
模式识别课堂笔记之聚类(1)
1.定义 :将数据分成多个类别,在同一个类内,对象(实体)之间具有较高的相似性,不同类对象之间的差异性较大。
对一批没有类别标签的样本集,按照样本之间的相似程度分类,相似的归为一类,不相似的归为其它类。这种分类称为聚类分析,也称为无监督分类。
2.结果取决于两个因素:第一个是任务的选择,同样的样本不同的任务会得到不同的聚类效果;第二个是相似度度量标准的选择,选择不同的相似度度量直接影响聚类效果的好坏。
3.分类:
按聚类标准分:统计聚类方法 ,概念聚类方法;
按数据类型分:数值型数据聚类、离散型数据聚类、混合型数据聚类;
按照度量准则:
基于距离的聚类方法:基于各种不同的距离或者相似性来度量点对之间的关系,如K-means等。
基于密度的聚类方法:基于合适的密度函数来对样本进行聚类。
基于连通性的聚类方法:主要包含基于图的方法。高度连通的数据通常被聚为一簇,如谱聚类。
按照不同的技术路线:
划分法:采用一定的规则对数据进行划分,如K-means等。
层次法:对给定样本进行层次划分,如层级聚类。
密度法:对数据的密度进行评价,如高斯混合模型。
网格法:将数据空间划分为有限个单元网络结构,然后基于网络结构进行聚类
模型法:为每一个簇引入一个模型,然后对数据进行划分,使其满足各自分派的模型。
4.距离与相似性度量
参见:http://www.cnblogs.com/simayuhe/p/5297560.html
注意:所谓距离要满足一下四个条件,我们才能称之为距离:

5.混合密度函数
***混合密度估计可为数据聚类提供方法论上的指导***
注意:这里讨论的是一种可推广的聚类形式,高斯混合只是一个较为常见的例子而已,并不是唯一的。
假设:
–样本来自于 c 个不同类别, c 是已知的。
–每一个类出现的先验概率  是已知的, j = 1, 2, …, c。
是已知的, j = 1, 2, …, c。
–类条件概率密度函数  的形式是已知的。
的形式是已知的。
–c 个参数向量 , j = 1, 2, …, c, 是未知的。
, j = 1, 2, …, c, 是未知的。
–样本的类别标签也是未知的。
先讨论数据的生成过程:先从c个类别中选择一个类,然后从这个类中按条件概率密度抽样一个样本。
然后我们要做的任务是与生成过程相反的,也就是说,我们得到了一堆没有标签的样本,虽然我们也假设样本服从混合密度分布,即

但是,我们并不知道每一个类别所占的比例 ,和每一个类别的条件概率密度
,和每一个类别的条件概率密度 中的参数
中的参数 ,要通过最大似然估计的方法把它们估计出来。(c还是已知的)
,要通过最大似然估计的方法把它们估计出来。(c还是已知的)
具体过程参见 《模式识别》张学工 第三版 p187
对数似然:

对 :
:


对 ,由于有约束条件:
,由于有约束条件: ,解决等式约束的优化问题通常使用拉格朗日乘子法:
,解决等式约束的优化问题通常使用拉格朗日乘子法:
最后得到:
综上:两个条件为:

以上是普遍意义上的推导,接下来把推导的结果应用在高斯混合上:
高斯混合中的每一个成分都符合多维正态分布形式如下
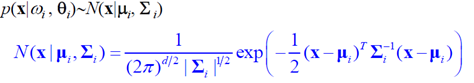
当方差已知均值未知的时候
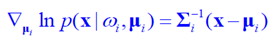
带到条件2当中得到
 注x应该有角标k的;
注x应该有角标k的;
把均值从这个式子中解出来:

打开,写成权重的形式:

上式表明,类均值的最大似然估计为样本的加权平均。权值表明样本 xk 属于第 i 类的可能性。
注意到权重只与i类样本有关,对以上式子进行简化



由上式引进一个更加具体的桔类方法——K-means聚类,这里的K 指的是上面提到的给定类别个数C,对上面的简化做一个转述

这里所谓的nearest是需要给定一种距离度量方法的,比如 欧式距离
算法描述:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号