

spark数据分区数量的原理
原始RDD或数据集中的每一个分区都映射一个或多个数据文件, 该映射是在文件的一部分或者整个文件上完成的。
Spark Job RDD/datasets在执行管道中,通过根据分区到数据文件的映射读取数据输入到RDD/dataset。
如何根据某些参数确定spark的分区数?
使用Dataset APIs读取数据的分区数:
functions:
https://spark.apache.org/docs/2.3.0/api/java/org/apache/spark/sql/DataFrameReader.html
*文件格式 APIs* Dataset<Row> = SparkSession.read.csv(...) Dataset<Row> = SparkSession.read.json(...) Dataset<Row> = SparkSession.read.text(...) Dataset<Row> = SparkSession.read.parquet(...) Dataset<Row> = SparkSession.read.orc(...) *通用格式 API* Dataset<Row> = SparkSession.read.format(String fileformat).load(...)
影响数据分区数的参数:
(a)spark.default.parallelism (default: Total No. of CPU cores)
(b)spark.sql.files.maxPartitionBytes (default: 128 MB) 【读取文件时打包到单个分区中的最大字节数。】
(c)spark.sql.files.openCostInBytes (default: 4 MB) 【 该参数默认4M,表示小于4M的小文件会合并到一个分区中,用于减小小文件,防止太多单个小文件占一个分区情况。这个参数就是合并小文件的阈值,小于这个阈值的文件将会合并。】
使用这些配置参数值,一个名为maxSplitBytes的最大分割准则被计算如下:
maxSplitBytes = Minimum(maxPartitionBytes, bytesPerCore)
bytesPerCore = (文件总大小 + 文件个数 * openCostInBytes)/ default.parallelism
maxSplitBytes:
for each_file in files: if each_file is can split: if each_file.size() > maxSplitBytes: # file 被切分为 block_number 块其中block_number-1大小为 maxSplitBytes,1块<=maxSplitBytes block_number = ceil(each_file.size() / maxSplitBytes) else: block_number = 1 else: #文件不可分 block_number = 1
数据文件计算文件块之后,将一个或多个文件块打包到一个分区中。
打包过程从初始化一个空分区开始,然后对每个文件块进行迭代:
1. 如果没有当前分区要打包,请初始化要打包的新分区,然后将迭代的文件块分配给该分区。 分区大小成为块大小与“ openCostInBytes”的额外开销的总和。
2.如果块大小的增加不超过当前分区(正在打包)的大小超过' maxSplitBytes ',那么文件块将成为当前分区的一部分。分区大小是由块大小和“openCostInBytes”额外开销的总和增加的。
3.如果块大小的增加超过了当前分区被打包的大小超过了' maxSplitBytes ',那么当前分区被声明为完整并启动一个新分区。迭代的文件块成为正在初始化的新分区的一部分,而新分区大小成为块大小和‘openCostInBytes’额外开销的总和。
打包过程结束后,将获得用于读取相应数据文件的数据集的分区数。

尽管获得分区数量的过程似乎有点复杂,但基本的思想是,如果文件是可分拆的,那么首先在maxSplitBytes边界处拆分单个文件。
在此之后,将文件的分割块或不可分割的文件打包到一个分区中,这样,在将块打包到一个分区中期间,
如果分区大小超过maxSplitBytes,则认为该分区已经打包完成,然后采用一个新分区进行打包。因此,最终从包装过程中得到一定数量的分区。
e.g:
core设置为10
(a) 54 parquet files, 65 MB each, 默认参数 。
bytesPerCore = (54*65 + 54 * 4)/ 10 = 372M
maxSplitBytes = Minimum(maxPartitionBytes, bytesPerCore) = min(128M,372M)=128
65 < 128 && 2*65 > 128 ==> 54分区
(b)54 parquet files, 63 MB each, 默认参数。
bytesPerCore = (54*63 + 54 * 4)/ 10 = 361M
maxSplitBytes = Minimum(maxPartitionBytes, bytesPerCore) = min(128M,361M)=128
63 < 128 && 4 + 2*63=126+4=130 > 128=maxPartitionBytes ==> 54 (看起来 1分区可以容纳2个块,但是存在一个openCostInBytes开销4M,2个63+4大于了 128M,故一个分区只能一个块)
(c)54 parquet files, 40 MB each, 默认参数。
bytesPerCore = (54*40 + 54 * 4)/ 10 = 237M
maxSplitBytes = Minimum(maxPartitionBytes, bytesPerCore) = min(128M,237M)=128
40 < 128 && (4+3* 40) = 124 < 128 (故一个分区可以装3个块) = 54/3 = 18分区
(d)54 parquet files, 40 MB each, maxPartitionBytes=88M 其余默认
bytesPerCore = (54*40 + 54 * 4)/ 10 = 237M
maxSplitBytes = Minimum(maxPartitionBytes, bytesPerCore) = min(88M,237M)=88
40 < 88 && (4+2*40) = 84 < 88 (一个分区2个) = 27个分区
(e) 54 parquet files, 40 MB each ; spark.default.parallelism set to 400
