Kafka学习笔记(四)—— API原理剖析
1、Producer API
1.1 消息发送流程
Kafka的Producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main线程和Sender线程,以及一个线程共享变量——RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker。
来一个动图品品:

注意图中的三个组件:
- interceptor:拦截器,后边写代码会自定义拦截器
- Serializer:序列化器
- Partitioner:分区器
关于这三个小组件到后边代码中,都会有所体现~
1.2 异步发送消息
中国有句古话:talk is cheap,show me the code ~
1.2.1 简单的代码示例:
1)导入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
2)Producer代码:
public class MyProducer {
public static void main(String[] args) {
//1.创建Kafka生产者的配置信息
Properties properties = new Properties();
//2.指定Kafka连接的集群
properties.put("bootstrap.servers", "hadoop102:9092");
//3.指定ACK应答级别
properties.put("acks", "all");
//4.批次大小,16KB
properties.put("batch.size", 16384);
//5.等待时间(即使数据量没有到达16KB,也会在这之后发送数据,防止等待时间过长)
properties.put("linger.ms", 1);
//6.重试次数
properties.put("retries", 3);
//7. RecordAccumulator 缓冲区大小 32MB
properties.put("buffer.memory", 33554432);
//8. key value序列化的类
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//9.创建生产者对象
KafkaProducer producer = new KafkaProducer<String, String>(properties);
//10.发送数据
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("first", "simon-1024"+Integer.toString(i)));
}
//11.注意要关闭资源,原因在于:整个程序运行下来不到1毫秒,数据不会被发送出去。
producer.close();
}
}
3)启动消费者开始消费 (事先创建了topic为first,有2个分区,2副本)
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
4)查看消费结果:
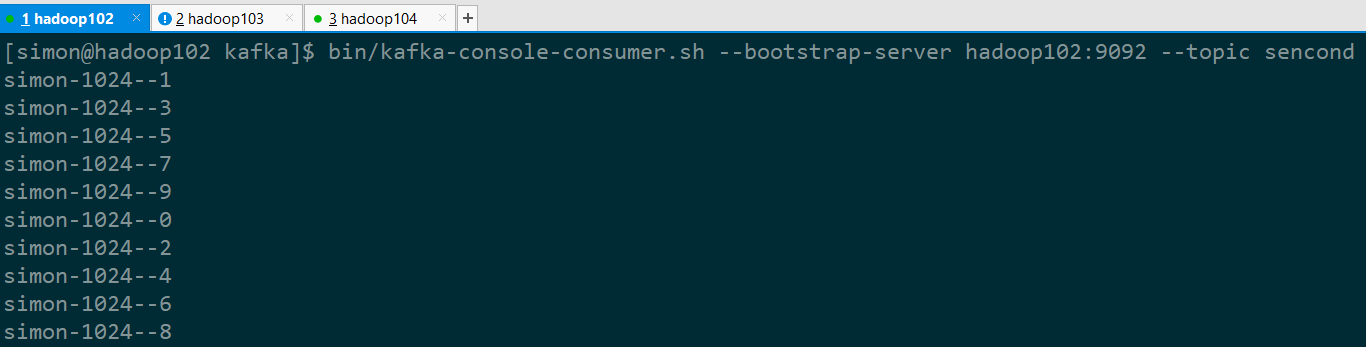
注意:消费者并不是按照 01234...这样的顺序消费消息的,这是为什么呢?体会分区的意义!!
