
scrapy框架持久化存储
基于终端指令
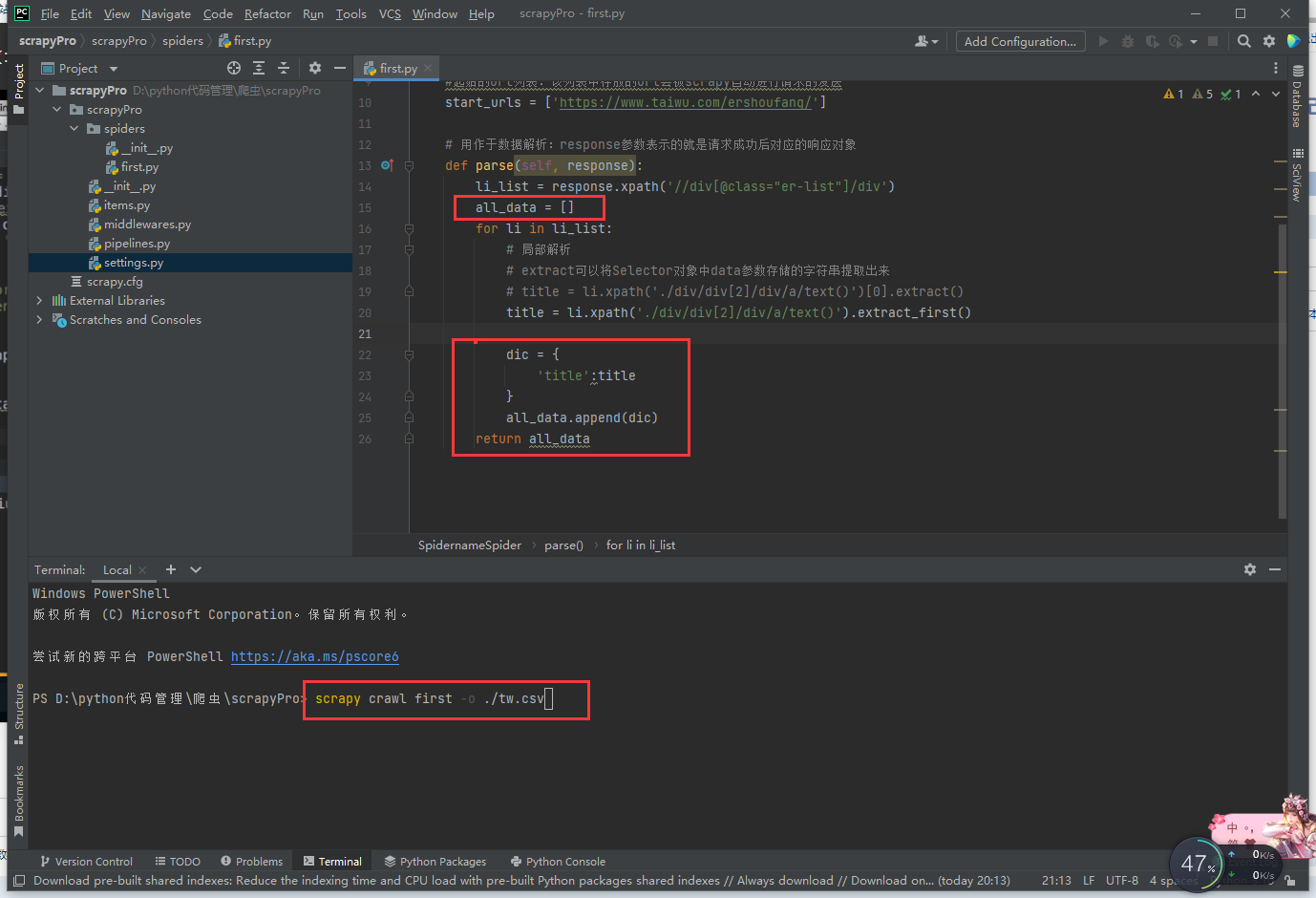
执行成功后数据存储在指定位置
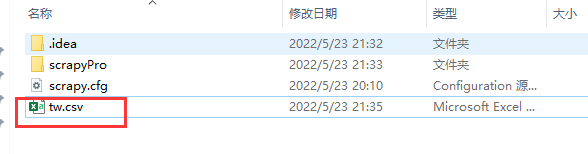
