
ssj兼职数据Django+pyecharts可视化展示
展示结果

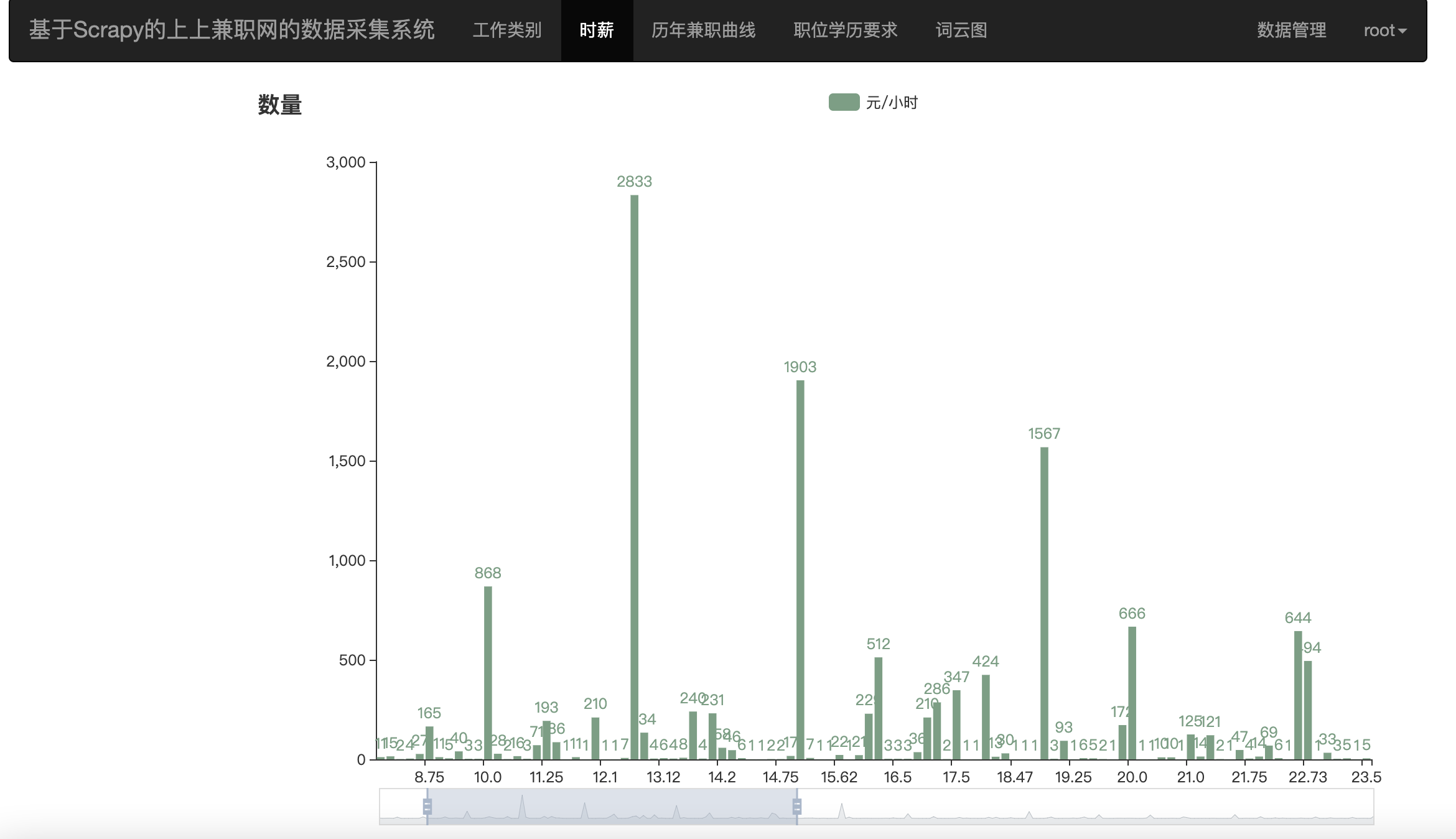
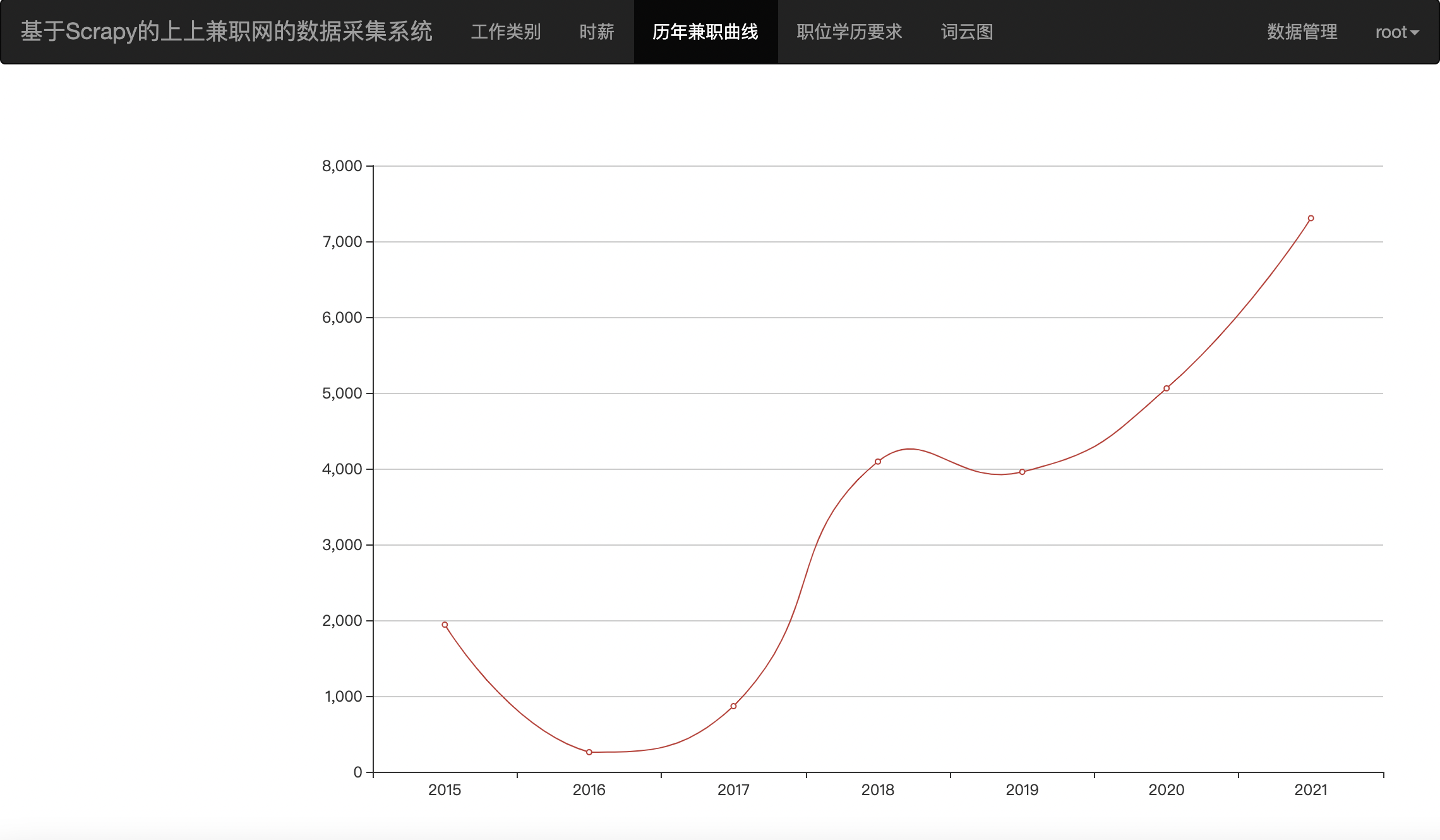
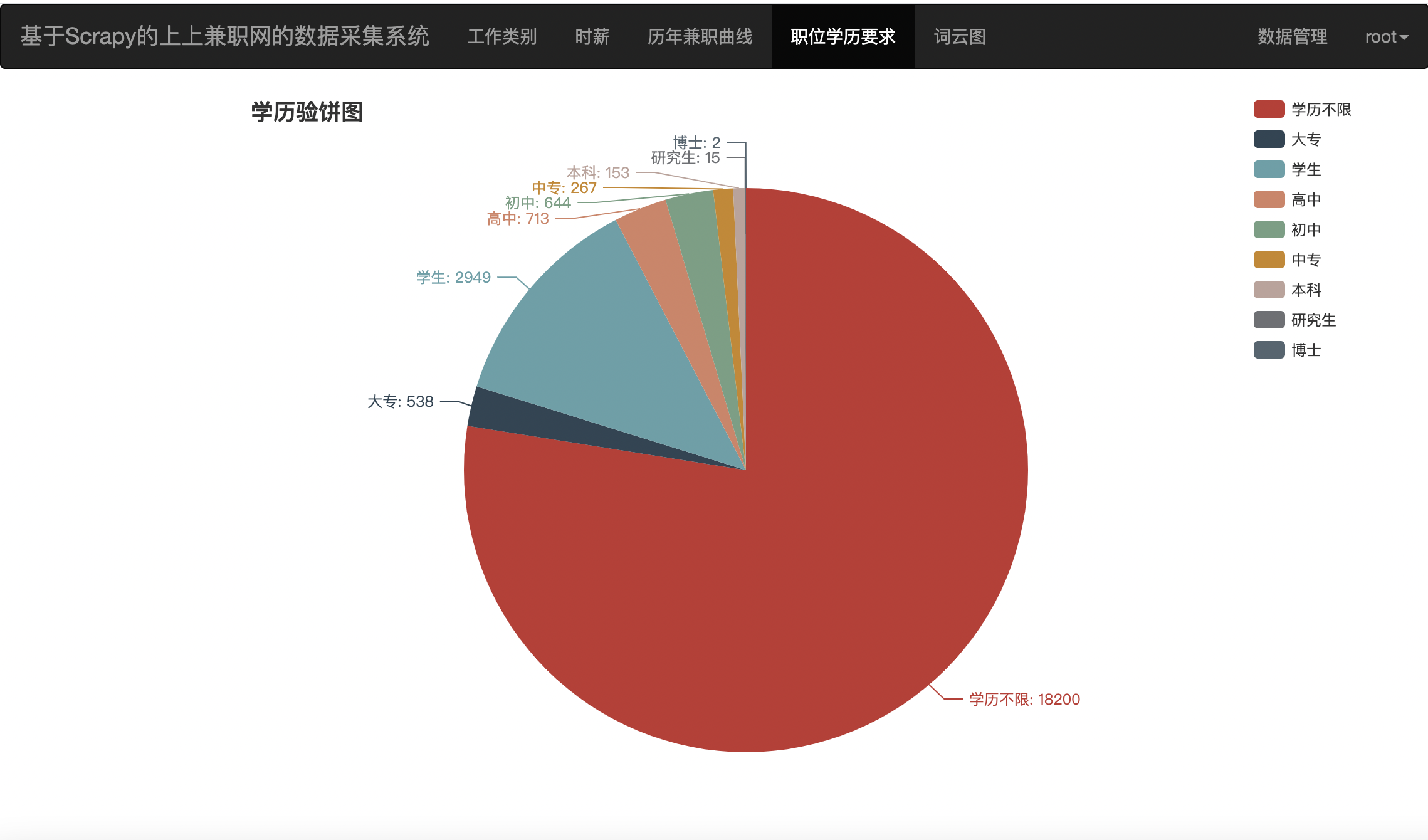

针对以上几种图分别使用的是
from pyecharts.charts import Bar, WordCloud, Line,Pie# 分别是 柱状图 词云 折现(曲线) 饼图
前端使用的是Django模板语言 加载同一种模板 使用Ajax从后端获取生成的图的json信息
第一个Bar的代码可以如下所示
def bar_salary() -> Bar():
ress = partJobInfo.objects.all()
salary_list = []
salary_dic = {}
for i in ress:#这个for循环就是统计单价的所有信息
if i.price and 5 <= i.price <= 200:#这里去除脏数据
if i.price in salary_dic:
salary_dic[i.price] += 1
else:
salary_dic[i.price] = 1
x = sorted(list(salary_dic.keys()))
y = [salary_dic[i] for i in x]
x = [str(i) for i in x] #要求输入的数据是字符串需要格式化一次
try:
salary_bar = (
Bar()
.add_xaxis(x)
.add_yaxis("元/小时", y, color=Faker.rand_color())
.set_global_opts(
title_opts=opts.TitleOpts(title="数量"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
)
.dump_options_with_quotes()
)
except Exception as e:
print(e)
return
return salary_bar
饼图按照如下所示的代码返回json数据到前端 前端使用这个数据进行可视化
def education_Pie() -> Pie():
ress = partJobInfo.objects.all()
education_dic = {}
for i in ress:
if i.education in education_dic:
education_dic[i.education] += 1
else:
education_dic[i.education] = 1
c = (