1.2.2 带有回调函数的send方法
补充:其实send()方法是有重载的,注意看下面这种写法:
public class CallbackProducer {
public static void main(String[] args) {
//1.创建kafka生产者配置信息
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//2. 创建生产者对象
KafkaProducer kafkaProducer = new KafkaProducer<String,String>(properties);
//3. 发送数据
for (int i = 0; i <10 ; i++) {
kafkaProducer.send(new ProducerRecord("second", "simon-1024--" + i), new Callback() {// send的重载方法,可以有回调函数
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
//打印出本条数据发送到哪个分区了,偏移量是多少
System.out.println(recordMetadata.partition()+" "+recordMetadata.offset());
}
});
}
kafkaProducer.close();
}
}
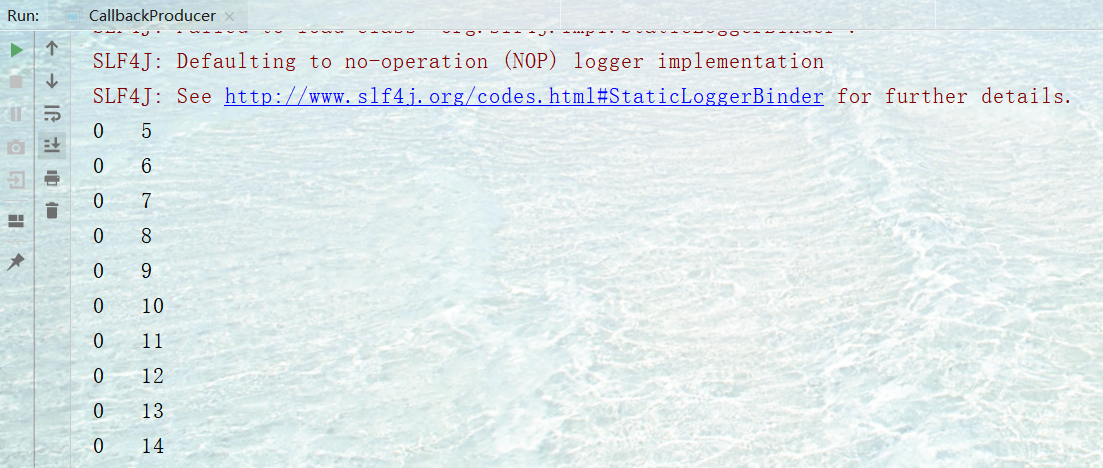
消费结果与上边一致,下图是我的执行结果:

直接证明了之前讲过的offset并不是全局唯一的,只保证区内有序。
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是RecordMetadata 和 Exception,如果 Exception 为 null,说明消息发送成功,如果Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
ProducerRecord的构造方法还有好多个重载,不再一一举例,如下:

1.2.3 自定义分区
如果我们在发送消息的时候没有指定分区,那么Kafka会使用默认的分区器,看一下源码,分区器都干了些什么(源码分析在注释中给出).
查阅了一下官方文档,默认的分区器为:org.apache.kafka.clients.producer.internals.DefaultPartitioner,直接查看它计算分区的方法:
/**
* Compute the partition for the given record.
* 给指定的消息计算分区
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//1. 获得集群中的该topic信息
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
//2. 共有几个分区
int numPartitions = partitions.size();
//3. 如果待发送的消息没有指定key
if (keyBytes == null) {
//3.1 做累加操作
//【为什么累加呢?比如第一次nextVlue = a,那么下一次为a+1,实现了轮询策略】
int nextValue = nextValue(topic);
//3.2 获取所有可用的分区(分区所在的机器没挂掉)
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
//3.2.1 如果有可用的分区
if (availablePartitions.size() > 0) {
// 负数转正后做摸运算
int part = Utils.toPositive(nextValue) % availablePartitions.size();
// 返回相应的分区数
return availablePartitions.get(part).partition();
}
//3.2.2 如果没有可用的分区
else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
}
//4. 如果待发送的消息指定了key
else {
// hash the keyBytes to choose a partition
//4.1 根据key的哈希值和分区数相与运算,得到分区号
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
ok,可以看到整个业务逻辑流程还是很清楚的。那么我们自己尝试写一个分区器:
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 使得所有的消息发往0号分区
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
运行程序,观察回调函数的执行效果:
1.3 同步发送消息
上面说到的都是消息都是通过异步的方式发送的,使用到了main线程和sender线程。但是如果sender线程在工作的时候,我们阻塞住main线程,那两个线程实现了串行工作的效果,也就相当于同步发送了。注意这里同步的意思是:一条消息发出去之后,会阻塞当前线程,直到返回ack。
由于 send 方法返回的是一个 Future 对象,根据 Futrue 对象的特点,我们也可以实现同步发送的效果,只需在调用 Future 对象的 get 方发即可。了解即可,不去深究。对上边的代码进行简单的改造:
//发送数据的代码片段
for (int i = 0; i < 10; i++) {
