
ssj兼职网爬虫部分
一、scrapy模块

1、Scrapy Engine(引擎): 引擎负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发事件。
2、Scheduler(调度器): 调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
3、Downloader(下载器): 下载器负责获取页面数据并提供给引擎,而后提供给spider。
4、Spider(爬虫): Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
5、Item Pipeline(管道): Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存储到数据库中)。
6、Downloader Middlewares(下载中间件): 下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
7、Spider Middlewares(Spider中间件): Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
二、网站分析
1、网站首页 获取城市信息
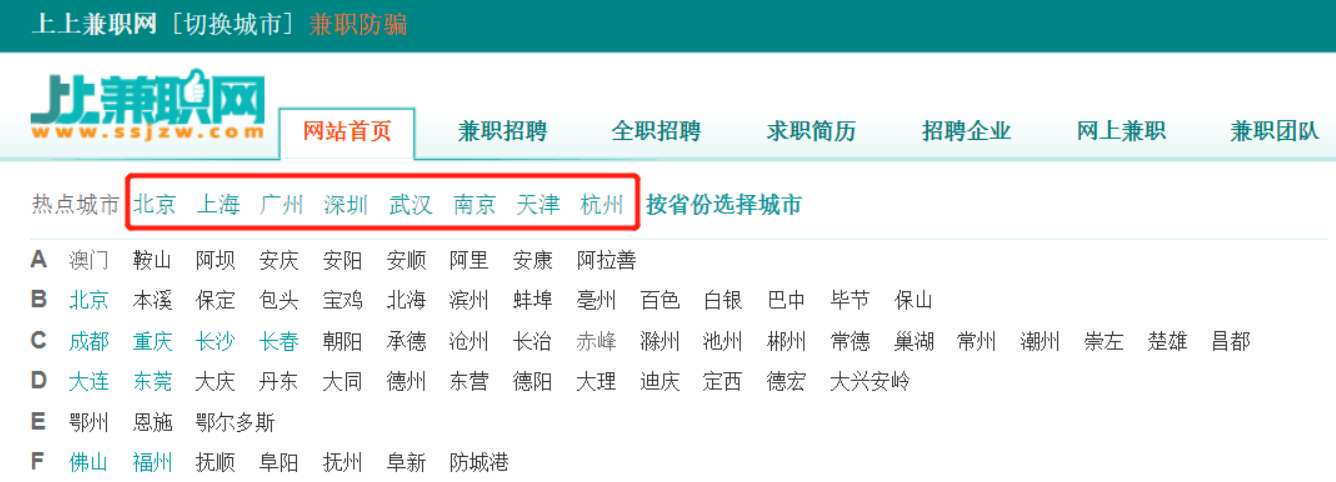
右键检查-->获取网站中城市url
2、选中城市获取分类
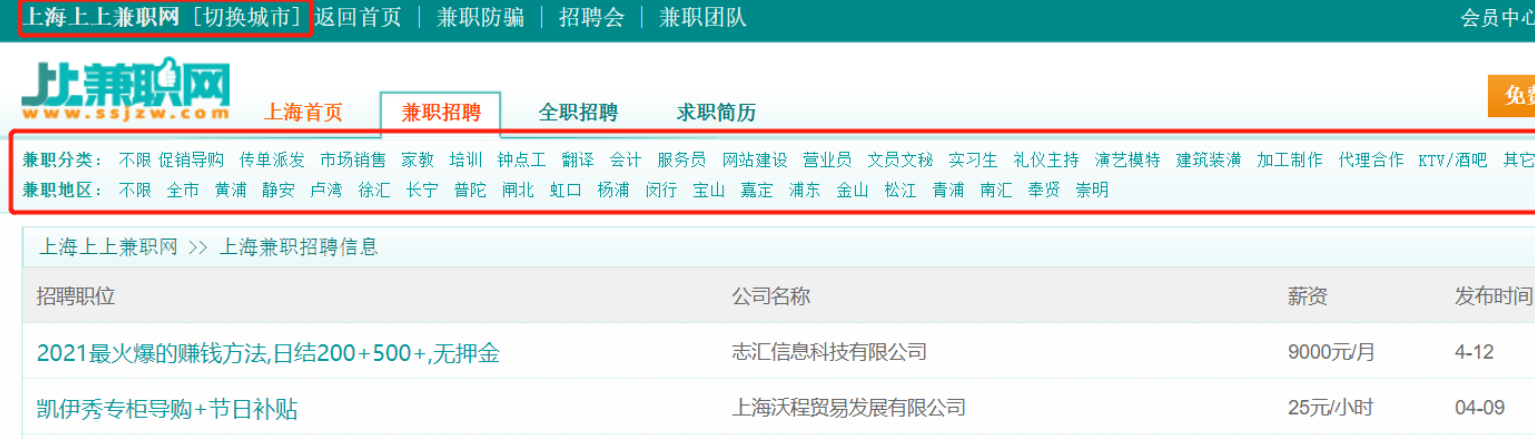
查看要获取的兼职标签
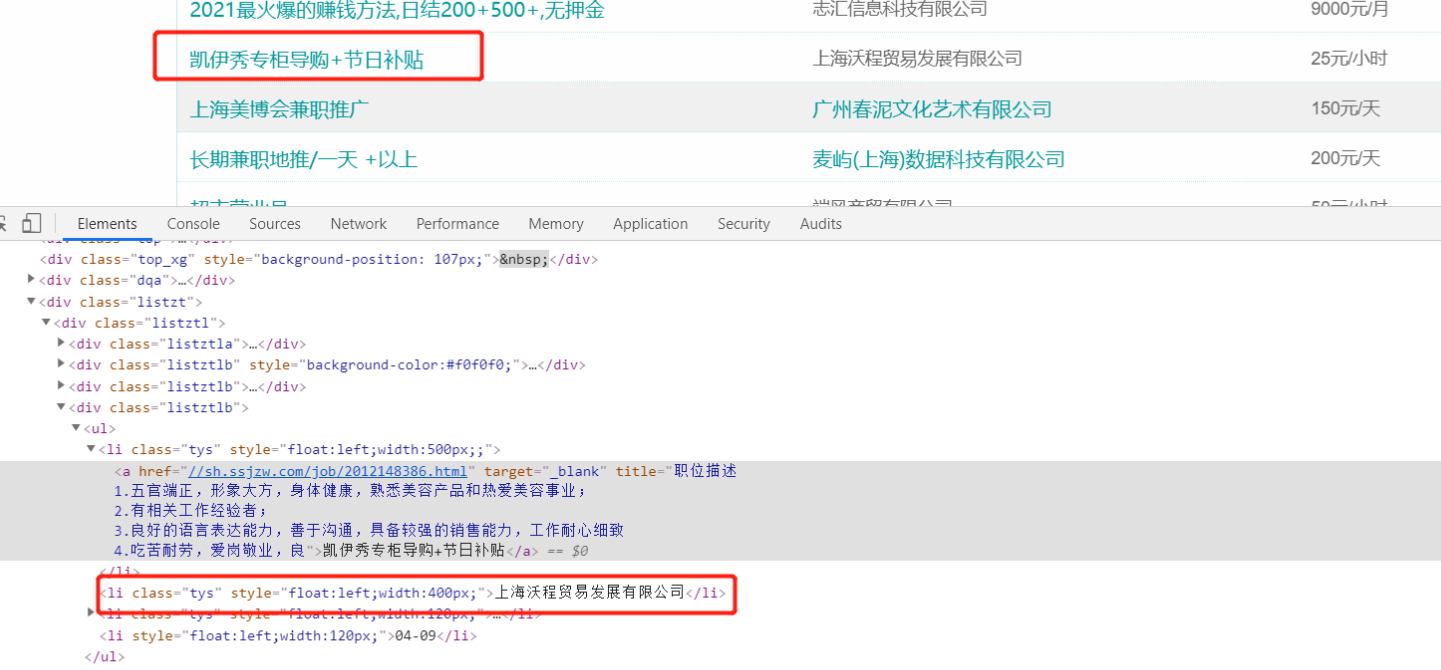
3、详情页数据
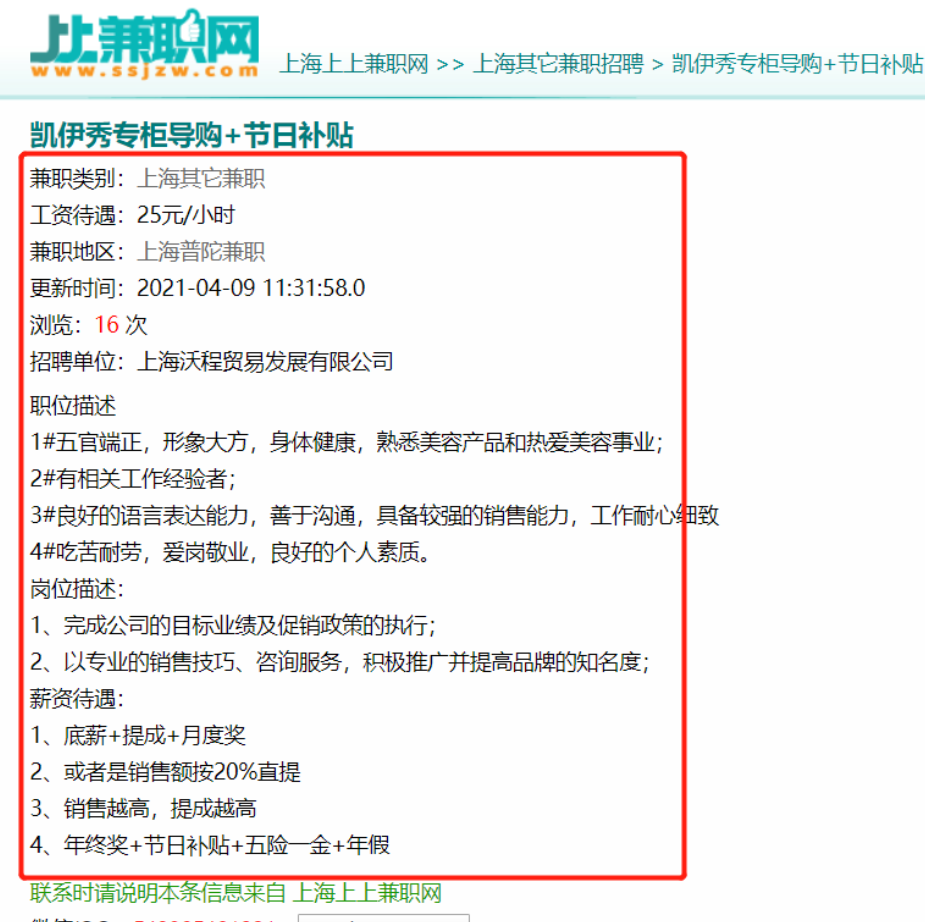
查看数据标签
