工具,对一些topic内容执行 tail操作,并不会影响已存在的消费者消费数据。
日志中的 partition(分区)有以下几个用途。第一,当日志大小超过了单台服务器的限制,允许日志进行扩展。每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此可以处理无限量的数据。第二,可以作为并行的单元集—关于这一点,更多细节如下
-
分布式
日志的分区partition (分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性.
每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。
-
生产者
生产者可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(例如:记录中的key)来完成。下面会介绍更多关于分区的使用。
-
消费者
消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.
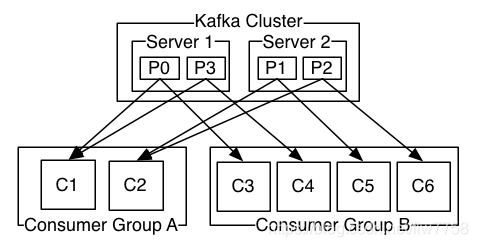
![]()
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个"逻辑订阅者"。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
单播消费
一条消息只能被某一个消费者消费的模式,类似queue模式,只需让所有消费者在同一个消费组里即可分别在两个客户端执行如下消费命令,然后往主题里发送消息,结果只有一个客户端能收到消息bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-propertygroup.id=testGroup --topic test多播消费
一条消息能被多个消费者消费的模式,类似publish-subscribe模式费,针对Kafka同一条消息只能被同一个消费组下的某一个消费者消费的特性,要实现多播只要保证这些消费者属于不同的消费组即可。我们再增加 一个消费者,该消费者属于testGroup-2消费组,结果两个客户端都能收到消息。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-propertygroup.id=testGroup-2--topic test
二:kafka 集群
环境准备(下载地址都在官方文档)
由于Kafka是用Scala语言开发的,运行在JVM上,因此在安装Kafka之前需要先安装JDK。
yum install java-1.8.0-openjdk* -y
kafka依赖zookeeper,所以需要先安装zookeeper
# 安装zooKeeper
wget http://mirror.bit.edu.cn/apache/zookeeper/stable/zookeeper-3.4.12.tar.gz
tar zxvf zookeeper-3.4.12.tar.gz
cd zookeeper-3.4.12
cp conf/zoo_sample.cfg conf/zoo.cfg
#启动zookeeper客户端(kafka自带zookeeper没有客户端的无法查看节点,这是自己安装zookeeper的原因)
bin/zkServer.sh start conf/zoo.cfg &
bin/zkCli.sh
ls
下载kafka安装包
#下载1.1.0 release版本,并解压:
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/1.1.0/kafka 2.11-1.1.0.tgz
tar -xzf kafka_2.11-1.1.0.tgz
#进入kafka
cd kafka_2.11-1.1.0
启动kafka服务
启动脚本语法: kafka-server-start.sh[-daemon] server.properties
可以看到,server.properties的配置路径是一个强制的参数,-daemon表示以后台进程运行,否则ssh客端退出后,就会停止服务。(注意,在启动kafka时会使用linux主机名关联的ip地址,所以需要把主机名配到本地host里,用vim /etc/hosts)
bin/kafka-server-start.sh -daemon config/server.properties
#我们进入zookeeper目录通过zookeeper客户端查看下zookeeper的目录树
bin/zkCli.sh
ls /
#查看zk的根目录kafka相关节点
ls /brokers/ids
集群配置
到目前为止,我们都是在一个单节点上运行broker,这并没有什么意思。对于kafka来说,一个单独的
broker意味着kafka集群中只有一个接点。要想增加kafka集群中的节点数量,只需要多启动几个broker实例即可。为了有更好的理解,现在我们在一台机器上同时启动三个broker实例。
首先,我们需要建立好其他2个broker的配置文件:
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
# 配置文件需要修改的内容
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT:/ / : 9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094log.dir=/tmp/kafka-logs-2
broker.id属性在kafka集群中必须要是唯一的。我们需要重新指定port和log目录,因为我们是在同一台机器上运行多个实例。如果不进行修改的话,consumer只能获取到一个instance实例的信息,或者是相互之间的数据会被影响。
启动节点,加上我们原来的一个节点,就是组成了三个节点的kafka集群了,我们这里就不在对zookeeper做集群搭建了。
bin/kafka-server-start.sh config/server-1.properties &
bin/kafka-server-start.sh config/server-2.properties &
kafka的集群搭建是很简单,通过简单配置就可以搭建集群。
下面我们船舰一个topic看看集群的信息
创建topic
# 创建只有一个partitions的主题名称为my-replicated-topic的主题, partition复制因子是3的(这里只有三个节点,最多三个)
bin/kafka-topics.sh --create --zookeeper localhost:2181--replication-factor 3 --partitions 1 --topic my-replicated-topic
# 查看主题信息
bin/kafka-topics.sh --describe --zookeeper localhost2181 --topic my-replicated-topic
#现在我们可以通过以下命令来查看kafka中目前存在的topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
#发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
通过命令查看topic:my-replicated-topic的集群信息

-
PartitionCount:1
意思:partition的个数是一个
-
ReplicationFactor:3 复制因子是3
表示flower是3个(包含leader)
-
leader节点:2
表示这个partition的learder是id为2的节点
-
Replicas:2,0,1
表示是副本
-
Isr:2,0,1
表示已经同步的副本
停止Leader(第二个节点)进程
-
找到server-2的进程
#找到进程 ps -ef|grep server-2.pro #停止进程 kill 3816 -
查看topic信息
![]()
可以看到Leader 已经变成了0,我们Replicas:2,0,1,但是我们已经同步的副本Isr变成了0,1

新建一个两个分区的topic
-
新建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 2 --topic my-replicated-topic-new -
查看集群信息
命令:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replica-topic-new![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号