//send方法返回一个Future对象
Future future = producer.send(new ProducerRecord<String, String>("sencond", "simon-1024", "hello world " + Integer.toString(i)));
try {
//由future对象获得返回值,并且阻塞住线程
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
之前说过Kafka保证的是分区有序,而不是全局有序。如果要保证全局有序,那么最直接的方案就是只用一个分区,并且使用同步发送的方式,保证数据不丢失。
2、Consumer API
Consumer 消费数据时的可靠性是很容易保证的,因为数据在 Kafka 中是持久化的,故不用担心数据丢失问题。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。所以 offset 的维护是 Consumer 消费数据是必须考虑的问题。
下面是两个例子,分别是自动提交offset和手动提交offset
2.1 自动提交offset
1)导入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
2)代码示例
先解释一下用到的类:
KafkaConsumer:需要创建一个消费者对象,用来消费数据ConsumerConfig:获取所需的一系列配置参数
ConsuemrRecord:每条数据都要封装成一个 ConsumerRecord 对象
为了使我们能够专注于自己的业务逻辑,Kafka 提供了自动提交offset 的功能。自动提交 offset 的相关参数:
enable.auto.commit:是否开启自动提交 offset 功能
auto.commit.interval.ms:自动提交 offset 的时间间隔
public class MyConsumer {
public static void main(String[] args) {
//1. 创建消费者的配置对象
Properties properties = new Properties();
//2. 消费者连接的集群信息
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");
//3. 反序列化消息的key和value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//4. 允许自动提交:拉取到消息就自动提交offset下标,可能造成数据丢失
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
//5. 自动提交的间隔为1毫秒
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1");
//6. 设置消费者groupID
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"simon-0");
//7. 创建消费者对象
KafkaConsumer<String,String> kafkaConsumer = new KafkaConsumer(properties);
//8. 订阅的主题,参数是个集合,可以订阅多个主题
kafkaConsumer.subscribe(Arrays.asList("sencond"));
//Tip:循环拉取消息
while (true){
//9. 拉取消息,并且10毫秒拉取一次
ConsumerRecords<String,String> records = kafkaConsumer.poll(10);
//10. 解析消息
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
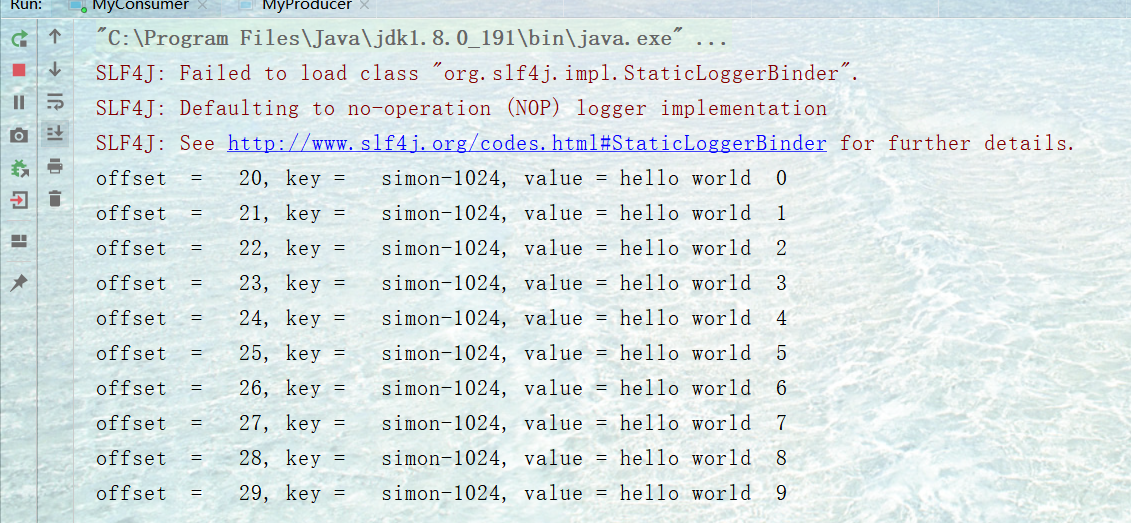
先启动消费者,然后随便起一个生产者,我就以我之前创建的生产者为例,消费结果如下:
关于ConsumerConfig的属性AUTO_OFFSET_RESET_CONFIG的补充:
假如有一个消费者,消费到offset = 10消息,然后关机了。7天之后机器重启,现在的消息的offset为1000。现在按道理来说应该从11开始消费,但是Kafka的消息默认保存消息7天,所以现在消费者持有的offset是无效的。
这时AUTO_OFFSET_RESET_CONFIG有两个值可以选择:earliest 和 latest,看一眼官方Doc:
What to do when there is no initial offset in Kafka or if the current offset does not exist any more on the server (e.g. because that data has been deleted):
- earliest: automatically reset the offset to the earliest offset
- latest: automatically reset the offset to the latest offset
- none: throw exception to the consumer if no previous offset is found for the consumer's group
- anything else: throw exception to the consumer.
