Django之模型层&ORM操作
一. 单表查询:
1.在模型层创建模型表:
from django.db import models # Create your models here. # 单表查询表 class User(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() register_time = models.DateField()
2.连接MySQL,创建表 (具体操作见https://www.cnblogs.com/sima-3/p/10987276.html)
3.在test.py中进行单表查询测试, 首先配置环境:
from django.test import TestCase # Create your tests here. import os if __name__ == "__main__": os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day58.settings") import django django.setup() from app01 import models
a.新增数据:
方式一:对象的create方法添加记录 user_obj=models.User.objects.create(name='jason',age='18',register_time='2019-6-12') print(user_obj.name) 方式二:对象的save方法添加记录 from datetime import datetime ctime=datetime.now() user_obj=models.User(name='egon',age='18',register_time=ctime) user_obj.save() print(user_obj.register_time)
b.修改数据:
方式一:数据对象更新记录 user_obj=models.User.objects.filter(name='jason').last() user_obj.name='kevin' user_obj.age='18' user_obj.save() 方式二:queryset对象的update方法更新记录 user_list=models.User.objects.filter(pk=6) user_list.update(name='tank')
补充知识点:
update()和save()的区别: 两者都是对数据的修改进行保存操作,但save()会将全部数据都重新写一遍,而 update()只针对
修改项数据,更新效率高耗时少 !!!
c.删除数据:
方式一:数据对象删除记录 user_obj=models.User.objects.filter(name='jason')[0] user_obj.delete() 方式二:queryset对象删除记录 user_list=models.User.objects.filter(age='18') user_list.delete()
d.查询数据:
# < 1 > all(): 查询所有结果 # < 2 > filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 # res = models.User.objects.filter(name='jason',age=17) # filter内可以放多个限制条件但是需要注意的是多个条件之间是and关系 # print(res) # < 3 > get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
(源码就去搂一眼~诠释为何只能是一个对象) # 不推荐使用 # < 4 > exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 # res = models.User.objects.exclude(name='jason') # print(res) # < 5 > order_by(*field): 对查询结果排序('-id') / ('price') # res = models.User.objects.order_by('age') # 默认是升序 # res = models.User.objects.order_by('-age') # 可以在排序的字段前面加一个减号就是降序 # res = models.User.objects.order_by('name') # res = models.User.objects.order_by('-name') # print(res) # < 6 > reverse(): 对查询结果反向排序 >> > 前面要先有排序才能反向 # res = models.User.objects.order_by('age').reverse() # print(res) # < 7 > count(): 返回数据库中匹配查询(QuerySet) 的对象数量。 # res = models.User.objects.count() # res = models.User.objects.all().count() # print(res) # < 8 > first(): 返回第一条记录 # res = models.User.objects.all().first() # res = models.User.objects.all()[0] # 不支持负数的索引取值 # print(res) # < 9 > last(): 返回最后一条记录 # res = models.User.objects.all().last() # print(res) # < 10 > exists(): 如果QuerySet包含数据,就返回True,否则返回False # res = models.User.objects.all().exists() # res1 = models.User.objects.filter(name='jason',age=3).exists() # print(res,res1) # < 11 > values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 # res = models.User.objects.values('name') # 列表套字典 # res = models.User.objects.values('name','age') # 列表套字典 # print(res) # < 12 > values_list(*field): 它与values() 非常相似,它返回的是一个元组序列,values返回的是一个字典序列 # res = models.User.objects.values_list('name','age') # 列表套元祖 # print(res) # < 13 > distinct(): 从返回结果中剔除重复纪录 去重的对象必须是完全相同的数据才能去重 # res = models.User.objects.values('name','age').distinct() # print(res)
e.神奇的双下划线查询 (基于queryset对象操作):
