

netty高低水位流控(yet)
https://blog.csdn.net/feiyingHiei/article/details/78735754?utm_source=blogxgwz9
有源码分析
在启动Netty bootstrap的时候可以设置ChannelOption选项,其中ChannelOption中有一项WRITE_BUFFER_HIGH_WATER_MARK选项和WRITE_BUFFER_LOW_WATER_MARK选项,,此配置写缓冲区(OutbounduBuffer)相关,此配置可以帮助用户监控当前写缓冲区的水位状况,ChannelOutboundBuffer本身是无界的,如果水位控制不当的话就会造成占用大量的内存,今天准备结合代码来看看这个配置究竟是有什么作用。
ChannelConfig默认的水位配置为低水位32K,高水位64K,如果用户没有配置就会使用默认配置。
即使使用了默认配置,没有控制,则仍然会导致ChannelOutboundBuffer趋于无穷,水位只是提醒你,并不会操作,你不控制还是会爆掉
高水位的时候就会可以通知到业务handler中的WritabilityChanged方法,并且修改buffer的状态,channel调用isWriteable的时候就会返回false,当前channel处于不可写状态。
如果低于该水位就会设置当前的channel为可写,然后触发可读事件。
水位配置可以帮助我们监控缓冲区的使用情况,在写数据的时候需要判断当前channel是否可以继续向缓冲区写数据(isWriteable)。在之前的工作中出现过没有正确判断,而使用的编码器默认使用的又是堆外内存,导致在不断写入缓存的时候堆外内存超过jvm配置最大值。
https://blog.csdn.net/qq_34772568/article/details/106524734
netty中的高低水位机制会在发送缓冲区的数据超过高水位时触发channelWritabilityChanged事件同时将channel的写状态设置为false,但是这个写状态只是程序层面的状态,程序还是可以继续写入数据。这与我们在第一点判断的一致
当我们在netty中使用write方法发送数据时,这个数据其实是写到了一个缓冲区中,并未直接发送给接收方,netty使用ChannelOutboundBuffer封装出站消息的发送,所有的消息都会存储在一个链表中,直到缓冲区被flush方法刷新,netty才会将数据真正发送出去。
netty默认设置的高水位为64KB,低水位为32KB.
https://my.oschina.net/u/3959468/blog/3018592 yet
通过以上分析可以看出,在直播高峰期,服务端向上万客户端推送消息时,发生了发送队列积压,引起内存泄漏,最终导致服务端频繁 GC,无法正常处理业务。
服务端在进行消息发送的时候做保护,具体策略如下:
-
根据可接入的最大用户数做客户端并发接入数流控,需要根据内存、CPU 处理能力,以及性能测试结果做综合评估。
-
设置消息发送的高低水位,针对消息的平均大小、客户端并发接入数、JVM 内存大小进行计算,得出一个合理的高水位取值。服务端在推送消息时,对 Channel 的状态进行判断,如果达到高水位之后,Channel 的状态会被 Netty 置为不可写,此时服务端不要继续发送消息,防止发送队列积压。
服务端基于上述策略优化了代码,内存泄漏问题得到解决。
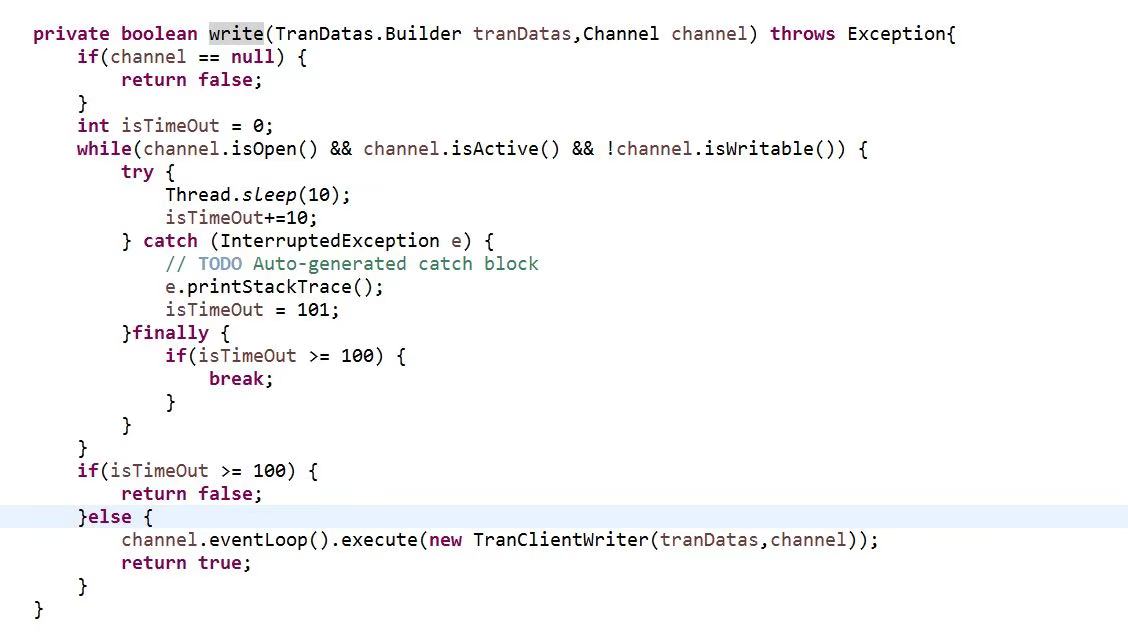
