DRF----------(三)
一.配置文件settings.py (连接Mysql)
INSTALLED_APPS = [ # ... 'rest_framework', ] DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'dg_proj', 'USER': 'root', 'PASSWORD': 'root', } } """ 任何__init__文件 import pymysql pymysql.install_as_MySQLdb() """ LANGUAGE_CODE = 'zh-hans' TIME_ZONE = 'Asia/Shanghai' USE_I18N = True USE_L10N = True USE_TZ = False MEDIA_URL = '/media/' MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
二.路由分发
# 主 from django.conf.urls import url, include from django.contrib import admin from django.views.static import serve from django.conf import settings urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^api/', include('api.urls')), url(r'^media/(?P<path>.*)', serve, {'document_root': settings.MEDIA_ROOT}), ] # 子(app中) from django.conf.urls import url from . import views urlpatterns = [ ]
函数传参回顾 (位置参数 ------ 默认参数 ------ * ------关键字参数 (有值/无值) )
# * 前都是位置参数:无值位置必须赋值,有值位置可以不要赋值,必须在无值位置之后 # * 后都是关键字参数:无值关键字必须赋值,有值关键字可以不要赋值,都是指名道姓传参,所以顺序任意 # * 可以紧跟一个变量,用来接收所有未接收完的位置参数 def fn(a, b, c=0, *, d=0, x): print(a) print(b) print(c) print(d) print(x) fn(10, 20, 30, x=30, d=100)
三.特殊注释
# TODO 今天做到这了,结合TODO控制台可以完成快速定位 # 假设a就是str类型,实际操作值不是0,而是不能明确标识的字符串 a = 0 # type: str # 再书写 a. 就可以提示 str 方法 x, y = 0, 0 # type: str, dict def z(a:str, b:dict): pass def fn(a, b): """ :param str a: :param dict b: :return: """
四.多表设计
""" Book表 name、price、img、authors、publish、is_delete、create_time Publish表 name、address、is_delete、create_time Author表: name、age、is_delete、create_time AuthorDetail表 mobile, author、is_delete、create_time BaseModel基表 is_delete、create_time 上面四表继承基表,可以继承两个字段 """
表关系:
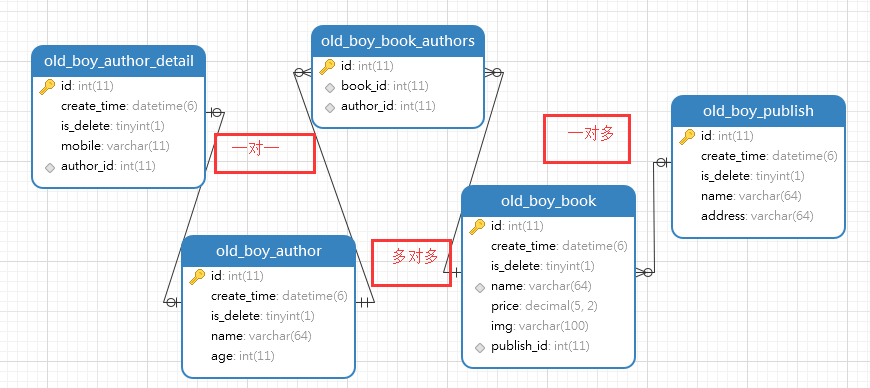
注: 实际开发中要去除外键关联,用逻辑建立外键关系,但不影响orm操作
基表:utils/model.py
from django.db import models class BaseModel(models.Model): create_time = models.DateTimeField(auto_now_add=True, null=True) is_delete = models.BooleanField(default=False) class Meta: # 抽象表,不会完成数据库迁移 abstract = True
"""
多表关系总结
一对一:Author、AuthorDetail两表
1)关系字段放在AuthorDetail表中:作者删除详情也随即删除,详情删除作者仍保留
2)作者找详情用 外键related_name(detail),或者表名小写(authordetail);详情找作者用 外键字段(author)
3)db_constraint断开表关联,on_delete规定逻辑关联删除动作,models.CASCADE级联删除
author = models.OneToOneField(to='Author', null=True,
related_name='detail',
db_constraint=False,
on_delete=models.CASCADE
)
一对多:Book、Publish两表
1)关系字段放在Book表中(多的一方):出版社删除书外键不动,书删除没有任何影响
2)出版社找书用 外键related_name(books),或者通过表名小写_set(book_set.all());书找出版社 外键字段(publish)
3)db_constraint断开表关联,on_delete规定逻辑关联删除动作,models.DO_NOTHING关联无动作
publish = models.ForeignKey(to='Publish', null=True,
related_name='books',
db_constraint=False,
on_delete=models.DO_NOTHING,
)
扩展:外键字段的其它关联方式
1)断关联,删除关联表记录,外键值置空
db_constraint=False, on_delete=models.SET_NULL, null=True,
2)断关联,删除关联表记录,外键值置默认值
db_constraint=False, on_delete=models.SET_DEFAULT, default=1,
多对多:Book、Author两表
1)关系字段放在任意一方都可以:出版社删除或书删除彼此不影响,但关系表一定级联删除
2)正向找 外键字段,反向找 外键字段related_name
3)db_constraint断开表关联,on_delete不存在(不设置,本质在第三张表中设置,且一定是级联)
authors = models.ManyToManyField(to='Author', null=True,
related_name='books',
db_constraint=False,
)
"""