查询年轻大于44岁的用户 # res = models.User.objects.filter(age__gt=44) # print(res) 查询年轻小于44岁的用户 # res = models.User.objects.filter(age__lt=44) # print(res) 查询年轻大于等于44岁的用户 # res = models.User.objects.filter(age__gte=44) # print(res) 查询年轻小于等于44岁的用户 # res = models.User.objects.filter(age__lte=44) # print(res) 查询年龄是44或者22或者73的用户 # res = models.User.objects.filter(age__in=[44,22,73]) # print(res) 查询年龄在22到44范围内 # res = models.User.objects.filter(age__range=[22,44]) # print(res) 查询年份 # res = models.Book.objects.filter(publish_date__year=2019) # print(res) 查询名字中包含字母n的用户 sqlite数据库演示不出来大小写的情况!!! # res = models.Author.objects.filter(name__contains='n') 区分大小写 # res = models.Author.objects.filter(name__icontains='n') 不分大小写 # print(res) 查询名字以j开头的用户 # res = models.User.objects.filter(name__startswith='j') # print(res) 查询名字以n结尾的用户 # res = models.User.objects.filter(name__endswith='n') # print(res)
二.多表查询:
1.在模型层创建模型表:
# 多表查询表 class Book(models.Model): title = models.CharField(max_length=32) price = models.DecimalField(max_digits=8,decimal_places=2) publish_date = models.DateField(auto_now_add=True)
# 配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
# 配置上auto_now=True,每次更新数据记录的时候会更新该字段。
# 外键关系 publish = models.ForeignKey(to='Publish') authors = models.ManyToManyField(to='Author') # 虚拟字段, 信号字段 def __str__(self): return '书籍对象的名字:%s'%self.title class Publish(models.Model): name = models.CharField(max_length=32) addr = models.CharField(max_length=32) email = models.EmailField() # 对应就是varchar类型 def __str__(self): return '出版社对象的名字:%s'%self.name class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() authordetail = models.OneToOneField(to='AuthorDetail') def __str__(self): return '作者对象的名字:%s'%self.name class AuthorDetail(models.Model): phone = models.CharField(max_length=32) addr = models.CharField(max_length=32)
五张表如下图所示(多对多会新增一张表):
先在author, authordetail, publish三张表中填写记录,book, book_author两张表暂不填:
其各表关系如下:
book --------- publish 一对多关系
book --------- author 多对多关系 ------- 产生 book_author
author--------- authordetail 一对一关系
publish 表记录:

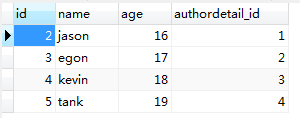
author 表记录:
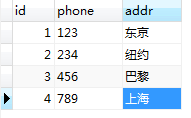
authordetail 表记录:
2.一对多字段的增删改查:
a.在book表中添加记录:

# 方式一:数据对象的create方法添加记录 book_obj=models.Book.objects.create(title='孙子兵法',price='66.88',publish_id=3) print(book_obj.title) # 方式二:数据对象的save方法添加记录 book_obj=models.Book(title='三国志',price='33.66',publish_id=4) book_obj.save() print(book_obj.title)
#除了用publish_id关联book表,还可传publish对象publish_obj,因为book表中有publish字段
publish_obj=models.Publish.objects.filter(pk=4).first()
book_obj=models.Book.objects.create(title='洛神赋',price='98.89',publish=publish_obj)
添加记录后:
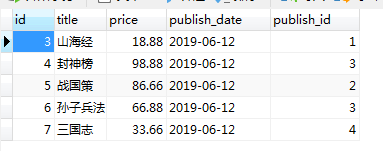
b.在book表中修改记录:
# 方式一:数据对象更新记录 book_obj=models.Book.objects.filter(pk=4).first() book_obj.title='厚黑学' book_obj.publish_id=2 book_obj.save() print(book_obj.title) # 方式二:queryset对象的update方法更新记录 book_list=models.Book.objects.filter(pk=6) publish_obj=models.Publish.objects.filter(pk=4).first() book_list.update(title='红楼梦',publish=publish_obj) print(book_list)
修改记录后:
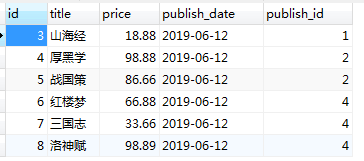
c.在book表中删除记录:
# 方式一:数据对象删除记录 book_obj=models.Book.objects.filter(pk=4)[0] book_obj.delete() # 方式二:queryset对象的update方法删除记录
book_list=models.Book.objects.filter(pk=6)
book_list.delete()
如果删除出版社,相应的书也会被删除(级联删除)
删除记录后:
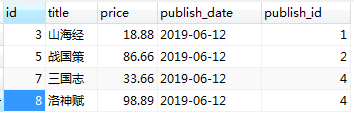
2.多对多字段的增删改查:
a.在book_authors表中添加记录:
给书籍绑定与作者之间的关系:
# 添加关系 add支持传数字或对象,并且都可以传多个
# 方式一:直接添加authors_id
book_obj = models.Book.objects.filter(pk=3).first()
book_obj.authors.add(4)
book_obj.authors.add(2,3)
# 方式二: 添加authors对象
author_obj = models.Author.objects.filter(pk=2).first()
author_obj1 = models.Author.objects.filter(pk=3).first()
book_obj = models.Book.objects.filter(pk=5).first()
book_obj.authors.add(author_obj,author_obj1)
绑定之后:

b.在book_authors表中更新记录:
修改书籍与作者的关系 set() set传的必须是可迭代对象!!!