当发送队列待发送的字节数组达到高水位上限时,对应的 Channel 就变为不可写状态。由于高水位并不影响业务线程调用 write 方法并把消息加入到待发送队列中,因此,必须要在消息发送时对 Channel 的状态进行判断:当到达高水位时,Channel 的状态被设置为不可写,通过对 Channel 的可写状态进行判断来决定是否发送消息。
https://www.jianshu.com/p/6c4a7cbbe2b5
在有些场景下,由于各种原因,会导致客户端消息发送积压,进而导致OOM。
- 1、当netty服务端并发压力过大,超过了服务端的处理能力时,channel中的消息服务端不能及时消费,这时channel堵塞,客户端消息就会堆积在发送队列中
- 2、网络瓶颈,当客户端发送速度超过网络链路处理能力,会导致客户端发送队列积压
- 3、当对端读取速度小于己方发送速度,导致自身TCP发送缓冲区满,频繁发生write 0字节时,待发送消息会在netty发送队列中排队
这三种情况下,如果客户端没有流控保护,这时候就很容易发生内存泄露。
io.netty.channel.AbstractChannelHandlerContext#writeAndFlush (java.lang.Object, io.netty.channel.ChannelPromise),如果发送方为业务线程,则将发送操作封装成WriteTask(继承Runnable),放到Netty的NioEventLoop中执行,当NioEventLoop无法完成如此多的消息的发送的时候,发送任务队列积压,进而导致内存泄漏。
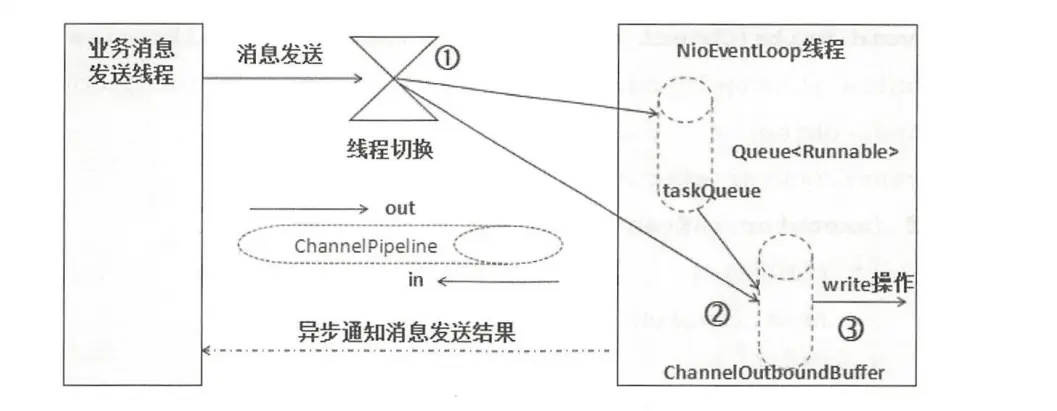
经过一些系统处理操作,最终会调用io.netty.channel.ChannelOutboundBuffer#addMessage方法,将发送消息加入发送队列(链表)。
https://www.jianshu.com/p/890525ff73cb great done
在Netty3的时候,upstream是在IO线程里执行的,而downstream是在业务线程里执行的。比如netty从网络读取一个包传递给你的handler的时候,你的handler部分的代码是执行在IO线程里,而你的业务线程调用write向网络写出一些东西的时候,你的handler是执行在业务线程里。而Netty 4修改了这一模型。在Netty4里inbound(upstream)和outbound(downstream)都是执行在EventLoop(IO线程)里。也就是你如果在业务线程里通过channel.write向网络写出一些东西的时候,在某一点,netty4会往这个channel的EventLoop里提交一个写出的任务。那也就是业务线程和IO线程是异步执行的。
因为序列化和业务线程异步执行,那么在write执行后并不表示user对象已经序列化了,如果这个时候修改了user对象那么传递到peer的对象可能就不再是你期望的那个user了。
我们就决定不再在handler里做序列化了,而是直接在业务线程里做。但是为了减少内存的拷贝,我们就期望在序列化的时候直接将字节流序列化到DirectByteBuf里,这样通过socket写出的时候就不进行拷贝了
DirectByteBuf的分配成本比HeapByteBuf的成本要高,为此Netty4借鉴jemalloc的思路实现了一个PooledByteBufAllocator。顾名思义,就是将DirectByteBuf池化起来,回收的时候不真正回收,分配的时候从池里取一个空闲的。