执行存储文件格式不正确时提示报错,提示指定的格式
总结
要求:只可以将parse方法的返回值存储到本地的文本文件中
注意:持久化存储对应的文本文件的类型只可以为:'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle
指令:scrapy crawl xxx -o filePath
好处:简介高效便捷
缺点:局限性比较强(数据只可以存储到指定后缀的文本文件中)
基于管道
在item类中定义相关的属性
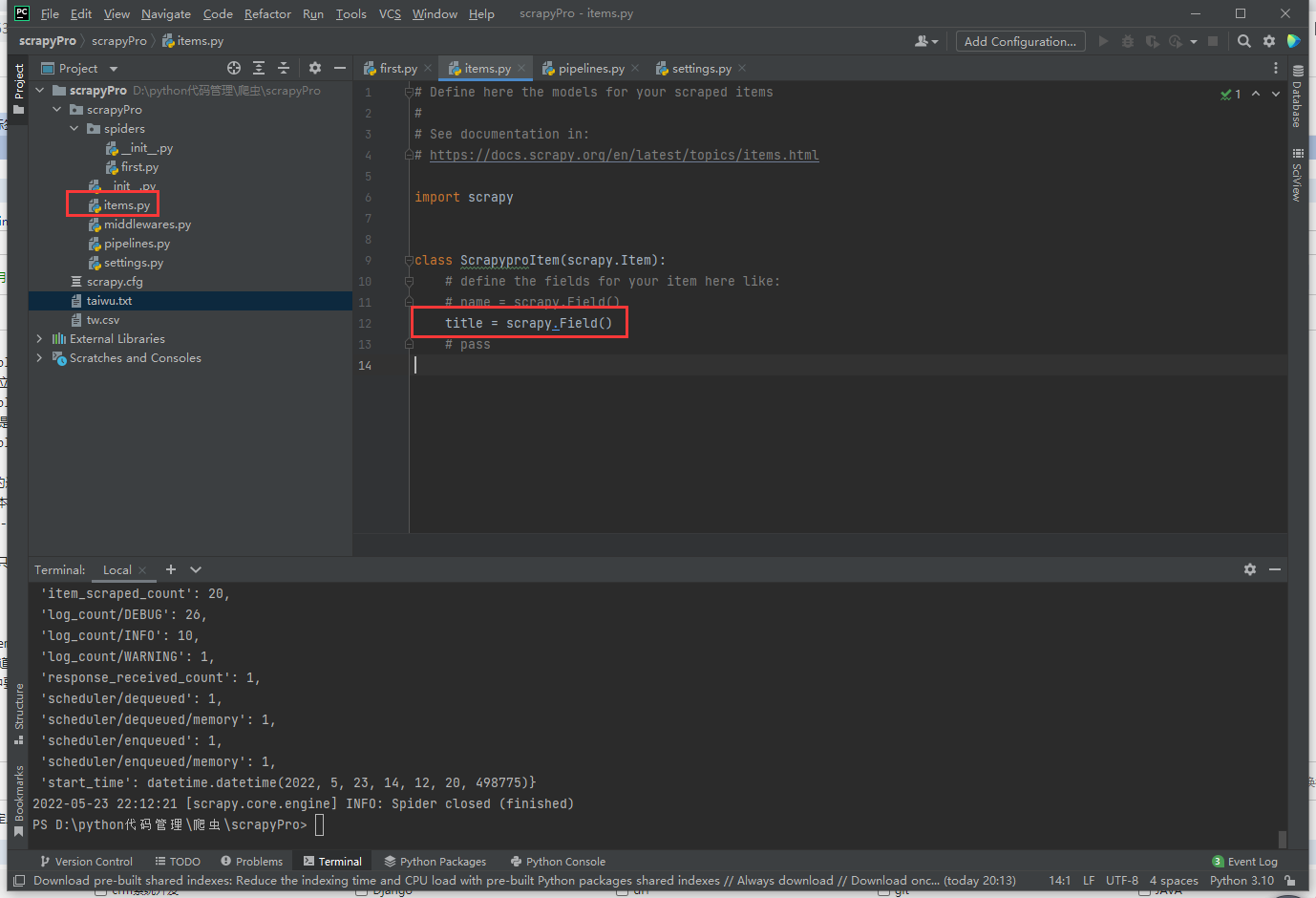
将解析的数据封装存储到item类型的对象
将item类型的对象提交给管道进行持久化存储的操作
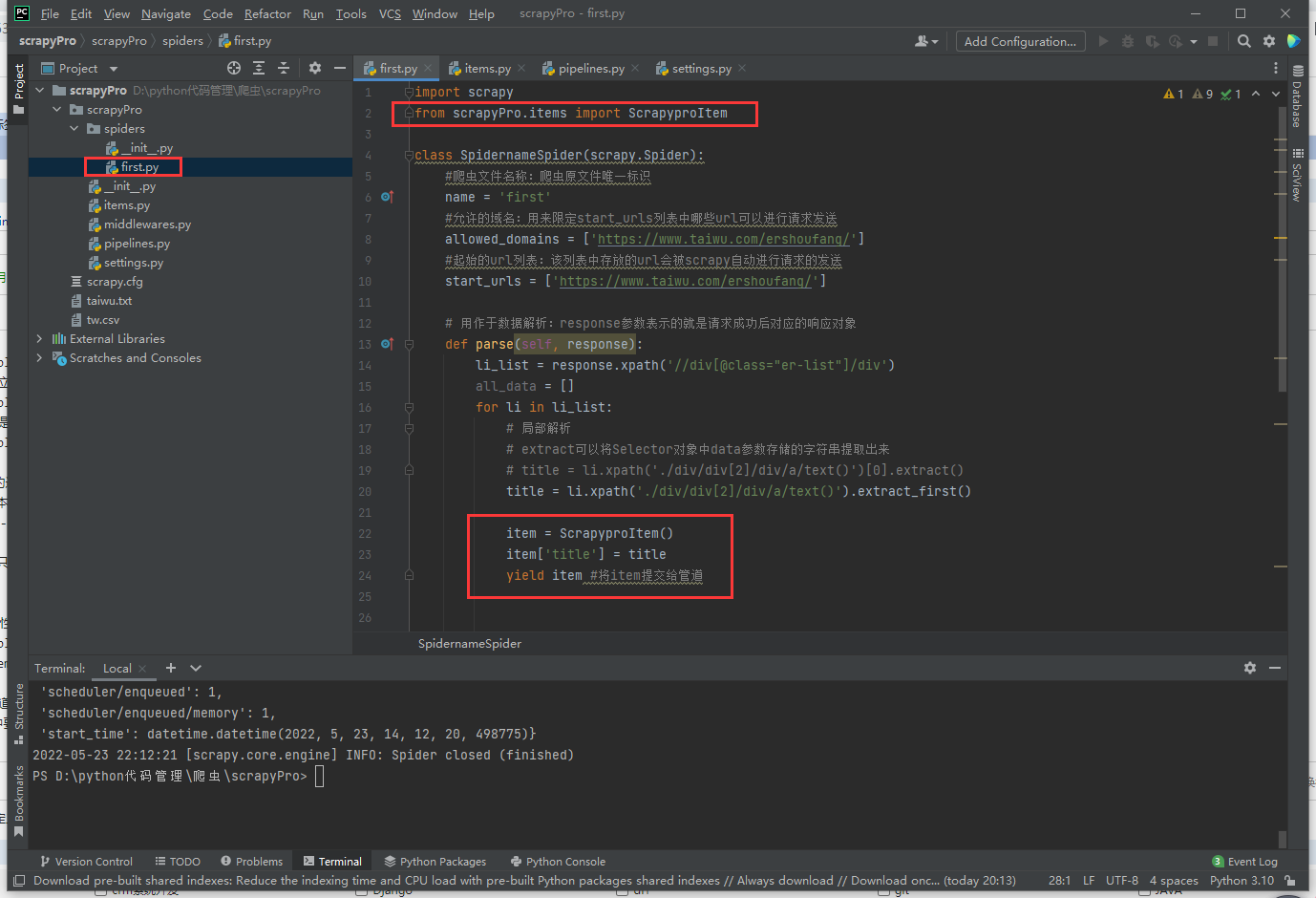
