GPT2代码详解
这里主要解读transformers中关于GPT2的代码,主要涉及:GPT2Attention,GPT2Block,GPT2MLP以及GPT2Model
# transformers安装
conda install transformers
pip install transformers
首先创建GPT2模型
from transformers import GPT2LMHeadModel
# 该路径为本地路径
name_or_path = 'pre_trained/gpt-small'
# 会自动加载name_or_path中的config.json, pytorch_model.bin
lm_gpt2 = GPT2LMHeadModel.from_pretrained(name_or_path)
假设输入的张量input_ids.shape=(bs, len),记作x
下面介绍x输入lm_gpt2后所做的处理。
bs = 16
_len = 40
x = torch.randn(size=(bs, _len))
outputs = lm_gpt2(input_ids=x,
token_type_ids=None, # 如果有的话就加上
position_ids=None, # 如果有的话就加上
attention_mask=None # 如果有的话就加上
)
为方便介绍,会省略源码中的部分代码
1 GPT2LMHeadModel
1.1 forward方法介绍
lm_gpt2(input_ids=x)实际上执行的是lm_gpt2的forward方法,这里主要介绍该方法。
| forward参数 | 说明 |
|---|---|
| input_ids | 输入的张量,形状可以是(bs, len) |
| past_key_values | 见下方 |
| attention_mask | 略 |
| token_type_ids | 略 |
| position_ids | 可以不设置,GPT2Model检测到position_ids为None会自己创建 |
| head_mask | 暂时没用过 |
| inputs_embeds | 输入的张量,形状是(bs, len, hidden_size),注意:inputs_embeds和input_ids只能选择一个输入 |
| encoder_hidden_states | 用于交叉注意力,需要设置config.json,添加add_cross_attention: true |
| encoder_attention_mask | 用于交叉注意力,需要设置config.json,添加add_cross_attention: true |
| labels | 可以与input_ids,程序自行shift right,做CrossEntropyLoss,得到lm_loss |
| use_cache | 如果设置为False,则不会得到past_key_values |
| output_attentions | 默认False,是否需要输出GPT2Model处理过程中每个block的attentions |
| output_hidden_states | 默认False,是否需要输出GPT2Model中每个GPT2Block的输出hidden states |
| return_dict | 默认是True,会返回一个结果对象,可以通过.属性值方式获取数据;如果设置为False,则会将需要输出的结果转为元组 |
past_key_values
将x输入gpt2中,势必会经过Block中的多头注意力模块,谈及注意力,会涉及query,key,value。当use_cache=True,会缓存所有Block中所有Attention模块用到的key,value
1.2 源码(缩减)
class GPT2LMHeadModel(GPT2PreTrainedModel):
_keys_to_ignore_on_load_missing = [r"attn.masked_bias", r"attn.bias", r"lm_head.weight"]
def __init__(self, config):
super().__init__(config)
# 后面介绍GPT2Model
self.transformer = GPT2Model(config)
# lm_head的参数,与GPT2Model中的wte参数共享
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
def forward(self, 参数见上表):
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.transformer(参数见上表)
# 这里得到的是GPT2Model最后一个Block的输出
hidden_states = transformer_outputs[0]
# Set device for model parallelism
if self.model_parallel:
torch.cuda.set_device(self.transformer.first_device)
hidden_states = hidden_states.to(self.lm_head.weight.device)
# hidden_states.shape = (bs, len, hs)
# lm_logits.shape = (bs, len, vocab_size)
lm_logits = self.lm_head(hidden_states)
loss = None
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
if not return_dict: # 可以看到,如果return_dict为False,则会将结果处理成tuple
output = (lm_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
# 通常,我们会需要GPT2最后一层输出的hidden states
# 那么获取的时候需要CausalLMOutputWithCrossAttentions.hidden_states[-1]
return CausalLMOutputWithCrossAttentions(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
cross_attentions=transformer_outputs.cross_attentions,
)
2 GPT2Model
