HashMap和LinkedHashMap
http://blog.csdn.net/justloveyou_/article/details/71713781
1.原理
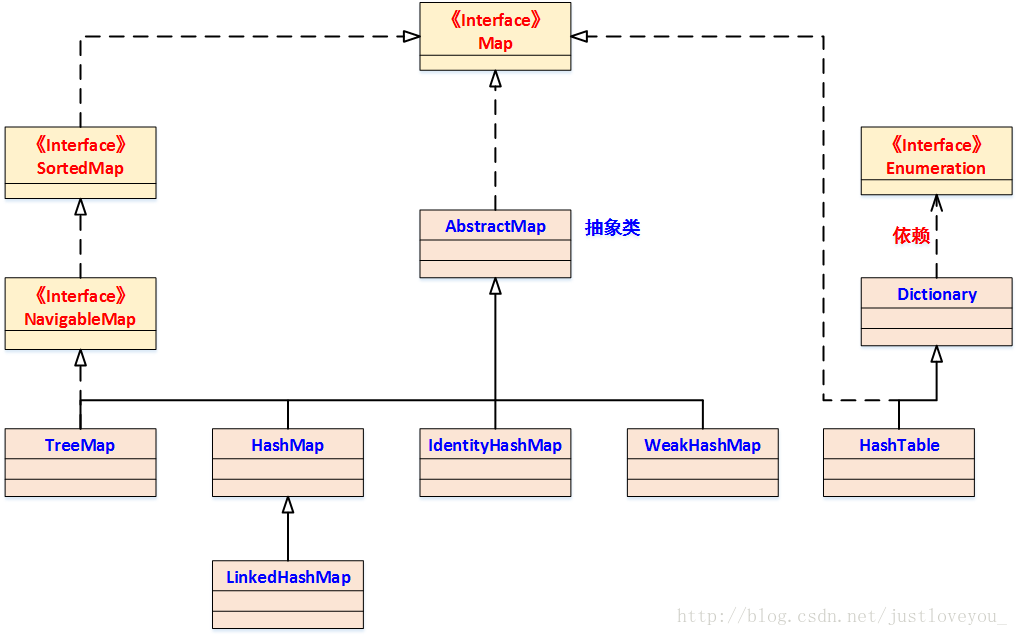
笔者曾在《Map 综述(一):彻头彻尾理解 HashMap》一文中提到,HashMap 是 Java Collection Framework 的重要成员,也是Map族(如下图所示)中我们最为常用的一种。不过遗憾的是,HashMap是无序的,也就是说,迭代HashMap所得到的元素顺序并不是它们最初放置到HashMap的顺序。HashMap的这一缺点往往会造成诸多不便,因为在有些场景中,我们确需要用到一个可以保持插入顺序的Map。庆幸的是,JDK为我们解决了这个问题,它为HashMap提供了一个子类 —— LinkedHashMap。虽然LinkedHashMap增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。特别地,该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap 和 保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。
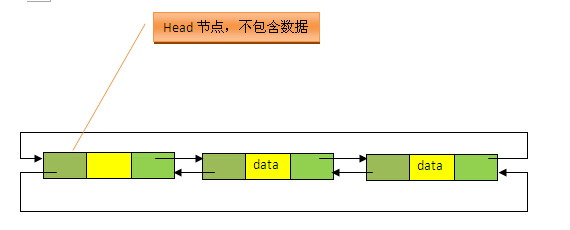
本质上,HashMap和双向链表合二为一即是LinkedHashMap。所谓LinkedHashMap,其落脚点在HashMap,因此更准确地说,它是一个将所有Entry节点链入一个双向链表双向链表的HashMap。在LinkedHashMapMap中,所有put进来的Entry都保存在如下面第一个图所示的哈希表中,但由于它又额外定义了一个以head为头结点的双向链表(如下面第二个图所示),因此对于每次put进来Entry,除了将其保存到哈希表中对应的位置上之外,还会将其插入到双向链表的尾部。
![![哈希表.png-10.2kB][4]](https://img-blog.csdn.net/20170317181650025?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvanVzdGxvdmV5b3Vf/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
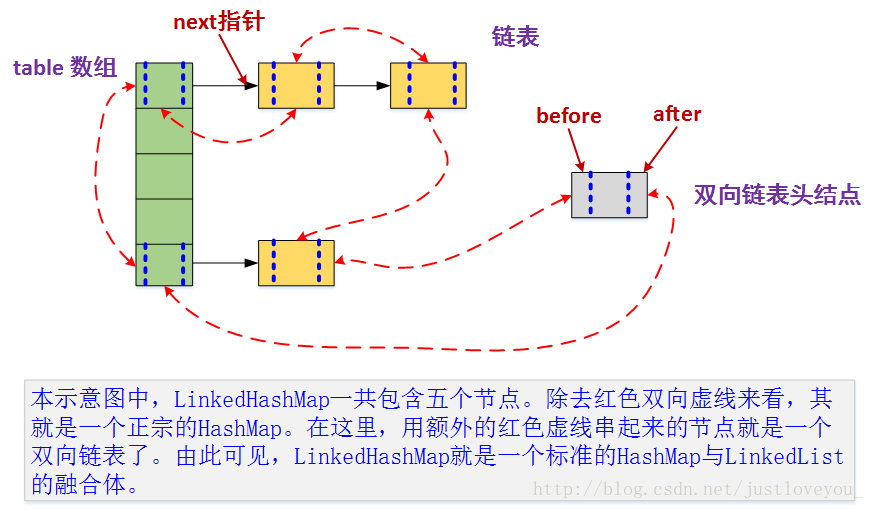
更直观地,下图很好地还原了LinkedHashMap的原貌:HashMap和双向链表的密切配合和分工合作造就了LinkedHashMap。特别需要注意的是,next用于维护HashMap各个桶中的Entry链,before、after用于维护LinkedHashMap的双向链表,虽然它们的作用对象都是Entry,但是各自分离,是两码事儿。
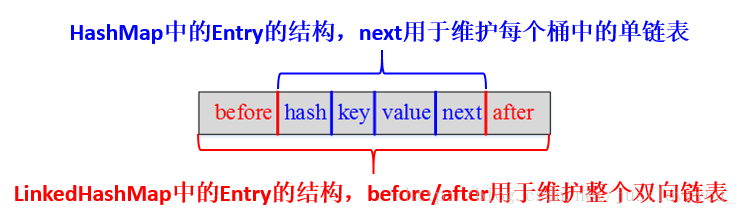
HashMap与LinkedHashMap的Entry结构示意图如下图所示:
基本元素 Entry
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了Entry。LinkedHashMap中的Entry增加了两个指针 before 和 after,它们分别用于维护双向链接列表。特别需要注意的是,next用于维护HashMap各个桶中Entry的连接顺序,before、after用于维护Entry插入的先后顺序的,源代码如下:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}LinkedHashMap 的数据结构
