
python爬虫学习(六):xpath解析
- xpath解析原理:
- 1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
- 2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。
- 环境的安装:
- pip install lxml
- 如何实例化一个etree对象:from lxml import etree
- 1.将本地的html文档中的源码数据加载到etree对象中:
etree.parse(filePath)
- 2.可以将从互联网上获取的源码数据加载到该对象中
etree.HTML('page_text')
- xpath('xpath表达式')
- xpath表达式:
- /:表示的是从根节点开始定位。表示的是一个层级。
- //:表示的是多个层级。可以表示从任意位置开始定位。
- 属性定位://div[@class='song'] tag[@attrName="attrValue"]
- 索引定位://div[@class="song"]/p[3] 索引是从1开始的。
- 取文本:
- /text() 获取的是标签中直系的文本内容
- //text() 标签中非直系的文本内容(所有的文本内容)
- 取属性:
/@attrName ==>img/src
实战:抓取太屋网房源数据
https://www.taiwu.com/ershoufang/
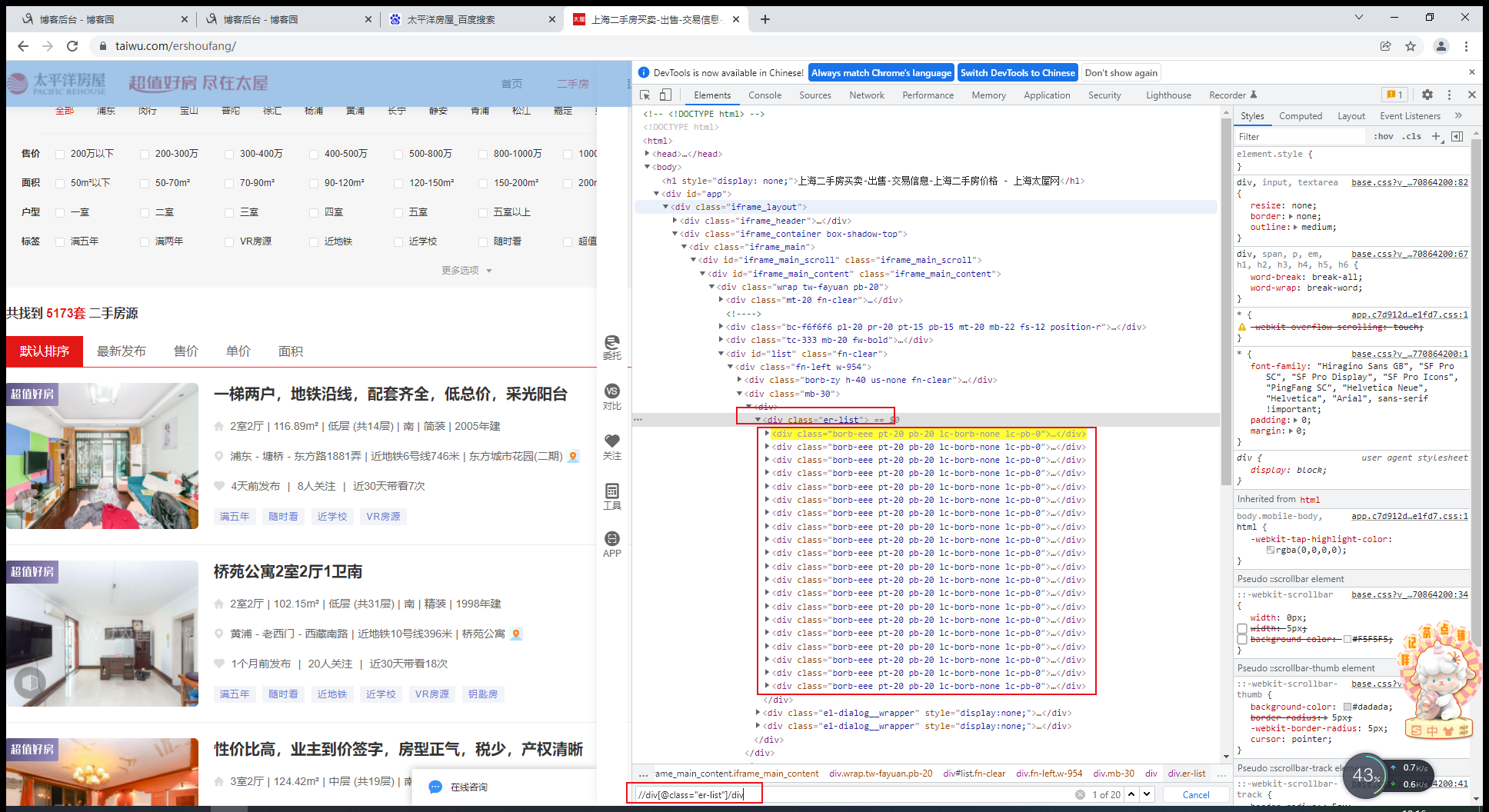
通过xpath定位可以看到房源数据都放在div标签中。路径为://div[@class="er-list"]/div