在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
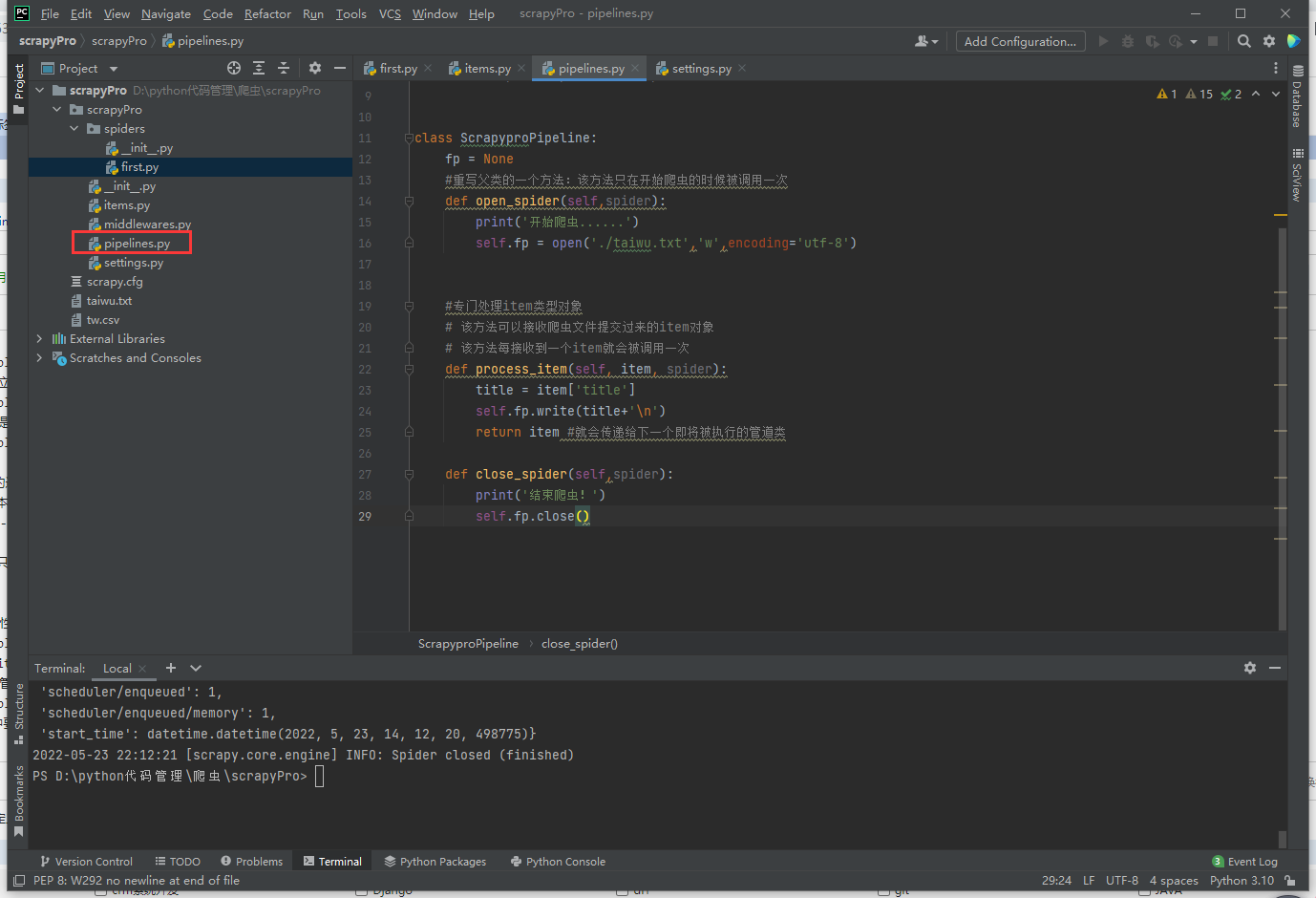
