
#Python 文本包含函数,pandas库 Series.str.contains 函数
一:基础的函数组成
’’‘Series.str.contains(pat,case = True,flags = 0,na = nan,regex = True)’’'
测试pattern或regex是否包含在Series或Index的字符串中。
返回布尔值系列或索引,具体取决于给定模式或正则表达式是否包含在系列或索引的字符串中。
pat : str类型
字符序列或正则表达式。
case : bool,默认为True
如果为True,区分大小写。
flags : int,默认为0(无标志)
标志传递到re模块,例如re.IGNORECASE。
na : 默认NaN
填写缺失值的值。
regex : bool,默认为True
如果为True,则假定pat是正则表达式。
如果为False,则将pat视为文字字符串。
二:示例应用
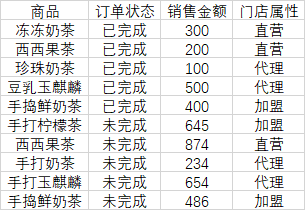
2.1 数据源展示
模拟一个奶茶销售表,包含商品名称,订单状态,销售金额,门店属性四个维度。
2.2 条件筛选(多列)
假设需求:目前需要直营门店、已完成状态的销售表
#模块导入
import pandas as pd
import numpy as np
#路径设置
source_data = r"E:/360MoveData/Users/B/Desktop/pandas_test.xlsx"
out_put = r"E:/360MoveData/Users/B/Desktop/output_data.xlsx"
#筛选条件设置
t1 = data1["门店属性"].str.contains("直营")
t2 = data1["订单状态"].str.contains("已完成")
#根据筛选条件返回成表
result = data1[t1&t2]
#输出成表
print(result)
#导出
result.to_excel(out_put)
输出结果,如下。

通过函数我们可以同时控制多个列的筛选条件,并输出成表。
2.3 文本筛选(同一列)
仍旧使用前文的数据源
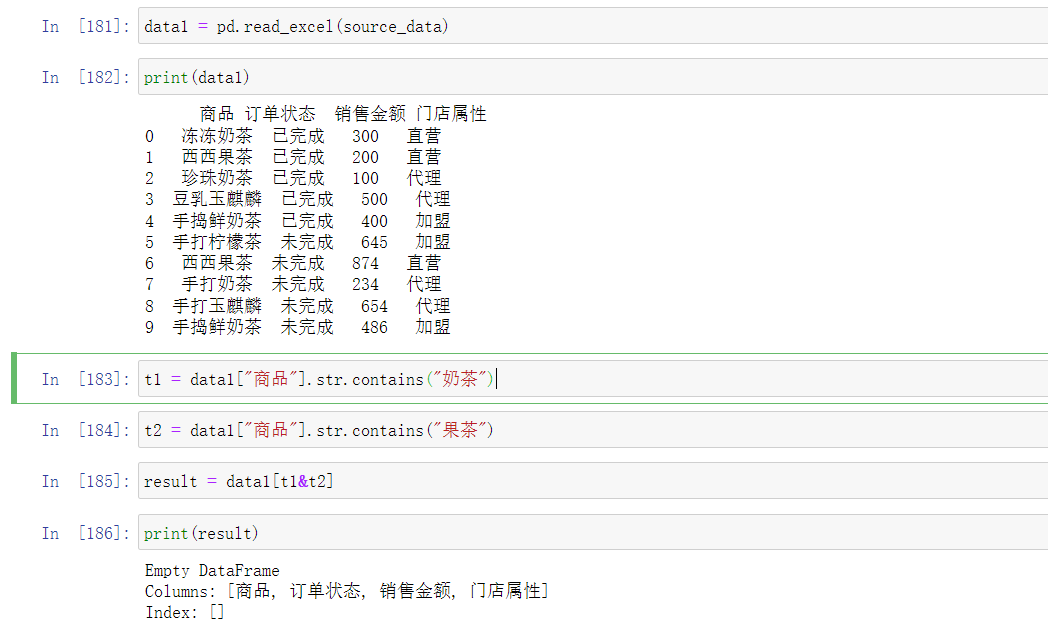
现在我们假设需求:商品品名中含有"奶茶",或者"果茶"的商品销售表
首先,我们来试试上一种方式,可以看到,这里的输出并不是我们想要的表
这里,我们换一个方式来实现。
data1.loc[data1["商品"].str.contains("奶茶|果茶",na = False),"订单判断"] = "目标订单"
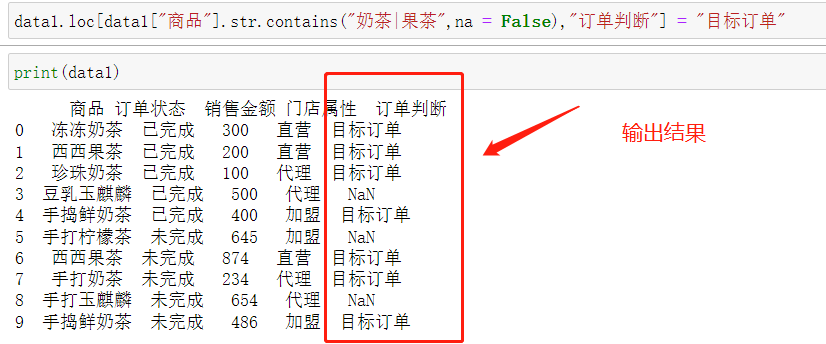
可以看到,商品这一列中含有奶茶、果茶的商品被标记了。
3:总结
利用str.contains,我们可以筛选同一列,不同列的数据,对于活动清洗、订单清洗等数据清洗环节,可以更快的标记对应的订单。
我是simone,期待下次的分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号