Pie()
.add(
"",
list(education_dic.items())
,
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="学历验饼图"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.dump_options_with_quotes()
)
return c
Line的曲线图可以参照如下所示的代码
def district_Line() -> Line():
ress = partJobInfo.objects.filter()
dateTime_dic = {}
for i in ress:
if i.dateTime.year in dateTime_dic:
dateTime_dic[i.dateTime.year] += 1
else:
dateTime_dic[i.dateTime.year] = +1
x_data = [i for i in dateTime_dic.keys()]
y_data = [dateTime_dic[i] for i in x_data]
x_data = sorted(x_data)
x_data = [str(i) for i in x_data]
print(x_data)
print(y_data)
c = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=False),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="",
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
is_smooth=True,
label_opts=opts.LabelOpts(is_show=False),
)
.dump_options_with_quotes()
)
return c
词云图的计算非常消耗资源为了减少计算资源 按照如下 先生成词云所需要的wordCloud.json文件 然后在每一次点击对应页面的时候,直接加载wordCloud.json文件进行可视化生成
就按照如下的代码
def worldCloudmy():
import jieba
from sklearn.feature_extraction.text import CountVectorizer
ress = partJobInfo.objects.all()#filter(~Q(positionDesc='desc'))
content = ''
for s in ress:
content += s.desc