房源标题xpath路径为://div[@class="er-list"]/div/div/div[2]/div/a/text()
所以代码示例:
# -*- encoding: utf-8 -*-
"""
@File : 爬取58二手房.py
@Time : 2022/3/20 17:31
@Author : simon
@Email : 294168604@qq.com
@Software: PyCharm
"""
import requests
from lxml import etree
#需求:爬取58二手房中的房源信息
if __name__ == "__main__":
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
#爬取到页面源码数据
url = 'https://www.taiwu.com/ershoufang/'
page_text = requests.get(url=url,headers=headers).text
#数据解析
tree = etree.HTML(page_text)
#存储的就是li标签对象
li_list = tree.xpath('//div[@class="er-list"]/div')
fp = open('taiwu.txt','w',encoding='utf-8')
for li in li_list:
#局部解析
title = li.xpath('./div/div[2]/div/a/text()')[0]
print(title)
fp.write(title+'\n')
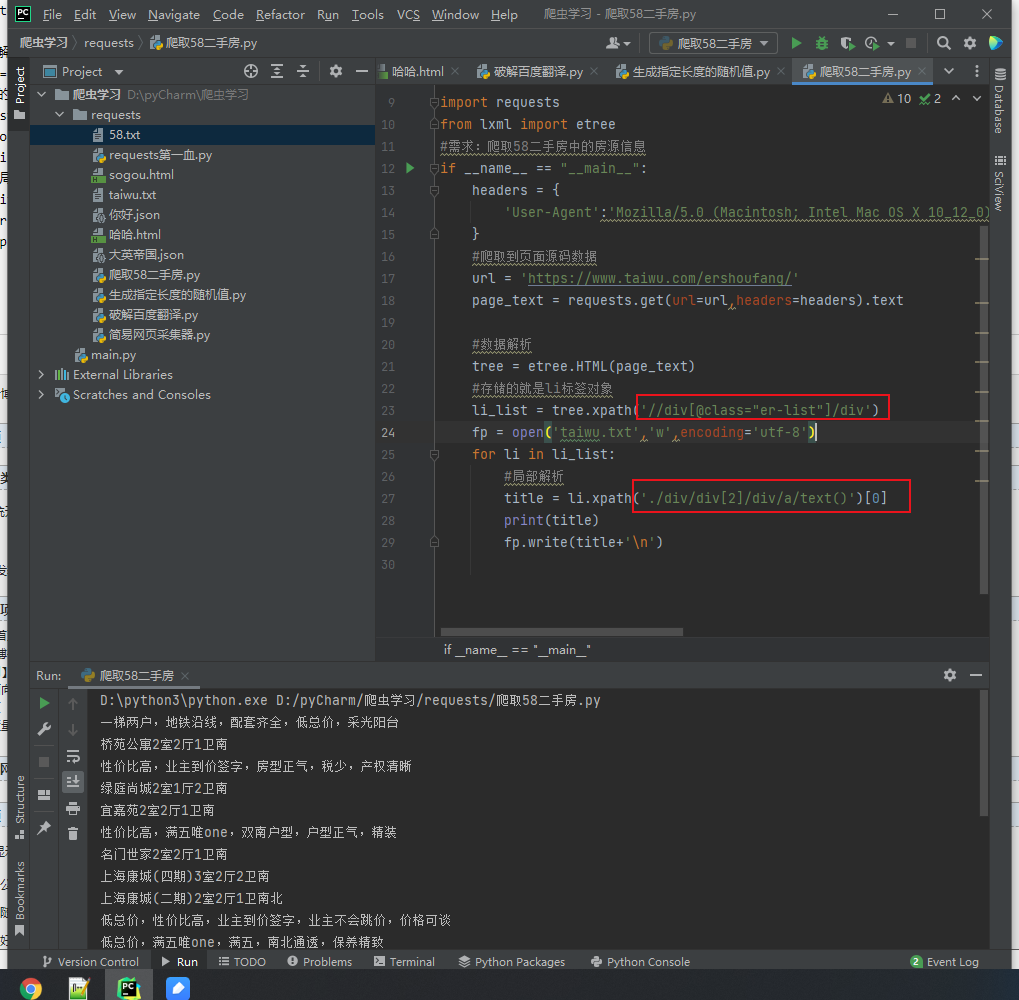
效果展示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号