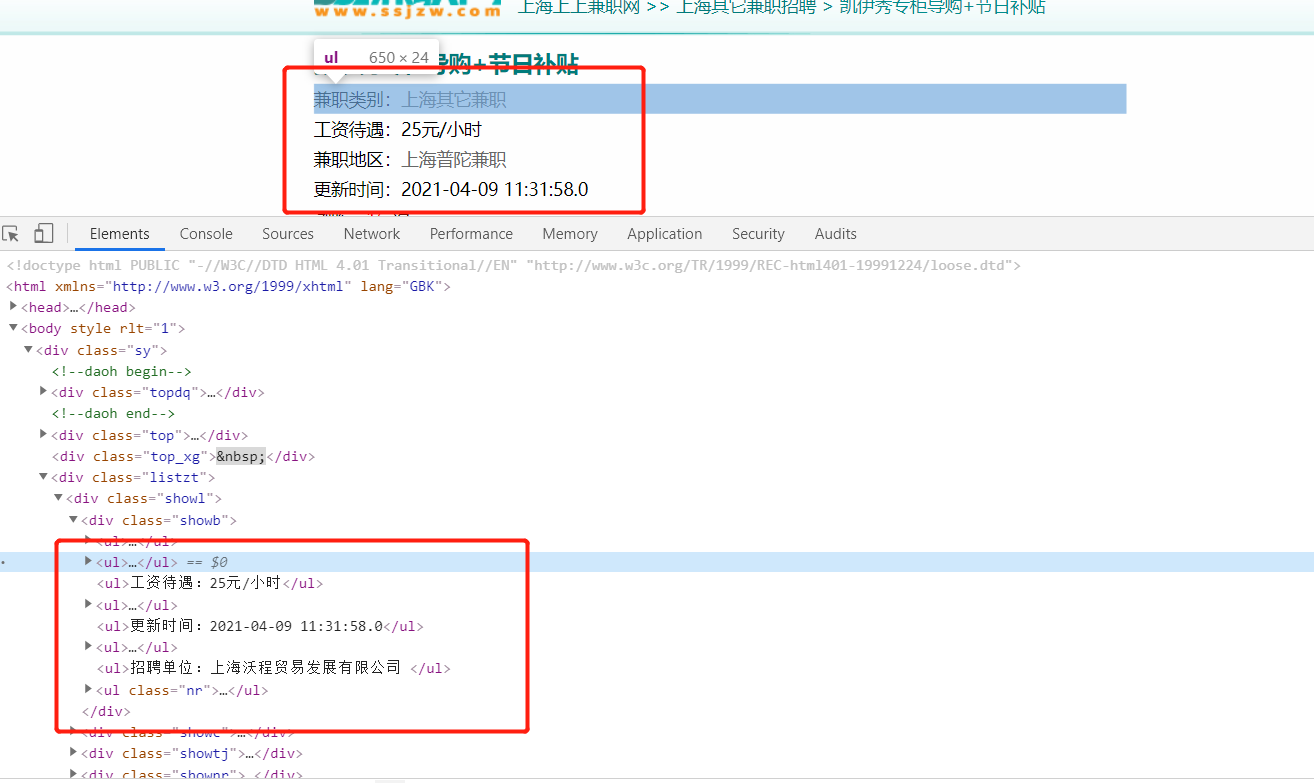
三、代码模块编写
1、创建项目SSQ
2、setting文件进行设置-已备注
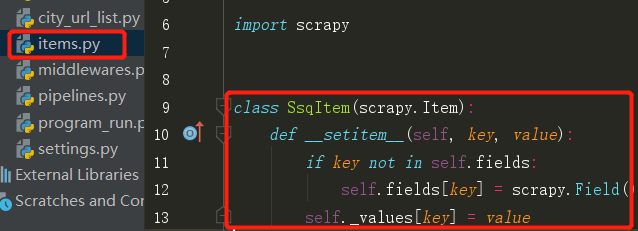
3、Scrapy为我们提供了Item类,这些Item类可以让我们自己来指定字段。比方说在我们这个Scrapy爬虫项目中,我们定义了一个Item类,这个Item里边包含了title、release_date、url等,这样的话通过各种爬取方法爬取过来的字段,再通过Item类进行实例化,这样的话就不容易出错了,因为我们在一个地方统一定义过了字段,而且这个字段具有唯一性。
这个Item有些类似我们常说的字典,但是它的功能要比字典更加齐全一些。同时当我们对Item进行实例化之后,在Spider爬虫主体文件里边,我们通过parse()函数获取到目标字段的Item类,我们直接将