from django.db import models # 多表 # 书表 出版社表 作者表 """ Book表: name、price、img、authors、publish、is_delete、create_time Publish表: name、address、is_delete、create_time Author表: name、age、is_delete、create_time AuthorDetail表: mobile, author、is_delete、create_time """ from utils.model import BaseModel class Book(BaseModel): name = models.CharField(max_length=64) price = models.DecimalField(max_digits=5, decimal_places=2) img = models.ImageField(upload_to='img', default='img/default.png') publish = models.ForeignKey(to='Publish', null=True, related_name='books', db_constraint=False, on_delete=models.DO_NOTHING, # on_delete=models.SET_NULL, null=True, # on_delete=models.SET_DEFAULT, default=1, ) authors = models.ManyToManyField(to='Author', null=True, related_name='books', db_constraint=False, ) class Meta: db_table = 'old_boy_book' verbose_name = '书籍' verbose_name_plural = verbose_name def __str__(self): return self.name class Publish(BaseModel): name = models.CharField(max_length=64) address = models.CharField(max_length=64) class Meta: db_table = 'old_boy_publish' verbose_name = '出版社' verbose_name_plural = verbose_name def __str__(self): return self.name class Author(BaseModel): name = models.CharField(max_length=64) age = models.IntegerField() class Meta: db_table = 'old_boy_author' verbose_name = '作者' verbose_name_plural = verbose_name def __str__(self): return self.name class AuthorDetail(BaseModel): mobile = models.CharField(max_length=11) # related_name 反向查询的 字段 eg:author_obj.detail.mobile # 一对一外键:放在拆出来的表,断关联,设置级联 author = models.OneToOneField(to='Author', null=True, related_name='detail', db_constraint=False, on_delete=models.CASCADE ) class Meta: db_table = 'old_boy_author_detail' verbose_name = '作者详情' verbose_name_plural = verbose_name def __str__(self): return '%s的详情' % self.author.name
import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "dg_proj.settings") import django django.setup() from api import models # 一对一 # author = models.Author.objects.first() # type: models.Author # print(author.name) # print(author.detail.mobile) # author.delete() # author_detail = models.AuthorDetail.objects.first() # type: models.AuthorDetail # print(author_detail.mobile) # print(author_detail.author.name) # author_detail.delete() # 一对多 # publish = models.Publish.objects.filter(pk=2).first() # type: models.Publish # print(publish.name) # print(publish.books.first().name) # publish.delete() # publish = models.Publish.objects.filter(is_delete=False).first() # type: models.Publish # if publish: # print(publish.name) # print(publish.books.first().name) # publish.is_delete = True # publish.save() # book = models.Book.objects.first() # type: models.Book # print(book.name) # print(book.publish.name) # book.delete() # 多对多 # book = models.Book.objects.first() # type: models.Book # print(book.name) # print(book.authors.first().name) # book.delete() author = models.Author.objects.first() # type: models.Author print(author.name) print(author.books.first().name) author.delete()
序列化总结:
1)在自定义的ModelSerializer类中设置class Meta
model 绑定序列化相关的模型类
fields 插拔方式指定序列化字段
2)在模型类中通过 方法属性 自定义跨表查询的字段,在fields中插拔
3)如果就使用外键字段完成连表深度查询,用序列化深度
外键字段 = 外键序列化类(many=True|False)
4) 了解:在ModelSerializer中不建议使用,如何书写了必须在fields中声明使用
p_n = serializers.SerializerMethodField()
def get_p_n(self, obj: models.Book):
