
python爬虫学习(四):爬取网页图片-正则解析数据
有一个需求,爬取网页中的图片

思路:
1、先爬取整个网页
2、通过控制台找到图片地址的的规则,使用正则获取图片地址

由此看出地址的规则为
<p class="one-p"><img class="content-picture" src="//inews.gtimg.com/newsapp_bt/0/14610607424/1000">
</p>
正则表达式为:
ex = '<img class="content-picture" src="(.*?)"'
代码参考
# -*- encoding: utf-8 -*-
"""
@File : widgets.py
@Time : 2022/3/6 15:52
@Author : simon
@Email : 294168604@qq.com
@Software: PyCharm
"""
import requests
import re
import os
if __name__ == "__main__":
if not os.path.exists(''):
url = 'https://new.qq.com/omn/20220310/20220310A03I7300.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
#把整个网页进行爬取以文本方式提取
page_text = requests.get(url=url,headers=headers).text
#使用聚焦爬虫爬取所有图片网址进行解析/提取
ex = '<img class="content-picture" src="(.*?)"'
img_src_list = re.findall(ex,page_text,re.S)
for src in img_src_list:
#拼接 完整的url
src = 'https:' + src
#请求到图片的二进制数据
img_data = requests.get(url=src,headers=headers).content
#生成图片名称
img_name = src.split('/')[-2] + '.jpg'
#图片存储路径
img_path = './tupian/' + img_name
with open(img_path,'wb') as ap:
ap.write(img_data)
print('下载成功')
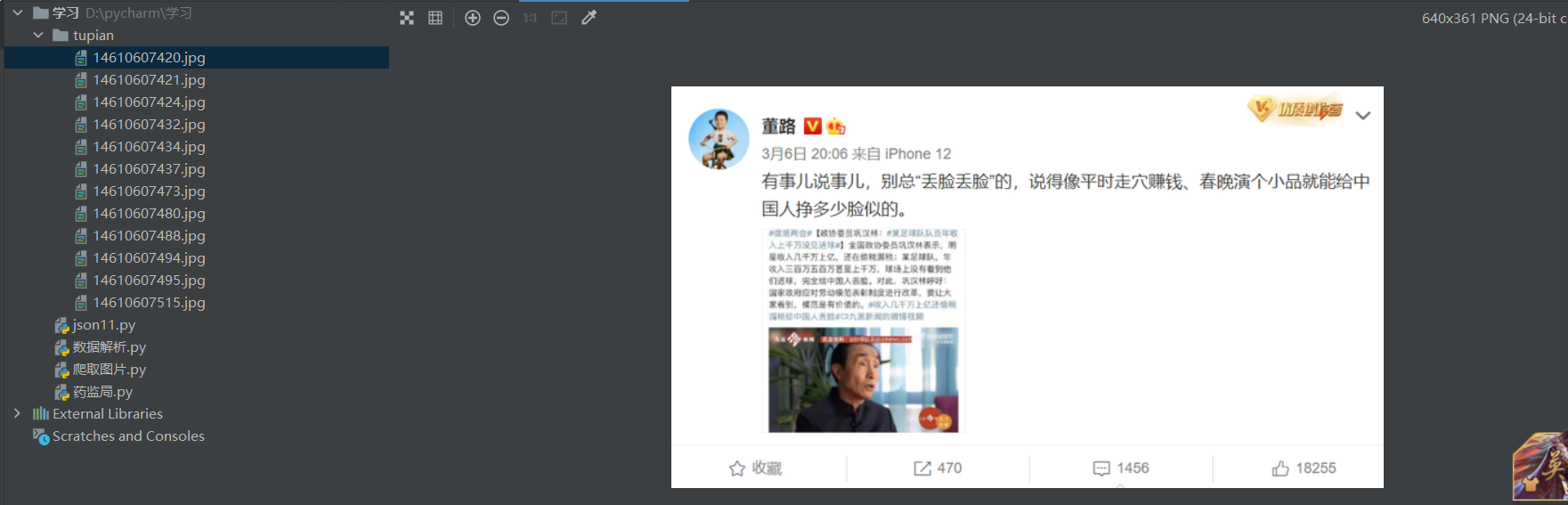
成果展示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号