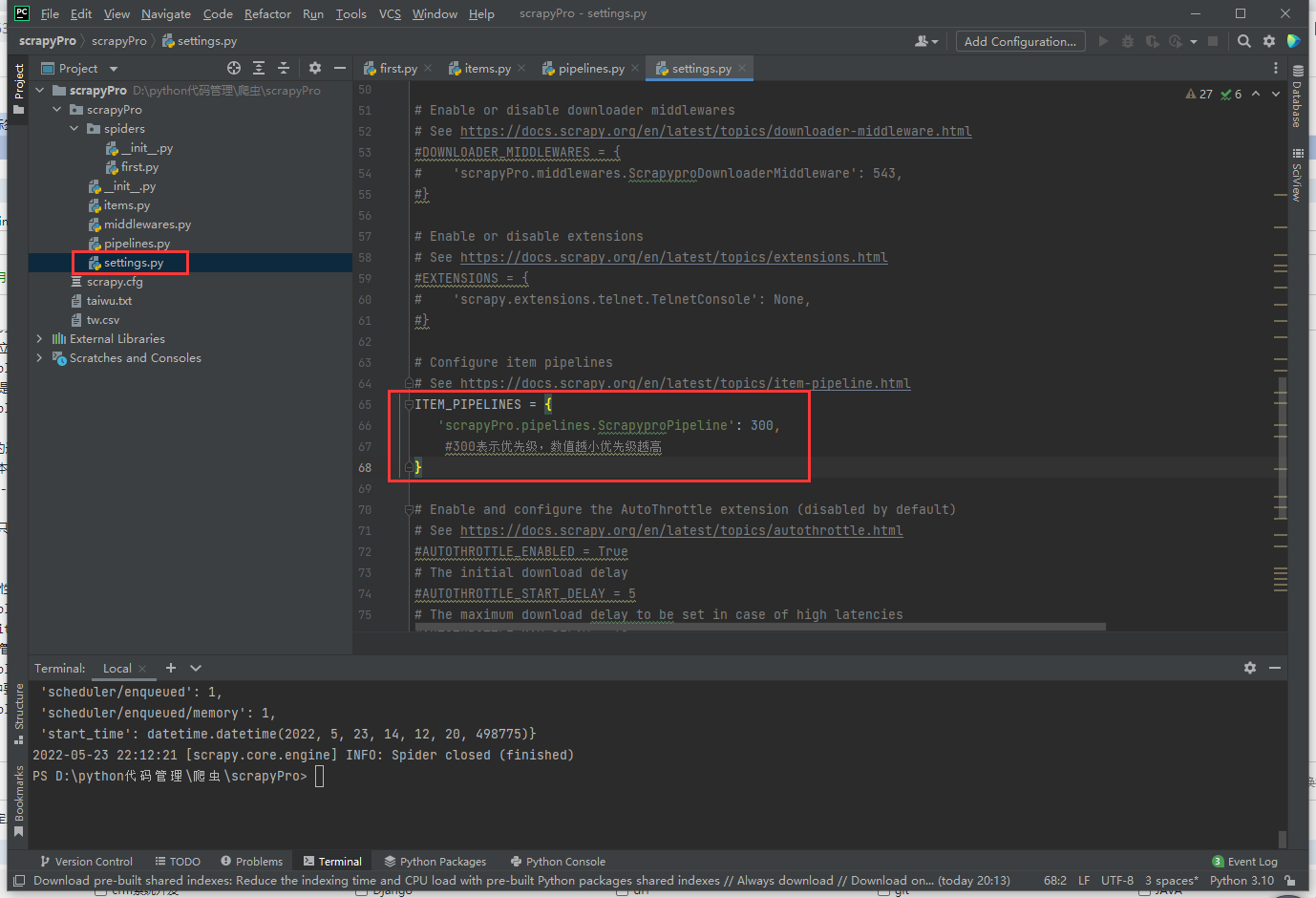
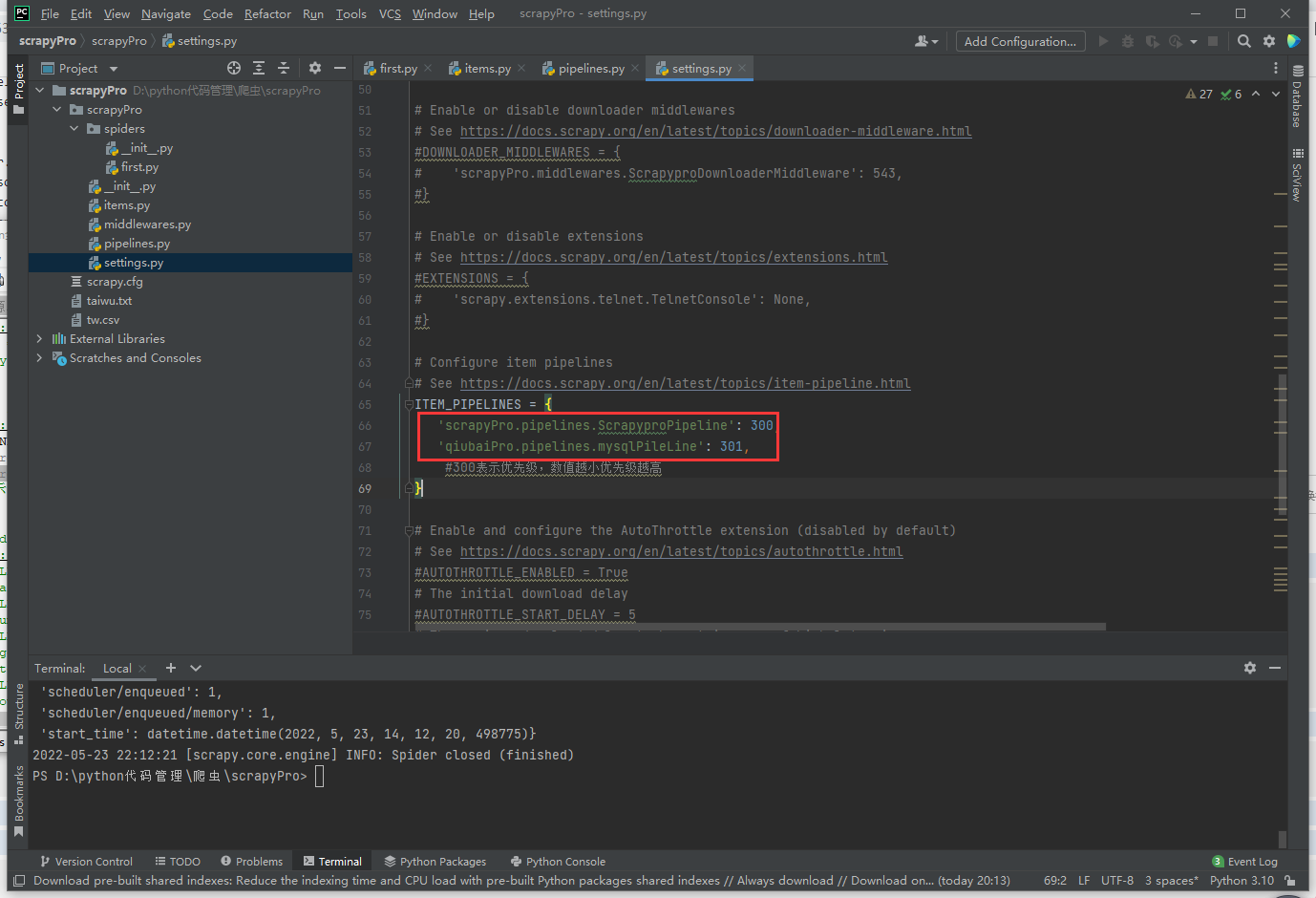
在配置文件中开启管道
将爬取到的数据一份存储到本地一份存储到数据库,如何实现?