return obj.publish.name
5) fields = '__all__' # 所有字段
exclude = ('id', 'is_delete') # 刨除某些字段,与__all__不可联用
depth = 1 # 跨表自动深度(展示外键表的所有字段)
from rest_framework import serializers from . import models class PublishModelSerializer(serializers.ModelSerializer): class Meta: model = models.Publish fields = ('name', 'address') class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = models.Author fields = ('name', 'age', 'mobile') class BookModelSerializer(serializers.ModelSerializer): # 正向序列化深度 # (不建议:必须用外键名才需要序列化深度, # 建议:自定义外键序列化名,在model类中插拔字段(属性方法)) publish = PublishModelSerializer() authors = AuthorModelSerializer(many=True) # 了解:在ModelSerializer中不建议使用,如何书写了必须在fields中声明使用 # p_n = serializers.SerializerMethodField() # def get_p_n(self, obj: models.Book): # return obj.publish.name class Meta: model = models.Book fields = ('name', 'price', 'img', 'publish_name', 'authors_info', 'publish', 'authors') # 了解 # fields = '__all__' # 所有字段 # # exclude = ('id', 'is_delete') # 刨除某些字段 # depth = 1 # 跨表自动深度(展示外键表的所有字段)
from rest_framework.views import APIView from utils.response import APIResponse from . import models, serializers class BookAPIView(APIView): def get(self, request, *args, **kwargs): book_query = models.Book.objects.all() book_ser = serializers.BookModelSerializer(book_query, many=True) return APIResponse(0, 'ok', results=book_ser.data)
# 自定义model类的方法属性,完成插拔式跨表查询 class Book(BaseModel): # ... @property def publish_name(self): return self.publish.name @property def authors_info(self): author_list = [] for author in self.authors.all(): author_list.append({ 'name': author.name, 'age': author.age, 'mobile': author.detail.mobile }) return author_list class Author(BaseModel): # ... @property def mobile(self): return self.detail.mobile
反序列化总结:
1)在自定义的ModelSerializer类中设置class Meta
model 绑定反序列化相关的模型类
fields 插拔方式指定反序列化字段
extra_kwargs 定义系统校验字段的规则
2)可以自定义局部钩子和全局钩子完成字段的复杂校验规则
3)不需要重写create和update完成增加修改,ModelSerializer类已经帮我们实现了
class BookModelDeserializer(serializers.ModelSerializer): class Meta: model = models.Book fields = ('name', 'price', 'publish', 'authors') extra_kwargs = { 'name': { 'min_length': 3, 'error_messages': { 'min_length': '太短' } }, 'publish': { 'required': True }, 'authors': { 'required': True }, } # 自定义校验 def validate_name(self, value): if 'sb' in value: raise serializers.ValidationError('书名有敏感词汇') return value def validate(self, attrs): name = attrs.get('name') publish = attrs.get('publish') if models.Book.objects.filter(name=name, publish=publish): raise serializers.ValidationError({'book': '书籍以存在'}) return attrs
{ "name": "赵是孤儿", "price": 12.22, "publish":1, "authors":[1,2] }
from rest_framework.views import APIView from utils.response import APIResponse from . import models, serializers class BookAPIView(APIView): def get(self, request, *args, **kwargs): book_query = models.Book.objects.all() book_ser = serializers.BookModelSerializer(book_query, many=True) return APIResponse(0, 'ok', results=book_ser.data) def post(self, request, *args, **kwargs): book_ser = serializers.BookModelDeserializer(data=request.data) if book_ser.is_valid(): book_ser.save() return APIResponse(0, 'ok') else: return APIResponse(1, '添加失败', results=book_ser.errors)