comment_after_split = jieba.cut(str(content), cut_all=False)
wl_space_split = " ".join(comment_after_split)
cv = CountVectorizer()
words = []
contents_count = cv.fit_transform([wl_space_split])
# 词有哪些
list1 = cv.get_feature_names()
# 词的频率
list2 = contents_count.toarray().tolist()[0]
contents_dict = dict(zip(list1, list2))
for key, value in contents_dict.items():
words.append((key, value))
json_path = os.path.join(base_dir,"app01","wordCloud.json")
with open(json_path,"w", encoding="utf8") as f:
f.write(json.dumps(words, ensure_ascii=False))
def word_cloud() -> WordCloud():
json_path = os.path.join(base_dir, "wordCloud.json")
with open(json_path, "r", encoding="utf8") as f:
word = json.load(f)
c = (
WordCloud()
.add(
"",
word,
word_size_range=[20, 100],
textstyle_opts=opts.TextStyleOpts(font_family="cursive"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="WordCloud"))
.dump_options_with_quotes()
)
return c
价格数据清洗的代码如下所示
import re
class PriceProcess:
def __init__(self):
self.result = partJobInfo.objects.all()
def update_salary(self):
for i in self.result:
if "元/小时" in i.salary:
hours = re.findall(r'\d+', i.salary)
if hours:
i.price = float(self.processing(hours))
i.save()
else:
pass