PooledByteBufAllocator为了减少锁竞争,池是通过threadlocal来实现的。也就是分配的时候会从本线程(这里就是业务线程)的threadlocal里取。而channel.writeAndFlush调用后,在将buffer写到socket后,这个buffer将被回收到池里。回收的时候也是通过thread local找到对应的池,回收掉。这样就有一个问题,分配的时候是在业务线程,也就是说从业务线程的threadlocal对应的池里分配的,而回收的时候是在IO线程。这两个是不同的线程。池的作用完全丧失了,一个线程不断地去分配,不断地转移到另外一个池。
buffer默认大小是256个字节,当你将对象往这个buffer里序列化的时候,如果超过了256个字节ByteBuf就会自动扩展,而对于PooledByteBuf来说,自动扩展是会去池里取一个,然后将旧的回收掉。而这一切都是在业务线程里进行的。意味着你使用专用的线程来做分配和回收功亏一篑。
是关于Netty里的ChannelOutboundBuffer这个东西的。这个buffer是用在netty向channelwrite数据的时候,有个buffer缓冲,这样可以提高网络的吞吐量(每个channel有一个这样的buffer)。初始大小是32(32个元素,不是指字节),但是如果超过32就会翻倍,一直增长。大部分时候是没有什么问题的,但是在碰到对端非常慢(对端慢指的是对端处理TCP包的速度变慢,比如对端负载特别高的时候就有可能是这个情况)的时候就有问题了,这个时候如果还是不断地写数据,这个buffer就会不断地增长,最后就有可能出问题了(我们的情况是开始吃swap,最后进程被linux killer干掉了)。为什么说这个地方是坑呢,因为大部分时候我们往一个channel写数据会判断channel是否active,但是往往忽略了这种慢的情况。那这个问题怎么解决呢?其实ChannelOutboundBuffer虽然无界,但是可以给它配置一个高水位线和低水位线,当buffer的大小超过高水位线的时候对应channel的isWritable就会变成false,当buffer的大小低于低水位线的时候,isWritable就会变成true。所以应用应该判断isWritable,如果是false就不要再写数据了。高水位线和低水位线是字节数,默认高水位是64K,低水位是32K,我们可以根据我们的应用需要支持多少连接数和系统资源进行合理规划。
2.调用write方法并没有将数据写到Socket缓冲区中,而是写到了一个单向链表的数据结构中,flush才是真正的写出
3.writeAndFlush等价于先将数据写到netty的缓冲区,再将netty缓冲区中的数据写到Socket缓冲区中,写的过程与并发编程类似,用自旋锁保证写成功
4.netty中的缓冲区中的ByteBuf为DirectByteBuf
https://www.cnblogs.com/stateis0/p/9062155.html
Netty 的 write 的操作不会立即写入,而是存储在了 ChannelOutboundBuffer 缓冲区里,这个缓冲区内部是 Entry 节点组成的链表结构,通过 addMessage 方法添加进链表,通过 addFlush 方法表示可以开始写入了,最后通过 SocketChannel 的 flush0 方法真正的写入到 JDK 的 Socket 中。同时需要注意如果 TCP 缓冲区到达一个水位线了,不能写入 TCP 缓冲区了,就需要晚点写入,这里的方法判断是 isFlushPending()。
