docker的基本使用
一、docker容器与传统虚拟机的区别
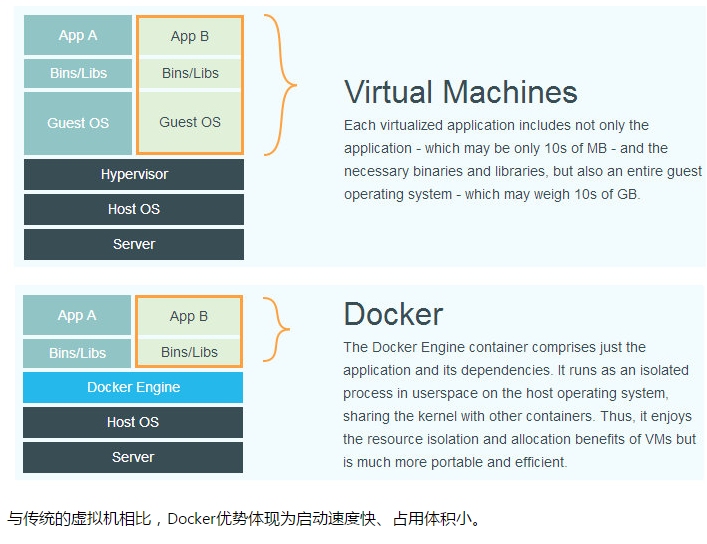
docker是在操作系统层面实现虚拟化,直接复用本地主机的操作系统,而传统虚拟机是在硬件层面实现虚拟化。
二、docker基于C/S架构
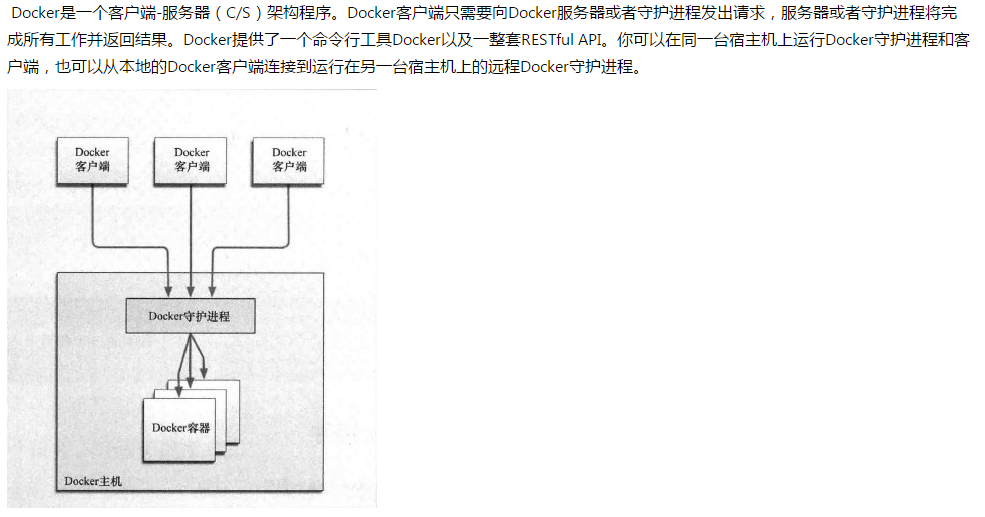
镜像是构建docker的基石,用户需要通过镜像来运行自己的容器。
Registry用来保存用户构建的镜像,分为公有和私有(https://hub.docker.com)
三、docker的安装
-sudo yum update -sudo yum install -y yum-utils device-mapper-persistent-data lvm2 -sudo yum install docker-ce -docker -v 查看一下docker版本
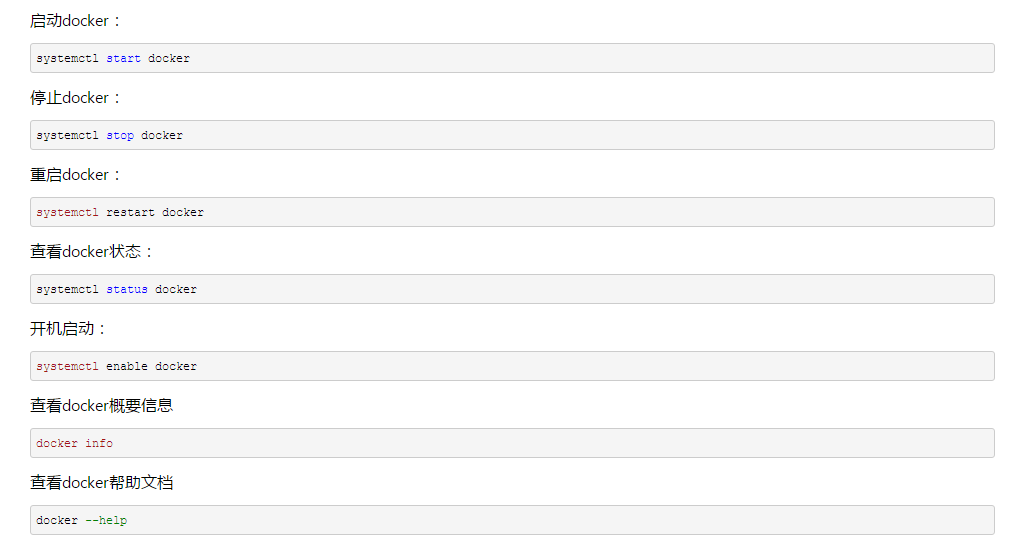
docker服务器的开启与关闭
镜像操作
-docker images 查看所有镜像 -docker pull 镜像名称 下载镜像 -docker rmi 镜像ID 删除镜像
容器相关命令
-docker ps 查看正在运行的容器 -docker ps –a - docker run -id --name=testscentos7 centos:7 启动容器 -docker exec -it 容器名称 (或者容器ID) /bin/bash 登录容器 -docker stop 容器名称(或者容器ID) -docker start 容器名称(或者容器ID) -copy文件 -目录挂载 -docker run -di -v /home:/home --name=mycentos322 centos:7 -docker inspect 容器id -查看容器信息 -docker rm id 删除容器
其他命令(https://www.cnblogs.com/xiaoyuanqujing/article/11774978.html)
-部署应用 -部署mysql -docker run -di --name=mysqltest -p 33309:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7 -迁移与备份 -容器打包成镜像 -docker commit django_3.7 django_3.7_img -Dockerfile -正常构建镜像 docker build -t='xxxyyy' . WORKDIR /home/lqz -私有仓库 -docker pull registry -docker run -di --name=registry123 -p 5000:5000 registry {"insecure-registries":["127.0.0.1:5000"]} -把镜像传到私有仓库 -docker tag ooo 39.100.80.124:5000/ooo 打标签 -docker push 39.100.80.124:5000/ooo 上传