bytesPerCore = (54*40 + 54 * 4)/ 400 = 5.94M maxSplitBytes = Minimum(maxPartitionBytes, bytesPerCore) = min(128M,5.94M)=5.94 每个文件块数:ceil(40 / 5.94) = 7个 5.94 + 4M > 5.94 一个分区一个块 所以总分区数为: 54 * 7 = 378 个分区
使用RDD APIs读取数据文件的分区数
RDD APIs类似下面的API
*SparkContext.newAPIHadoopFile(String path, Class<F> fClass, Class<K> kClass, Class<V> vClass, org.apache.hadoop.conf.Configuration conf) *SparkContext.textFile(String path, int minPartitions) *SparkContext.sequenceFile(String path, Class<K> keyClass, Class<V> valueClass) *SparkContext.sequenceFile(String path, Class<K> keyClass, Class<V> valueClass, int minPartitions) *SparkContext.objectFile(String path, int minPartitions, scala.reflect.ClassTag<T> evidence$4)
在这些API中,会询问参数' minPartitions ',而在另一些API中则没有。如果没有查询,则默认值为2或1,1(默认情况下为1)。并行性是1。这个“minPartitions”是决定这些api返回的RDD中分区数量的因素之一。其他因素为Hadoop配置参数的值:
# 关于 mapred.min.split.size see https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/DeprecatedProperties.html
# 关于 dfs.blocksize see https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml 默认: 128M
minSize (mapred.min.split.size - default value 1 MB) or minSize (mapreduce.input.fileinputformat.split.minsize - default value 1 MB)
blockSize (dfs.blocksize - default 128 MB)
goalSize = Sum of all files lengths to be read / minPartitions
splitSize = Math.max(minSize, Math.min(goalSize, blockSize));
现在使用“splitSize”,
for each_file in files: if each_file: if each_file.size() > splitSize: # file 被切分为 block_number 块其中block_number-1大小为 splitSize,最后一个块<=splitSize block_number = ceil(each_file.size() / maxSplitBytes) else: # 大小等于文件长度的文件块 block_number = 1 block_size = 文件长度的文件块 else: #文件不可分 block_number = 1 block_size = 文件长度的文件块
每个文件块(大小大于0)都映射到单个分区。因此,由数据文件上的RDD api返回的RDD中的分区数,等于使用“splitSize”对数据文件进行切片而得到的非零文件块的数
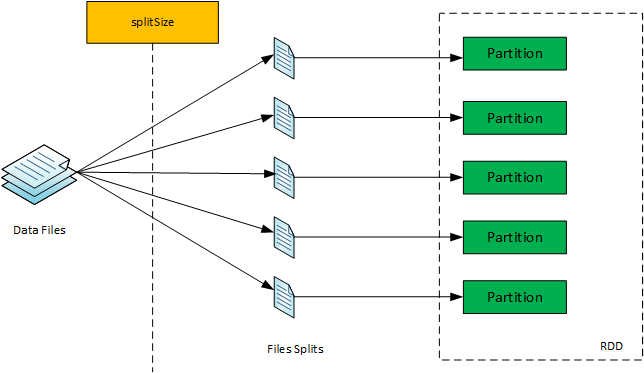
e.g:
(a). 31 parquet files, 330 MB each, blocksize at default 128 MB, minPartitions not specified, core is 10
splitSize = Math.max(minSize, Math.min(Sum of all files lengths to be read / minPartitions, blockSize)) = max( 0 , 128M) = 128M
一个文件按照splitSize=128M可以分3个,故一共分区数 31*3=93
(b). 54 parquet files, 40 MB each, blocksize at default 128 MB, core is 10
splitSize = Math.max(minSize, Math.min(Sum of all files lengths to be read / minPartitions, blockSize)) = max( 0 , min(2264924160/1,128M)) = 128M
splitSize=128M ,40 <128 1个文件长度的文件块 故为54个分区
(c) 31 parquet files, 330 MB each, blocksize at default 128 MB, minPartitions specified as 1000
splitSize = Math.max(minSize, Math.min(Sum of all files lengths to be read / minPartitions, blockSize)) = max( 0 , min(31 * 330 * 1024 * 1024/1000 ,128 * 1024 * 1024)) = 10726932 = 10.23M
一个文件分为 ceil(330/10.23) = 33块 共计:31 * 33 = 1023 共计分区: 1023个
(d) 31 parquet files, 330 MB each, blocksize at default 128 MB, minPartitions not specified, ‘mapred.min.split.size’ set at 256 MB, No. of core equal to 10
splitSize = Math.max(minSize, Math.min(Sum of all files lengths to be read / minPartitions, blockSize)) = max( 256 , min(31 * 330 * 1024 * 1024/1 ,128 * 1024 * 1024)) =256M 330/256.0 = 2 , 31 * 2 = 62个分区
总结:
分区的最佳数量是高效可靠的Spark应用程序的关键。