其中,有一个需要注意的点就是,如果对方接收数据较慢,可能导致缓冲区存在大量的数据无法释放,导致OOM,Netty 通过一个 isWritable 开关尝试解决此问题,但用户需要重写 ChannelWritabilityChanged 方法,因为一旦超过默认的高水位阈值,Netty 就会调用 ChannelWritabilityChanged 方法,执行完毕后,继续进行 flush。用户可以在该方法中尝试慢一点的操作。等到缓冲区的数据小于低水位的值时,开关就关闭了,就不会调用 ChannelWritabilityChanged 方法。因此,合理设置这两个数值也挺重要的。
https://www.zhihu.com/question/35487154
https://blog.csdn.net/u010739551/article/details/82887411 great done
有了线索就赶紧去查Netty源码,发现的确像调用channel.write()操作不是在当前线程上执行。Netty内部统一使用executor.inEventLoop()判断当前线程是否是EventLoopGroup的线程,否则会包装好Task交给内部线程池执行
业务线程池原来是把双刃剑。虽然将任务交给业务线程池异步执行降低了Netty的I/O线程的占用时间、减轻了压力,但同时业务线程池增加了线程上下文切换的次数。通过上述这些优化手段,终于将压测时的CS从每秒30w+降到了8w左右,效果还是挺明显的!
系统调用一般会涉及到从User Space到Kernel Space的模态转换(Mode Transition或Mode Switch)。这种转换也是有一定开销的。如:从实践模拟角度再议bio nio【重点】 我们写的Java程序其本质在轮询每个Socket的时候也需要去调用系统函数,那么轮询一次调用一次,会造成不必要的上下文切换开销
Netty涉及的系统调用最多的就是网络通信操作了,所以为了降低系统调用的频度,最直接的方法就是缓冲输出内容,达到一定的数据大小、写入次数或时间间隔时才flush缓冲区。
对于缓冲区大小不足,写入速度过快等问题,Netty提供了writeBufferLowWaterMark和writeBufferHighWaterMark选项,当缓冲区达到一定大小时则不能写入,避免被撑爆。感觉跟Netty提供的Traffic Shaping流量整形功能有点像呢。具体还未深入研究,感兴趣的同学可以自行学习一下。
因为网络粘包拆包等因素,Decoder不可避免的要保存一些解析过程的中间状态。netty(十九)ChannelInitializer 使用公共handler(@Shareable)实践及逻辑解答【重点】
- 线程数控制:高并发下如果线程较多时,Context Switch会非常明显,超过CPU核心数的线程不会带来任何好处。不是特别耗时的操作的话,业务线程池也是有害无益的。Netty 5为我们提供了指定底层线程池的机会,这样能更好的控制整个中间件的线程数和调度策略。
- 非阻塞I/O操作:要想线程少还多做事,避免阻塞是一定要做的。
- 减少系统调用:虽然Mode Switch比Context Switch的开销要小得多,但我们还是要尽量减少频繁的syscall。从实践模拟角度再议bio nio【重点】 模拟的代码在用户态和内核态频繁切换
- 数据零拷贝:从内核空间的Direct Buffer拷贝到用户空间,每次透传都拷贝的话累积起来是个不小的开销。15阶段结论整理
- 共享状态保护:中间件内部的并发处理也是决定性能的关键。
不是,是netty自己搞了一段内存;这段东西的作用是降低用户空间-内核的切换和拷贝频率,socket.write就涉及到一次切换


{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决