四、提高网站的并发量
-前端: -图片 -七牛云(cdn) -自己搭的文件存储 -使用精灵图 -前端缓存:过期时间 -动静分离 -dns解析---》ip -负载均衡硬件 -nginx -集群化的部署 -进入程序 -django是同步框架 -做异步任务:celery -并发执行 -数据索引优化---查询速度高 -缓存(redis):双写一致性、缓存穿透,缓存雪崩 -主从--读写分离(django) -微服务 -服务拆分,用其它语言写 -api网关 -服务间调用:resful接口 -rpc:远程过程调用 -rpc框架:gRPC -阿里开源一个:Dubbo
五、正向代理与反向代理的区别(https://www.cnblogs.com/Anker/p/6056540.html)
正向代理:代理共享上网;客户端代理权限管理
反向代理:保证内网安全,防止web攻击;负载均衡
六、缓存穿透、缓存雪崩
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。如果key对应的value是一定不存在的,
并且对该key并发请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。 解决方案:1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。 2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。【感觉应该用的不多吧】 当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。 解决方案:1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。 2:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。 3:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期(此点为补充)
七、用redis实现分布式锁(https://www.cnblogs.com/liuqingzheng/p/11080501.html)
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。 (2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。 (3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
八、分布式id(雪花算法)
解决不同机器生成相同id问题(https://www.cnblogs.com/liuqingzheng/p/11074623.html)
九、数据库主从(https://www.cnblogs.com/xiaoyuanqujing/articles/11796376.html)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号