线程池的取值(二)设计吞吐量【重点】


(2)补充,对于任务型,比如推送,也会有一个推送延迟的要求,可用n1来压测取得其吞吐量和响应时间,对比是否在要求以内

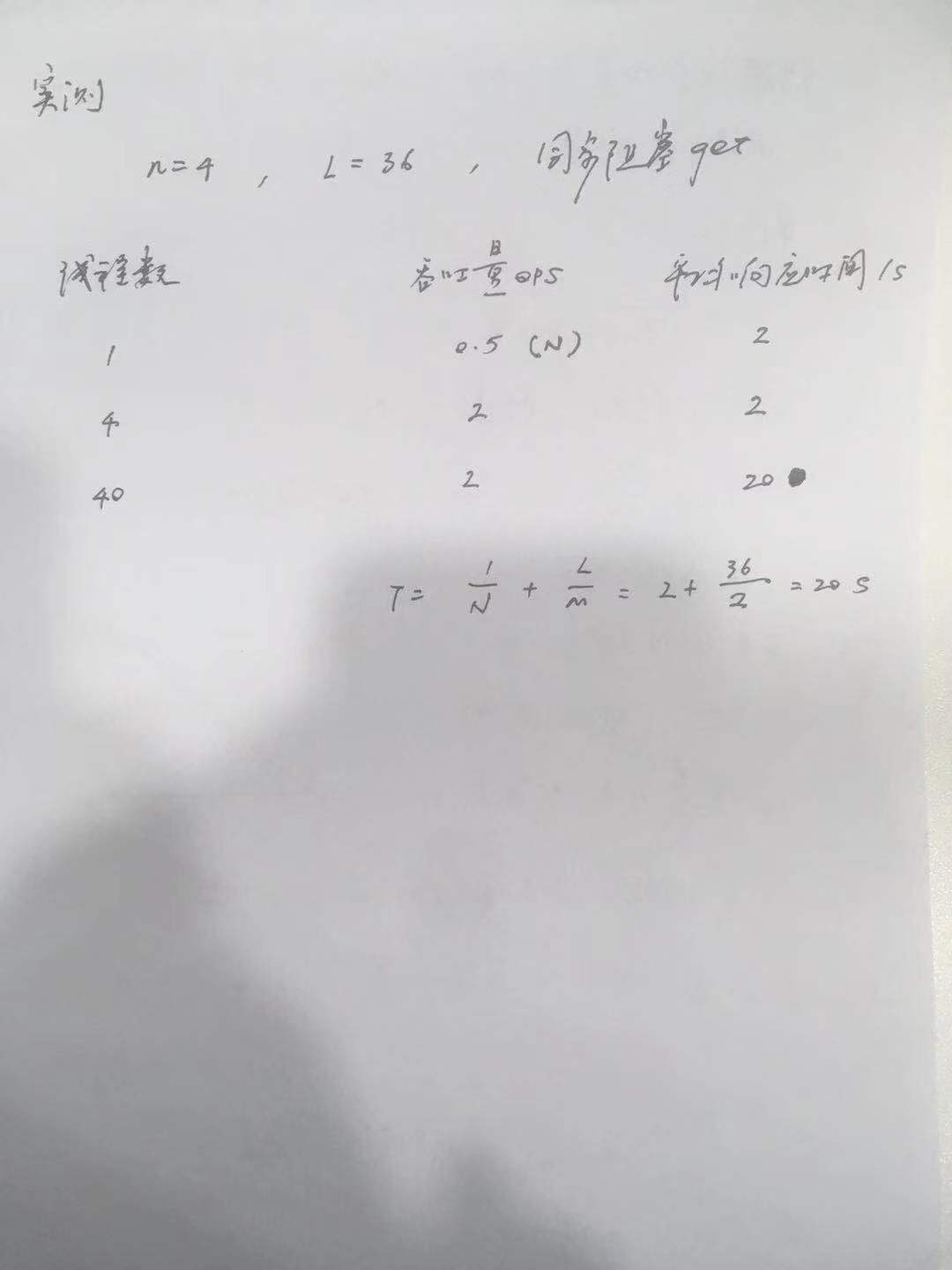
实测数据:
线程数 吞吐量 响应时间
1 0.5 2
2 1 2
3 1.5 2
4 2 2
5 2 2.5
6 2 3
40 2 20
测试代码:
import java.util.concurrent.*;
/**
* https://www.cnblogs.com/silyvin/p/11806859.html
* https://www.cnblogs.com/silyvin/p/11875907.html
* Created by joyce on 2019/11/6.