elif "元/天" in i.salary:
day = re.findall(r'\d+', i.salary)
if day:
price = float(self.processing(day, 8))
i.price = round(price, 2)
i.save()
elif "元/月" in i.salary:
month = re.findall(r'\d+', i.salary)
if month:
price = float(self.processing(month, 22 * 8))
i.price = round(price, 2)
i.save()
else:
pass
else:
try:
i.price = re.findall(r'\d+', i.salary)[0]
i.save()
except Exception as e:
pass
def processing(self, i_data, num=1):
price_min = int(min(i_data))
price_max = int(max(i_data))
result_price = (price_max + price_min) / 2 / num
return result_price
django代码与浏览器交互模型
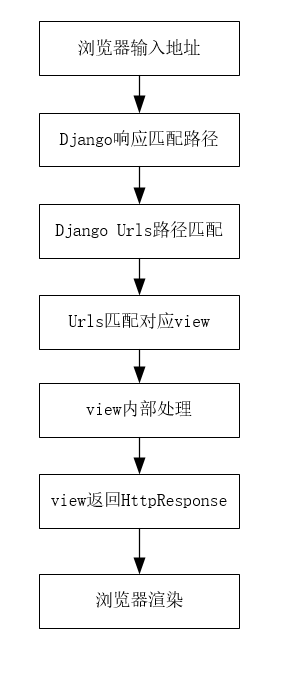
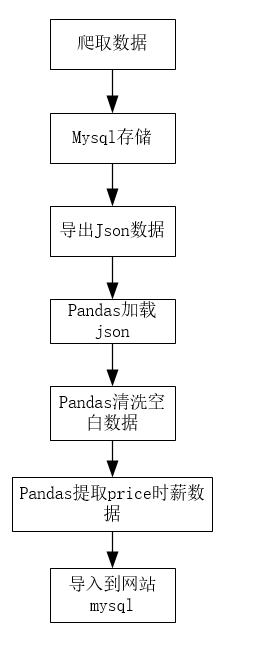
数据流程图
1. 用户通过浏览器请求一个页面
2. 请求到达Request Middlewares,中间件对request做一些预处理或者直接response请求
3. URLConf通过urls.py文件和请求的URL找到相应的View
4. View Middlewares被访问,它同样可以对request做一些处理或者直接返回response
5. 调用View中的函数
6. View中的方法可以选择性的通过Models访问底层的数据
7. 所有的Model-to-DB的交互都是通过manager完成的
8. 如果需要,Views可以使用一个特殊的Context
9. Context被传给Template用来生成页面
a. Template使用Filters和Tags去渲染输出
b. 输出被返回到View
c. HTTPResponse被发送到Response Middlewares
d. 任何Response Middlewares都可以丰富response或者返回一个完全不同的response
e. Response返回到浏览器,呈现给用户
其他详情请联系本人simp00@163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号