Talk is cheap ,show me the code:
//1. 增加一条配置
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
//2. 修改消费者分组,手动使得offset失效
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"simon-1");
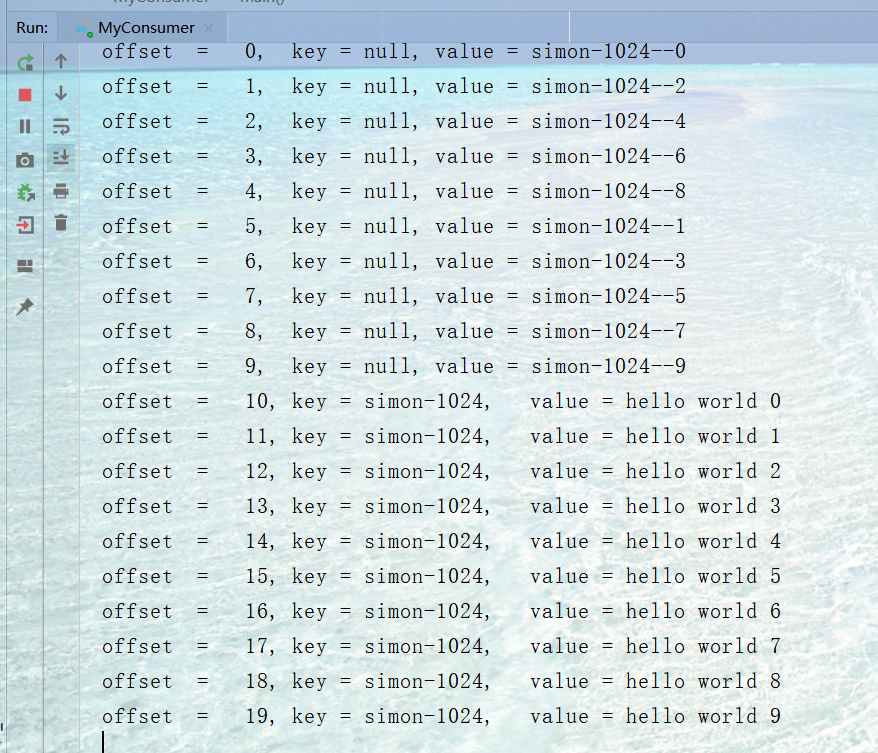
先执行一次producer生成一组数据,然后再启动consumer,可以消费到之前发送的所有数据!!
