
#Python 利用pivot_table,数据透视表进行数据分析
前面我们分享了,利用python进行数据合并和连接,但是工作中,我们往往需要对数据进一步的聚合或者运算,以求最后的数据结果。
今天我们就来学习一下利用pandas模块,对数据集进行数据透视分析。
pivot_table释义
1.1 pivot_table参数列表:
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None, margins=False, dropna=True, margins_name=‘All’, observed=False, sort=True)
同样可以写成:
data.pivot_table(’ data列名’,index,columns,aggfunc…)
1.2 常用参数释义:
data:要进行数据透视的数据
values:要做计算的数据 ,对谁求和/求均值/计算个数等
index:确定行参数,可以是多个。单个’‘,多个[’‘,’‘]表示
columns:确定列参数,可以是多个。单个’‘,多个[’‘,’']
aggfunc:要计算的函数,mean求均值、sum求和、size计算个数
dropna:表示是否计算全为NaN的数据。bool类型,默认True 不计算
sort:对values结果进行排序。bool类型 默认False 升序
1.3 案例操作:
实际操作,首先导入pd 和 np 库
首先准备一个实验数据集,表头如下
import pandas as pd import numpy as np
设置文件路径和输出路径
path = r'E:/360MoveData/Users/B/Desktop/py案例excel.xlsx' path_out = r'E:/360MoveData/Users/B/Desktop/py案例数据输出11.xlsx'
1读取数据
data = pd.read_excel(path) print(data.shape) print(data.head())
2调用pivot_table模块,数据透视
'''
pd.pivot_table来调用数据透视,
index可以看做是pq中的分组依据字段
values可以看做是pq中的列字段
aggfunc分别是求和aggfunc=(np.sum),求平均aggfunc=(np.mean),计数aggfunc=(len),可以看做是excel透视表的值字段设置-计算类型
pivot_table模组的意义在于,大数据下的维度收缩,当数据源过于庞大时,通过py处理csv合集,解决处理过程的大数据问题,而pivot_table
可以在最后一步进行数据维度收缩,这有利于我们将大数据转为较小的数据集,最终配合excel去进行数据分析
'''
data1 = pd.pivot_table(data,
values =["入店数","下单数"],
index =["日期","门店所在城市"],
aggfunc=(np.sum)
)
输出结果如下:
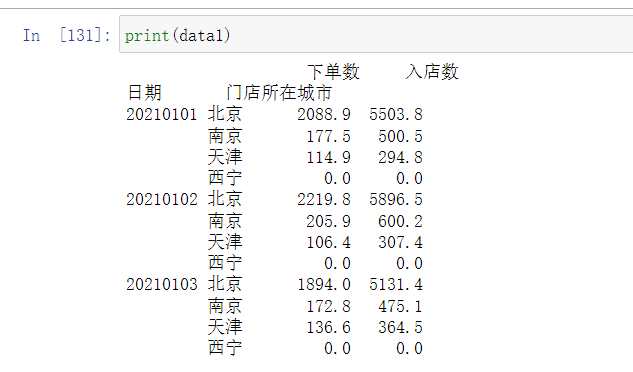
这个过程类似 分散-集中-压缩处理,在博主的工作中相当实用,希望有兴趣的大家也可以应用到实际工作中。
我是simone,期待下次的分享。(下次会分享powerbi相关的可视化对象内容)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号