这个类进行yield即可,然后Scrapy在发现这是Item类的一个实例之后,它就会直接将这个Item载入pipeline中去。这样的话,我们就可以直接在pipeline中进行数据的保存、去重等操作。以上就是Item带给我们的好处。
4、主程序 --->重写了start_requests方法 将热点城市url传入函数
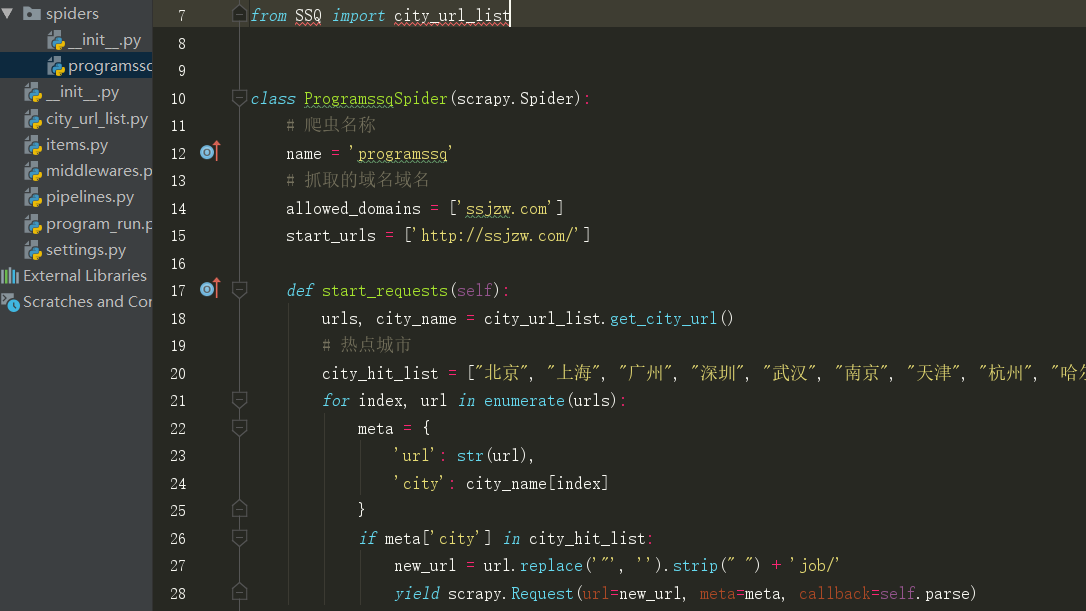
5、使用xpath ->解析获取的response使用xpath方法 获取//div[@class="dqa"]/ul/a 标签下的地区分类列表 和url xpat().getall()获取方法

6、其中也使用正则 获取详情页地址

7、使用xpath 获取想要的数据列表 最后将其传到管道 进行存储



 浙公网安备 33010602011771号
浙公网安备 33010602011771号