2.2 手动提交offset
前面的代码演示了自动提交offset,每次消费完成消费者都会提交offset,下次消费从offset+1开始。但是如果关闭自动提交,那么消费完成也不会提交offset,也就是说重新开启消费者还会从头开始消费。
如果消费者采用自动提交,拿到数据之后就提交offset。如果处理数据的时候出现了问题,那么这个数据就丢失了。
所以,Kafka提供了两种手动提交 offset 的方法: commitSync(同步提交)和 commitAsync(异步提交)。两者相同是,都会将本次 poll 的一批数据最高的偏移量提交;不同是:commitSync阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而 commitAsync 则没有失败重试机制,故有可能提交失败。
2.2.1 同步提交
同步提交的方法为:consumer.commitSync();
同步提交只要不发生不可恢复的错误,会一直尝试至提交成功,因此,会将降低程序的读取、处理速度。
//关闭自动提交 offset
properties.put("enable.auto.commit", "false");
//加在消费完成代码之后,消费者同步提交,当前线程会阻塞直到 offset 提交成功
consumer.commitSync();
2.2.2 异步提交offset
虽然同步提交offset更加安全可靠一点,但是它会造成线程的阻塞,直到提交成功。因此吞吐量会受到很大的影响。在更多的情况下,选用异步提交方式。
异步提交的方法为:consumer.commitAsync();
异步提交不会等待broker 的响应,而是只管发送,不管是否成功。提高了应用程序吞吐量,但下次读取消息的遗失或重复可能性大大提升。
//关闭自动提交 offset
properties.put("enable.auto.commit", "false");
//异步提交
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition,
OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.err.println("Commit failed for" +
offsets);
}
}
});
无论是同步提交还是异步提交 offset,都有可能会造成数据的漏消费或者重复消费。先提交 offset 后消费,有可能造成数据的漏消费;而先消费后提交 offset,有可能会造成数据的重复消费。
2.3自定义存储offset
Kafka 0.9 版本之前,offset 存储在 zookeeper,0.9 版本及之后,默认将 offset 存储在 Kafka
的一个内置的 topic 中。除此之外,Kafka 还可以选择自定义存储 offset。
offset 的维护非常繁琐,因为需要考虑到消费者的 Rebalance。
当有新的消费者加入消费者组、已有的消费者退出消费者组或者所订阅的主题的分区发生变化,就会触发到分区的重新分配,重新分配的过程叫做 Rebalance。
消费者发生 Rebalance 之后,每个消费者消费的分区就会发生变化。因此消费者要首先获取到自己被重新分配到的分区,并且定位到每个分区最近提交的 offset 位置继续消费。
要实现自定义存储 offset,需要借助 ConsumerRebalanceListener,以下为示例代码,其
中提交和获取 offset 的方法,需要根据所选的 offset 存储系统自行实现。
//消费者订阅主题
consumer.subscribe(Arrays.asList("first"), new ConsumerRebalanceListener() {
//该方法会在 Rebalance 之前调用
@Override
public void
onPartitionsRevoked(Collection<TopicPartition> partitions) {
commitOffset(currentOffset);
}
//该方法会在 Rebalance 之后调用
@Override
public void
onPartitionsAssigned(Collection<TopicPartition> partitions) {
currentOffset.clear();
for (TopicPartition partition : partitions) {
//定位到最近提交的 offset 位置继续消费
consumer.seek(partition, getOffset(partition));
}
}
});
while (true) {
//消费者拉取数据
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
currentOffset.put(new TopicPartition(record.topic(), record.partition()), record.offset());