整合:
1)extra_kwargs 中通过 write_only(反序列化) 与 read_only(序列化) 区别
2)与数据库关联的反序列化字段不要自定义,序列化字段可以任意自定义
3)参与反序列化,但不参与数据入库的字段,需要在序列化类中自定义 (re_password)
re_name = serializers.CharField(write_only=True)
class PublishModelSerializer(serializers.ModelSerializer): # 自定义不入库的 反序列化 字段 re_name = serializers.CharField(write_only=True) class Meta: model = models.Publish fields = ('name', 're_name', 'address') def validate(self, attrs): name = attrs.get('name') re_name = attrs.pop('re_name') # 剔除 if name != re_name: raise serializers.ValidationError({'re_name': '确认名字有误'}) return attrs
from django.conf.urls import url from . import views urlpatterns = [ # ... url(r'^v2/books/$', views.BookV2APIView.as_view()), url(r'^v2/books/(?P<pk>.*)/$', views.BookV2APIView.as_view()), ]
class Book(BaseModel): # ... class Meta: # ... # 联合唯一 => patch结果修改部分数据就会收到'name'、'publish'联合限制 unique_together = ('name', 'publish')
class BookV2ModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = ('name', 'price', 'publish', 'authors', 'img', 'publish_name', 'authors_info') extra_kwargs = { 'publish': { 'required': True, 'write_only': True }, 'authors': { 'required': True, 'write_only': True }, 'img': { 'read_only': True } } def validate_name(self, value): if 'sb' in value: raise serializers.ValidationError('书名有敏感词汇') return value def validate(self, attrs): name = attrs.get('name') publish = attrs.get('publish') if models.Book.objects.filter(name=name, publish=publish): raise serializers.ValidationError({'book': '书籍以存在'}) return attrs
class BookV2APIView(APIView): def get(self, request, *args, **kwargs): book_query = models.Book.objects.filter(is_delete=False).all() book_ser = serializers.BookV2ModelSerializer(book_query, many=True) return APIResponse(0, 'ok', results=book_ser.data) def post(self, request, *args, **kwargs): book_ser = serializers.BookV2ModelSerializer(data=request.data) if book_ser.is_valid(): book_obj = book_ser.save() return APIResponse(0, 'ok', results=serializers.BookV2ModelSerializer(book_obj).data ) else: return APIResponse(1, '添加失败', results=book_ser.errors) def patch(self, request, *args, **kwargs): pk = kwargs.get('pk') if not pk: return APIResponse(1, 'pk error') try: book_obj = models.Book.objects.get(is_delete=False, pk=pk) except: return APIResponse(1, 'pk no book') book_ser = serializers.BookV2ModelSerializer(partial=True, instance=book_obj, data=request.data) if book_ser.is_valid(): book_obj = book_ser.save() return APIResponse(0, 'ok', results=serializers.BookV2ModelSerializer(book_obj).data ) else: return APIResponse(1, '更新失败', results=book_ser.errors) def delete(self, request, *args, **kwargs): # 单删 /books/(pk)/ # 群删 /books/ 数据包携带 pks => request.data pk = kwargs.get('pk') if pk: pks = [pk] else: pks = request.data.get('pks') if not pks: return APIResponse(1, '删除失败') book_query = models.Book.objects.filter(is_delete=False, pk__in=pks) print(book_query) if not book_query.update(is_delete=True): # 受影响的行得大于0 return APIResponse(1, '删除失败') return APIResponse(0, '删除成功')
注:单删是通过路由有名分组拿到pk值(get请求),群删是发的json数据{ "pk":[2,3] },后端通过request.data获取

 浙公网安备 33010602011771号
浙公网安备 33010602011771号