

windows 下搭建单hadoop
一,原料准备
1,下载hadoop 地址:hadoophttps://hadoop.apache.org/releases.html
2,下载JDK 地址:https://www.oracle.com/technetwork/java/javase/downloads/index.html
3, 下载window util for hadoop (https://codeload.github.com/gvreddy1210/bin/zip/master,请注意需要与window系统的32位或64位一致),解压后覆盖到hadoop\bin目录,(如果在测试中有问题,请将hadoop.dll拷贝到C:\\Window\system32目录,本人在测试中没有遇到问题,所以没有拷贝),另外,此util与具体的hadoop版本是有关的,如果选用不同的hadoop版本,需要找到正确的util,目前hadoop并没有提供window util,所以如果无法在网上找到合适的版本,那需要自己编译 (附:window util 编译的方法:Apache Hadoop 2.7.1 binary for Windows 64-bit platform)
4,配置jdk安装环境变量,配置hadoop安装环境变量
5,创建hadoop的namedate,datanode,temp,文件目录
二,开始配置hadoop的配置文件
hadoop 相关配置文件设置,涉及到4个主要的配置文件:core-site.xml, hdfs-site.xml, mapped-site.xml, yarn-site.xml
这些配置文件在hadoop安装目录的etc/hadoop下。
1,core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/D:/hadoop/temp</value> </property> </configuration>
2,hdfs-site.xml
在 hdfs-site.xml 中配置 nameNode,dataNode 的本地目录信息,以及分片备份详细如下
<configuration> <property> <name>dfs.data.dir</name> <value>/D:/hadoop/datanode</value> </property> <property> <name>dfs.name.dir</name> <value>/D:/hadoop/namenode</value> </property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3,mapped-site.xml
在 mapred-site.xml 中配置其使用 Yarn 框架执行 map-reduce 处理程序,详细如下
这个文件可能没有,在这个目录下有个mapred-site.xml.template,重命名为mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
4,yarn-site.xml
最后在 Yarn-site.xml 中配置 ResourceManager,NodeManager 的通信端口,web 监控端口等,详细如下
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>1</value> </property>
5,安装ssh在我的上篇博客https://www.cnblogs.com/simith/p/10027841.html
6,在hadoop 配置jdk,找到 hadoop-evn.cmd,这个文件在hadoop的安装目录 的etc/hadoop下
找到JAVA_HOME=[JDK的安装目录]
比如:set JAVA_HOME=D:\Java\jdk1.8.0_131
7,上面步骤完成设置后,就可以试着运行hadoop了
首先:格式化namenode:进入到hadoop\bin目录,执行命令:hadoop namenode -format
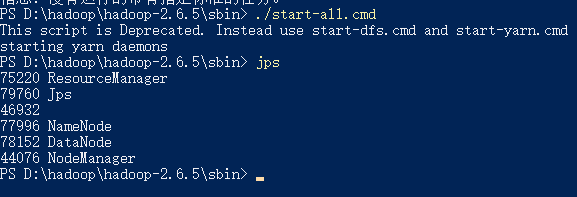
启动或停止hadoop:进入到sbin目录,执行命令:start-all.cmd
运行在cmd中输入 jps查看运行进程
停止: stop-all.cmd

 浙公网安备 33010602011771号
浙公网安备 33010602011771号