本质上,LinkedHashMap = HashMap + 双向链表,也就是说,HashMap和双向链表合二为一即是LinkedHashMap。也可以这样理解,LinkedHashMap 在不对HashMap做任何改变的基础上,给HashMap的任意两个节点间加了两条连线(before指针和after指针),使这些节点形成一个双向链表。在LinkedHashMapMap中,所有put进来的Entry都保存在HashMap中,但由于它又额外定义了一个以head为头结点的空的双向链表,因此对于每次put进来Entry还会将其插入到双向链表的尾部。
2. LinkedHashMap 存取小结
LinkedHashMap 的存取过程基本与HashMap基本类似,只是在细节实现上稍有不同,这是由LinkedHashMap本身的特性所决定的,因为它要额外维护一个双向链表用于保持迭代顺序。在put操作上,虽然LinkedHashMap完全继承了HashMap的put操作,但是在细节上还是做了一定的调整,比如,在LinkedHashMap中向哈希表中插入新Entry的同时,还会通过Entry的addBefore方法将其链入到双向链表中。在扩容操作上,虽然LinkedHashMap完全继承了HashMap的resize操作,但是鉴于性能和LinkedHashMap自身特点的考量,LinkedHashMap对其中的重哈希过程(transfer方法)进行了重写。在读取操作上,LinkedHashMap中重写了HashMap中的get方法,通过HashMap中的getEntry方法获取Entry对象。在此基础上,进一步获取指定键对应的值。
3. LinkedListMap与LRU小结
使用LinkedHashMap实现LRU的必要前提是将accessOrder标志位设为true以便开启按访问顺序排序的模式。我们可以看到,无论是put方法还是get方法,都会导致目标Entry成为最近访问的Entry,因此就把该Entry加入到了双向链表的末尾:get方法通过调用recordAccess方法来实现;put方法在覆盖已有key的情况下,也是通过调用recordAccess方法来实现,在插入新的Entry时,则是通过createEntry中的addBefore方法来实现。这样,我们便把最近使用的Entry放入到了双向链表的后面。多次操作后,双向链表前面的Entry便是最近没有使用的,这样当节点个数满的时候,删除最前面的Entry(head后面的那个Entry)即可,因为它就是最近最少使用的Entry。
我们知道,当accessOrder标志位为true时,表示双向链表中的元素按照访问的先后顺序排列,可以看到,虽然Entry插入链表的顺序依然是按照其put到LinkedHashMap中的顺序,但put和get方法均有调用recordAccess方法(put方法在key相同时会调用)。
recordAccess方法判断accessOrder是否为true,如果是,则将当前访问的Entry(put进来的Entry或get出来的Entry)移到双向链表的尾部(key不相同时,put新Entry时,会调用addEntry,它会调用createEntry,该方法同样将新插入的元素放入到双向链表的尾部,既符合插入的先后顺序,又符合访问的先后顺序,因为这时该Entry也被访问了);
当标志位accessOrder的值为false时,表示双向链表中的元素按照Entry插入LinkedHashMap到中的先后顺序排序,即每次put到LinkedHashMap中的Entry都放在双向链表的尾部,这样遍历双向链表时,Entry的输出顺序便和插入的顺序一致,这也是默认的双向链表的存储顺序。
---------------------
作者:黄小斜
来源:CSDN
原文:https://blog.csdn.net/a724888/article/details/80290276
版权声明:本文为博主原创文章,转载请附上博文链接!
LinkedHashMap重写了HashMap 的迭代器,它使用其维护的双向链表进行迭代输出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号