管道文件再写一个类
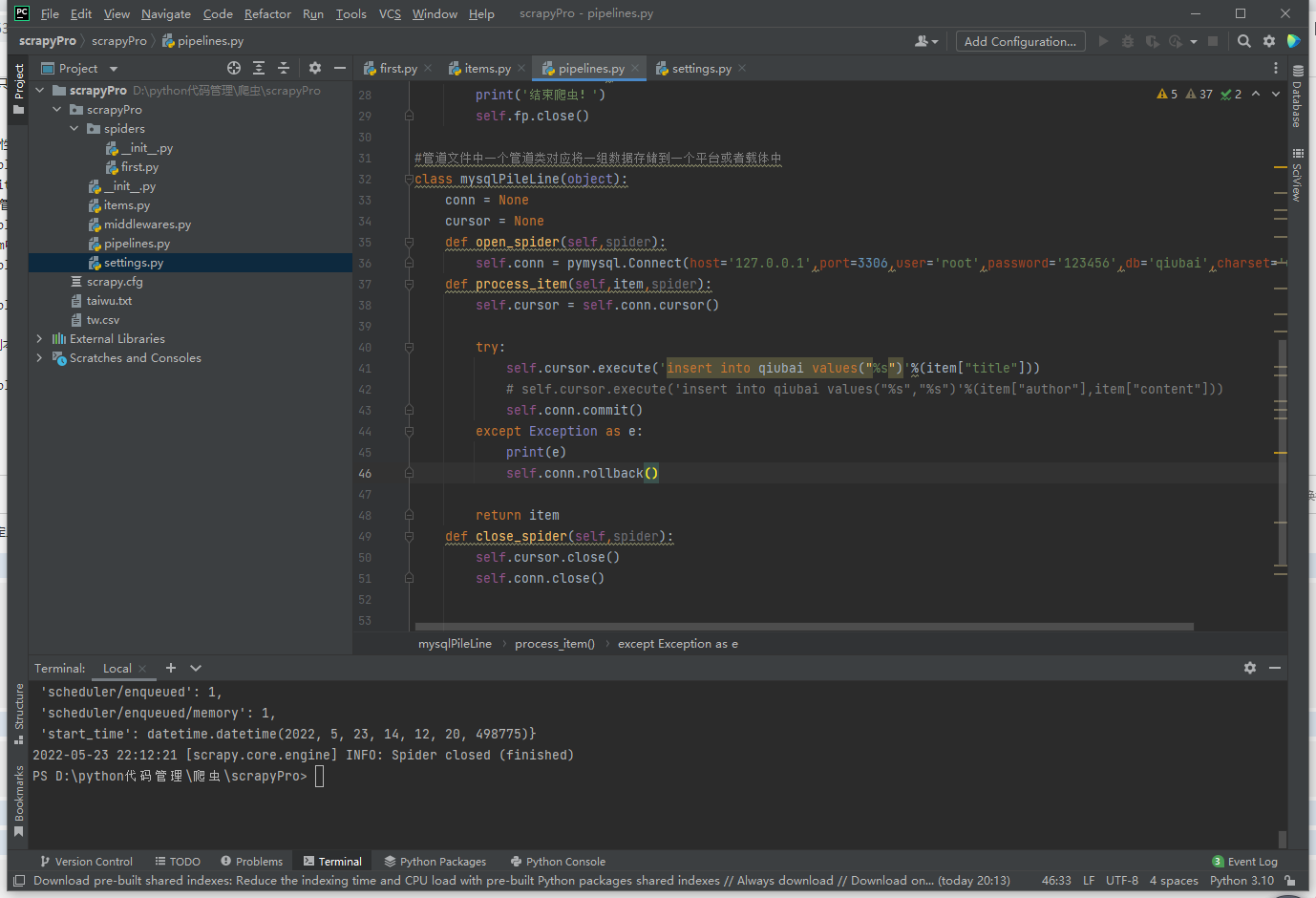
代码参考
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class ScrapyproPipeline:
fp = None
#重写父类的一个方法:该方法只在开始爬虫的时候被调用一次
def open_spider(self,spider):
print('开始爬虫......')
self.fp = open('./taiwu.txt','w',encoding='utf-8')
#专门处理item类型对象
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
title = item['title']
self.fp.write(title+'\n')
return item #就会传递给下一个即将被执行的管道类
def close_spider(self,spider):
print('结束爬虫!')
self.fp.close()
#管道文件中一个管道类对应将一组数据存储到一个平台或者载体中
class mysqlPileLine(object):
conn = None
cursor = None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='123456',db='qiubai',charset='utf8')
def process_item(self,item,spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into qiubai values("%s")'%(item["title"]))
# self.cursor.execute('insert into qiubai values("%s","%s")'%(item["author"],item["content"]))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
#爬虫文件提交的item类型的对象最终会提交给哪一个管道类?
#先执行的管道类
扩展
持久化存储一个详情一个文件示例
import os
class SunproPipeline:
if not os.path.exists('./news'):
os.mkdir('./news')
fp = None
def open_spider(self, spider):
print('开始爬虫......')
def process_item(self, item, spider):
title = item['title']
time = item['time']
number = item['number']
content = item['content']
file_name = './news/'+ title +'.txt'
self.fp = open(file_name,'w',encoding='utf-8')
self.fp.write(title+time+number+'\n'+content)
print(title)
def close_spider(self, spider):
print('结束爬虫.')
self.fp.close()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号