*/
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.SECONDS)
@Threads(40)
@State(Scope.Thread)
public class MyThread {
private static final ThreadPoolExecutor MQ_POOL = new ThreadPoolExecutor(
4, 4, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(),
new DefaultThreadFactory("mq-", true));
public static class action implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int a = 0;
Thread.sleep(2000);
System.out.println(a);
return a;
}
}
@Benchmark
public static void testS() {
try {
Future<Integer> i = MQ_POOL.submit(new action());
i.get();
} catch (RejectedExecutionException e) {
System.out.println("放弃");
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String [] f) throws RunnerException {
// jhm压力测试
Options opt = new OptionsBuilder().include(MyThread.class.getSimpleName()).forks(1).warmupIterations(0)
.measurementIterations(1).build();
new Runner(opt).run();
// 自己的压力测试
MyYali.start(40);
}
private static class MyYali implements Runnable {
public static void start(int threadCount) {
for(int i=0; i<threadCount; ++i) {
new Thread(new MyYali()).start();
}
}
// 这个地方如果用1不会出错
private int count = 2;
@Override
public void run() {
for(int i=0; i<count; ++i) {
testS();
}
}
}
}
这里使用LinkedBlockingQueue无界队列来接收等待队列,之后将会详解
引用:
https://blog.csdn.net/sinat_34976604/article/details/88125707
单线程场景:
假设我们的服务端只有一个线程,那么所有的请求都是串行执行,我们可以很简单的算出系统的QPS,也就是:QPS = 1000ms/RT。假设一个RT过程中CPU计算的时间为49ms,CPU Wait Time 为200ms,那么QPS就为1000/(49+200) = 4.01。
多线程场景
我们接下来把服务端的线程数提升到2,那么整个系统的QPS则为:2 *(1000/(49+200))=8.02。可见QPS随着线程的增加而线性增长,那QPS上不去就加线程呗,听起来很有道理,公式也说得通,但是往往现实并非如此,后面会聊这个问题。
最佳线程数?
从上面单线程场景来看,CPU Wait time为200ms,你可以理解为CPU这段时间什么都没做,是空闲的,显然我们没把CPU利用起来,这时候我们需要启多个线程去响应请求,把这部分利用起来,那么启动多少个线程呢?我们可以估算一下 空闲时间200ms,我们要把这部分时间转换为CPU Time,那么就是(200+49)/49 = 5.08个,不考虑上下文切换的话,约等于5个线程。
。。。。。。。。。
通过上面一些例子,我们发现当线程数增加的时候,线程的上下文切换会增加,GC Time会增加。这也就导致CPU time 增加,QPS减小,RT也会随着增大。这显然不是我们希望的,我们希望的是在核数一定的情况下找到某个点,使系统的QPS最大,RT相对较小。所以我们需要不断的压测,调整线程池,找到这个QPS的峰值,并且使CPU的利用率达到100%,这样才是系统的最大QPS和最佳线程数。
https://elasticsearch.cn/question/4350
顺着楼上大牛的思路,现有业务场景下,评估一下你的线程池模型是否合理
举个例子:
一个节点假设配置search线程池为16,队列长度为1000, 一个线程处理一个搜索请求处理耗时是20ms,那么一个线程一秒可以处理50个请求。 那么理论上16个线程一秒可以处理900个请求,1000+16的线程队列大小是能够容纳qps为900的业务的(当然这是理论上,没有考虑的线程上下文切换,网络原因,内存GC导致stw等等,所以实际值肯定比这个低)。
与“n决定吞吐量,L决定响应时间”一致
https://blog.csdn.net/qq_34417408/article/details/78895573
先由之前遇到的一个测试题说起,假设要求一个系统的TPS(Transaction Per Second或者Task Per Second)至少为20,然后假设每个Transaction由一个线程完成,继续假设平均每个线程处理一个Transaction的时间为4s。那么问题转化为:
如何设计线程池大小,使得可以在1s内处理完20个Transaction?
计算过程很简单,每个线程的处理能力为0.25TPS,那么要达到20TPS,显然需要20/0.25=80个线程。(理论上)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号