}
//异步提交
commitOffset(currentOffset);
}
}
//获取某分区的最新 offset,比如可以mysql数据库中获取
private static long getOffset(TopicPartition partition) {
return 0;
}
//提交该消费者所有分区的 offset,可以将其存入到MySQL中一份
private static void commitOffset(Map<TopicPartition, Long> currentOffset) {
}
3、自定义拦截器
3.1 拦截器原理
Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。
对于producer而言,interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Intercetpor的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor
看一下结构,总共就三个方法,另外还有一个方法继承自父类
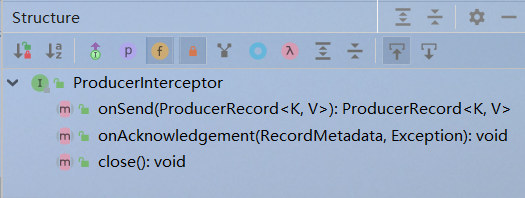
详细解读一下各个方法:
-
configure(Map<String, ?> configs) :
获取配置信息和初始化数据时调用。
-
onSend(ProducerRecord<K, V> record):
该方法封装进KafkaProducer.send方法中,即它运行在用户主线程中。Producer确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响目标分区的计算。
-
onAcknowledgement(RecordMetadata, Exception):
该方法会在消息从RecordAccumulator成功发送到Kafka Broker之后,或者在发送过程中失败时调用。并且通常都是在producer回调逻辑触发之前。onAcknowledgement运行在producer的IO线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢producer的消息发送效率。
-
close:
关闭interceptor,主要用于执行一些资源清理工作
3.2 拦截器案例
需求如下:实现一个简单的双interceptor组成的拦截链。第一个interceptor会在消息发送前将时间戳信息加到消息value的最前部;第二个interceptor会在消息发送后更新成功发送消息数或失败发送消息数。

代码如下~~:
TimeInterceptor.java
public class TimeInterceptor implements ProducerInterceptor<String,String> {
/**
* 在待发送的消息之前加入时间戳
* @param record
* @return
*/
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(record.topic(), record.partition(),
record.key(), System.currentTimeMillis() + record.value());
return producerRecord;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {}
}
CounterInterceptor.java
public class CounterInterceptor implements ProducerInterceptor<String,String> {
int success ;
int error ;
/**
* 不改变消息的内容,直接返回
* @param record
* @return
*/
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (metadata!=null){
success++;
}else {
error++;
}
}
/**
* 打印发送成功和失败的消息条数
*/
@Override
public void close() {
System.out.println("success :"+success);
System.out.println("error :"+error);
}
@Override
public void configure(Map<String, ?> configs) {}
}
开启消费者,消费数据:
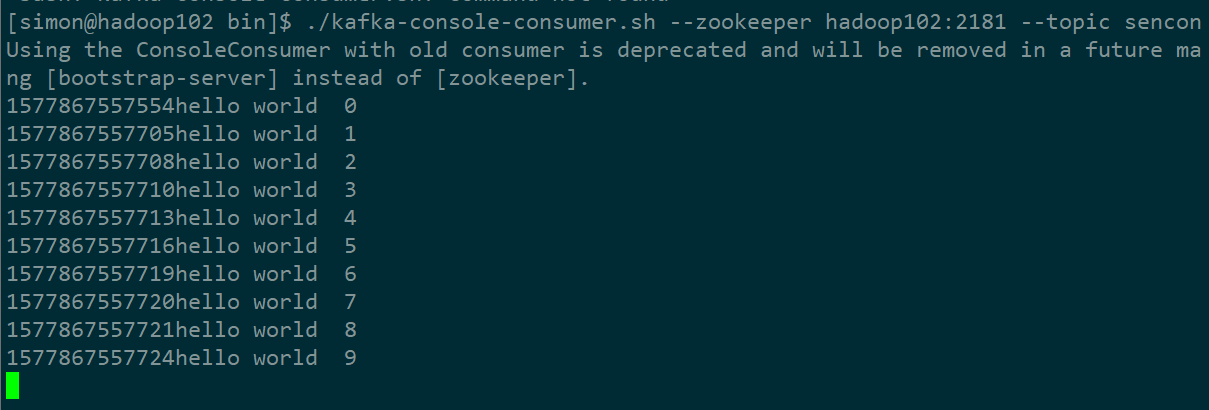
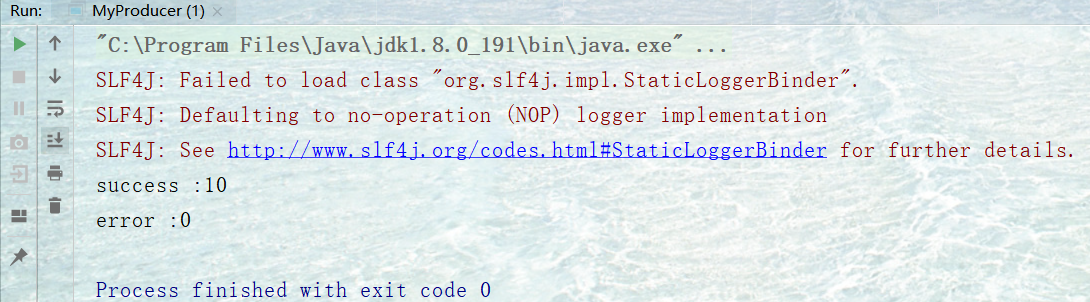
看控制台输出 ,打印了发送成功和失败消息的条数:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号