book_obj = models.Book.objects.filter(pk=3).first() # 可以传数字和对象,并且支持传多个 book_obj.authors.set((2,)) # book_obj.authors.set((1,2,3)) author_list = models.Author.objects.all() #[{},{},...],包含所有的作者对象,主键id=2,3,4,5 book_obj = models.Book.objects.filter(pk=5).first() book_obj.authors.set(author_list)
修改之后:

c.在book_authors表中删除记录:
删除书籍与作者的绑定关系: 需要将queryset打散:
book_obj = models.Book.objects.filter(pk=3).first() book_obj.authors.remove(2) # book_obj.authors.remove(4,3) # author_obj = models.Author.objects.all().first() # book_obj.authors.remove(author_obj) book_obj = models.Book.objects.filter(pk=5).first() author_list = models.Author.objects.all() book_obj.authors.remove(*author_list)
正好将所有记录都删完了 !!!
补充: 清空 clear() 清空的是当前这个表记录中id为3的book对应的所有绑定关系
# book_obj = models.Book.objects.filter(pk=3).first() # book_obj.authors.clear()
三.
# 正向与方向的概念解释 # 一对一 # 正向:author---关联字段在author表里--->authordetail 按字段 # 反向:authordetail---关联字段在author表里--->author 按表名小写 # 查询jason作者的手机号 正向查询 # 查询地址是 :山东 的作者名字 反向查询 # 一对多 # 正向:book---关联字段在book表里--->publish 按字段 # 反向:publish---关联字段在book表里--->book 按表名小写_set.all() 因为一个出版社对应着多个图书 # 多对多 # 正向:book---关联字段在book表里--->author 按字段 # 反向:author---关联字段在book表里--->book 按表名小写_set.all() 因为一个作者对应着多个图书 # 连续跨表 # 查询图书是三国演义的作者的手机号,先查书,再正向查到作者,在正向查手机号 # 总结:基于对象的查询都是子查询,这里可以用django配置文件自动打印sql语句的配置做演示
1.基于对象的表查询
a. 正向:
# 一对多 # 查询书籍是三国志的出版社邮箱 book_obj = models.Book.objects.filter(title='三国志').first() print(book_obj.publish.email) # 多对多 # 查询书籍是山海经的作者的姓名 book_obj = models.Book.objects.filter(title='山海经').first() print(book_obj.authors) # app01.Author.None,多对多必须用all查询 print(book_obj.authors.all()) # <QuerySet [<Author: 作者对象的名字:jason>]> # 一对一 # 查询作者为jason电话号码 user_obj = models.Author.objects.filter(name='jason').first() print(user_obj.authordetail.phone)
b.反向:
# 一对多字段的反向查询 # 查询出版社是江苏日报出版社出版的书籍 publish_obj = models.Publish.objects.filter(name='江苏日报').first() print(publish_obj.book_set) # app01.Book.None print(publish_obj.book_set.all()) #<QuerySet [<Book: 书籍对象的名字:三国志>, <Book: 书籍对象的名字:洛神赋>]>
# 多对多字段的反向查询 # 查询作者jason写过的所有的书 author_obj = models.Author.objects.filter(name='jason').first() print(author_obj.book_set) # app01.Book.None print(author_obj.book_set.all()) # < QuerySet[ < Book: 书籍对象的名字:山海经 >, < Book: 书籍对象的名字:三国志 >] >
# 一对一字段的反向查询,一对一不用加_set,直接可跨表拿到name字段的值 # 查询作者电话号码是456的作者姓名 authordetail_obj = models.AuthorDetail.objects.filter(phone=456).first() print(authordetail_obj.author.name)
2.基于双下滑线的查询:
a.正向:
# 查询书籍为洛神赋的出版社地址 res = models.Book.objects.filter(title='洛神赋').values('publish__addr','title') print(res) # < QuerySet[{'publish__addr': '江苏', 'title': '洛神赋'}] >
# 查询书籍为山海经的作者的姓名 res = models.Book.objects.filter(title='山海经').values("authors__name",'title') print(res) # < QuerySet[{'authors__name': 'jason', 'title': '山海经'}] >
# 查询作者为jason的家乡 res = models.Author.objects.filter(name='jason').values('authordetail__addr') print(res) # < QuerySet[{'authordetail__addr': '东京'}] >
b.反向:
# 查询人民日报出版社出版的书名 res = models.Publish.objects.filter(name='人民日报').values('book__title') print(res) # < QuerySet[{'book__title': '山海经'}] > # 查询电话号码为789的作者姓名 res = models.AuthorDetail.objects.filter(phone=789).values('author__name') print(res) # < QuerySet[{'author__name': 'tank'}] > # 查询作者为jason的写的书的名字 res = models.Author.objects.filter(name='jason').values('book__title') print(res) # < QuerySet[{'book__title': '山海经'}, {'book__title': '三国志'}] >
c.跨三张表查询:
# 查询书籍为三国志的作者的电话号码 res = models.Book.objects.filter(title='三国志').values('authors__authordetail__phone') print(res) # < QuerySet[{'authors__authordetail__phone': '123'}] >
d.同一问题不同角度查询:
# 查询jason作者的手机号 # 正向 res = models.Author.objects.filter(name='jason').values('authordetail__phone') print(res) # < QuerySet[{'authordetail__phone': '123'}] > # 反向 res = models.AuthorDetail.objects.filter(author__name='jason').values('phone') print(res) # < QuerySet[{'phone': '123'}] >
# 查询出版社为新华日报出版社的所有图书的名字和价格 # 正向 res = models.Publish.objects.filter(name='新华日报').values('book__title','book__price') print(res) # < QuerySet[{'book__title': '战国策', 'book__price': Decimal('86.66')}] > # 反向 res = models.Book.objects.filter(publish__name='新华日报').values('title','price') print(res) # < QuerySet[{'title': '战国策', 'price': Decimal('86.66')}] >
# 查询人民日报出版社出版的价格大于10的书 # 正向 res = models.Publish.objects.filter(name="人民日报",book__price__gt=10).values('book__title','book__price') print(res) # < QuerySet[{'book__title': '山海经', 'book__price': Decimal('18.88')}] > # 反向 res = models.Book.objects.filter(price__gt=10,publish__name='人民日报').values('title','price') print(res) # < QuerySet[{'title': '山海经', 'price': Decimal('18.88')}] >
四.聚合查询 aggregate
from django.db.models import Max,Min,Count,Sum,Avg # 查询所有书籍的作者个数 res = models.Book.objects.aggregate(count_num=Count('authors')) print(res) # {'count_num': 3} # 查询所有出版社出版的书的平均价格 res = models.Publish.objects.aggregate(avg_price=Avg('book__price')) print(res) # {'avg_price': 59.5225} # 统计江苏日报出版社出版的书籍的个数 res = models.Publish.objects.filter(name='江苏日报').aggregate(count_num=Count('book__id')) print(res) # {'count_num': 2}
五.分组查询 (group_by) annotate
# 统计每个出版社出版的书的平均价格 res = models.Publish.objects.annotate(avg_price=Avg('book__price')).values('name','avg_price') print(res) # < QuerySet[{'name': '人民日报', 'avg_price': 18.88}, {'name': '新华日报', 'avg_price': 86.66}, # {'name': '江苏日报', 'avg_price': 66.275}, {'name': '上海日报', 'avg_price': None}] >
# 统计每一本书的作者个数 res = models.Book.objects.annotate(count_num=Count('authors')).values('title','count_num') print(res) # < QuerySet[{'title': '山海经', 'count_num': 1}, {'title': '战国策', 'count_num': 0}, # {'title': '三国志', 'count_num': 1}, {'title': '洛神赋', 'count_num': 1}] >
# 统计出每个出版社卖的最便宜的书的价格 res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price') print(res) # 查询每个作者出的书的总价格 res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price') print(res) # <QuerySet [{'name': 'jason', 'sum_price': Decimal('52.54')}, {'name': 'kevin', 'sum_price': Decimal('98.89')}, # {'name': 'egon', 'sum_price': None}, {'name': 'tank', 'sum_price': None}]>
六.SQL语句查询:
配置文件配置参数查看所有orm操作内部的sql语句,丢到settings.py文件即可 LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
七.补充速查表:
orm简单的增删改查语句: 1.新增一条或多条记录: a . models.UserInfo.objects.create(name='lxx',age=23, ut_id=2) b. dict = {"name":'xxx', 'age':23, 'ut_id':3} models.UserInfo.objects.create(**dict) c.info = [ models.UserInfo(name='root1', age=34, ut_id=1), models.UserInfo(name='root2', age=35, ut_id=2), models.UserInfo(name='root3', age=36, ut_id=1), models.UserInfo(name='root4', age=37, ut_id=3), models.UserInfo(name='root5', age=32, ut_id=1), ] models.UserInfo.objects.bulk_create(info) 2.删除: models.UserInfo.objects.filter(id=3).delete() 3.更新: models.UserInfo.objects.filter(id=3).update(name='lll', age=23) 4.查询: res = models.UserInfo.objects.all() queryset对象, [obj,obj,........] res = models.UserInfo.objects.values('name', 'age') queryset对象, [{},{},........] res = models.UserInfo.objects.values_list('name', 'age') queryset对象, [(),(),........] res = models.UserInfo.objects.only('name') queryset对象, [object,object........],包含id字段 res = models.UserInfo.objects.first() object对象 res = models.UserInfo.objects.filter(id=3) queryset对象 res = models.UserInfo.objects.filter(id__gt=3) res = models.UserInfo.objects.filter(id__lte=3) 正向查询: ``` res = models.UserInfo.objects.all() for obj in res: print(obj.name, obj.age, obj.ut.title) #ut是userinfo表连接另一张表的外键字段.obj.ut其实也是一个object对象,多对多表会有多个,
可用obj.ut.all()获取 ``` 反向查询: res = models.UserType.objects.all() for obj in res: 表名小写_set print(obj.title, obj.userinfo_set.all()) releate_name的方式(当外键不在当前表中,可借助related_name中的值跳到第二张表中): class UserInfo(models.Model): ### 主键自增id不用写, 默认会加上 name = models.CharField(max_length=32, null=True) age = models.IntegerField(null=True) ut = models.ForeignKey("UserType", null=True, related_name='users') res = models.UserType.objects.all() for obj in res: print(obj.title, obj.users.all()) and条件查询: res = models.UserInfo.objects.filter(id=2, name='zekai') 排除查询: res = models.UserInfo.objects.exclude(id=4) in / not in: res = models.UserInfo.objects.filter(id__in=[2,4,5]) res = models.UserInfo.objects.exclude(id__in=[1,2]) between...and:(包含起始id,45678) res = models.UserInfo.objects.filter(id__range=[4,8]) like:(i表示忽略大小写) ##### where name like 'like%' res = models.UserInfo.objects.filter(name__startswith="ze") res = models.UserInfo.objects.filter(name__istartswith="zekai") ##### where name like '%kk' res = models.UserInfo.objects.filter(name__endswith="kkk") res = models.UserInfo.objects.filter(name__iendswith="jjj") ##### where name like '%hhh%' res = models.UserInfo.objects.filter(name__contains='hhh') res = models.UserInfo.objects.filter(name__icontains='ggg') 可写正则表达式匹配: res = models.UserInfo.objects.filter(name__regex="^zekai$") count: #### select count(*) from userinfo where id>3; #### select count(id) from userinfo where id>3; res = models.UserInfo.objects.filter(id__gt=3).count() order by: ##### order by id desc, age asc; #### - :降序 res = models.UserInfo.objects.all().order_by('-id','age') group by: ###### select id, sum(age) as s, username from userinfo group by username from django.db.models import Count, Min, Max, Sum res = models.UserInfo.objects.values("name").annotate(s=Sum('age')) print(res.query) ### select id, sum(age) as s, username from userinfo group by username having s > 50; res = models.UserInfo.objects.values("name").annotate(s=Sum('age')).filter(s__gt=50) limit(按queryset对象列表切片分页) ##### limit 0, 10 分页 res = models.UserInfo.objects.all()[1:4] # print(res) defer(与only相反,但不能排除id字段) res = models.UserInfo.objects.defer('id') or Q from django.db.models import Q res = models.UserInfo.objects.filter( Q(Q(id__gt=3) | Q(name='zekai')) & Q(age=23) ) F from django.db.models import F models.UserInfo.objects.update(name=F('name')+1) from django.db.models.functions import Concat from django.db.models import Value models.Product.objects.update(name=Concat(F('name'),Value('爆款'))) 原生sql 类似pymysql # from django.db import connection, connections # cursor = connection.cursor() # cursor = connections['default'].cursor() # cursor.execute("""SELECT * from auth_user where id = %s""", [1]) # row = cursor.fetchone() # print(row) #### distinct # models.UserInfo.objects.values("name", 'age').distinct('name') # print(res.query) ### 查看上述代码生成的sql语句 return HttpResponse('ok')
八.自关联
- 自关联 - 多对多关联 models.py: #### 自关联 class User(models.Model): name = models.CharField(max_length=32) gender_list = [ (1,'男'), (2,'女') ] gender = models.IntegerField(choices=gender_list, default=1) m = models.ManyToManyField('User') views.py: #### 查询和zekai约会的姑娘 res = models.User.objects.filter(name='zekai', gender=1).first() #print(res) ### obj objs = res.m.all() ''' 1. select * from app01_user_m where from_user_id = 1 ### to_user_id=[3,4] 2. select * from app01_user where id in (3,4) ''' for obj in objs: print(obj.name) #### 查询和cuihua约会的男生 res = models.User.objects.filter(name='cuihua', gender=2).first() objs = res.user_set.all() ''' 1. select * from app01_user_m where to_user_id = 3 ### from_user_id=[1,2] 2. select * from app01_user where id in (1,2) ''' for obj in objs: print(obj.name) - 一对多关联 文章表 article: id title 1 xxxxx 2 llll BBS 评论表comment: id content article_id reply_id uid 1 xxx 1 0 1 2 kkkk 1 0 2 3 mmmm 1 0 3 4 bbbb 2 0 5 5 llll 1 1 6 bcjxzb 2 4 class Comment: content = models.charField(max_length=255) article = models.ForeignKey("article") reply = models.ForeignKey('Comment', default=0) xxx llll kkkk mmmm bbbb bcjxzb
九.反向连接数据库建模
1. 修改setting文件,在setting里面设置你要连接的数据库类型和连接名称,地址之类,和创建新项目的时候一致 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'sqlexam', 'USER': 'root', 'PASSWORD': 'root123456', 'HOST': '127.0.0.1', 'PORT': 3306 } } 接下来就可以根据数据库数据生成对应的models模型文件 2、生成模型文件 ```python python3 manage.py inspectdb ``` 3、将模型文件导入到app当中 创建app ```python python3 manage.py startapp 'app名字' ``` 将模型导入创建的app中 ```python python3 manage.py inspectdb > app/models.py ```

 浙公网安备 33010602011771号
浙公网安备 33010602011771号