可以知道,GPT2LMHead就是接收参数,并传给GPT2Model,这里介绍GPT2Model所作的事情。
2.1 forward方法介绍
见[源码(缩减)](#2.2 源码(缩减))
2.2 源码(缩减)
class GPT2Model(GPT2PreTrainedModel):
_keys_to_ignore_on_load_missing = ["attn.masked_bias"]
def __init__(self, config):
super().__init__(config)
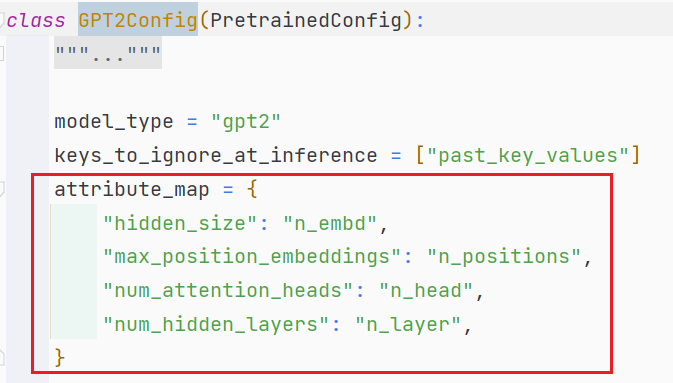
# 这里的hidden_size 其实就是config.json中的n_embd
# 在GPT2Config类中有相关记载,如上图
self.embed_dim = config.hidden_size
self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
# max_position_embeddings就是config.json中的n_positions
self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim)
self.drop = nn.Dropout(config.embd_pdrop)
# Block块堆叠。gpt2-small堆叠12块,distilgpt2堆叠6块
self.h = nn.ModuleList([GPT2Block(config, layer_idx=i) for i in range(config.num_hidden_layers)])
self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
# Initialize weights and apply final processing
self.post_init()
def forward(self, 参数见上表):
"""
做一些参数的检查与处理:
1. input_ids 和 inputs_embeds 只能有一个。因为input_ids后面会转换为inputs_embeds,
都传的话会产生冲突
2. 如果没有设置position_ids,则自动创建
3. token_type_ids,进行形状上的处理
4. 处理 attention_mask。输入attention_mask.shape = (bs, len),其中非PAD为1.0表示不需要掩盖,
PAD的位置是0.0表示需要掩盖。形状会处理成(bs, 1, 1, len),其中的值会被处理成0.0 和 torch.float
的最小值。前者表示,不需要掩盖,后者表示需要掩盖
5. hidden_states = inputs_embeds + position_ids + attenion_mask + token_type_ids
(后面两项根据实际情况可有可无)
"""
hidden_states = self.drop(hidden_states)
output_shape = input_shape + (hidden_states.size(-1),)
# 下面四个tuple都是用来保存中间结果的
presents = () if use_cache else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
all_hidden_states = () if output_hidden_states else None
# 原始的hidden states 进入堆叠的块
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
outputs = block(
hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask[i],
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
# 当前block的输出结果
hidden_states = outputs[0]
if use_cache is True:
# 保存当前block中的Attention模块所使用的key,value
# outputs[1] = (key, value)
presents = presents + (outputs[1],)
if output_attentions:
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)
hidden_states = self.ln_f(hidden_states)
hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
# all_hidden_states, 通过代码可知一共保存了1 + layer_num个hidden states
# 没经过任何block的hidden states(一开始的hidden states也被保存)
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [hidden_states, presents, all_hidden_states, all_self_attentions, all_cross_attentions]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
3 GPT2Block(重点)
3.1 GPT2Attention
下面的代码去掉了
Cross-Attention,pruned_heads,以及Layer-wise attention scaling, reordering, and upcasting
所谓self-Attention运行是这样的:
- 输入
x,x.shape=(bs, len, hs),hs即hidden size - 经过
Conv1D变为x.shape=(bs, len, 3*hs) - 将
x拆分得到query, key, value,它们的形状都是(bs, len, hs) - query, key, value都通过
_split_heads形状变为(bs, head_num, len, head_dim),这里的head_dim = hs // head_num。这里要求必须能够整除 - query, key, value输入
_attn进行矩阵运算- query和key相乘得到注意力分数
attn_weights.shape=(bs, head_num, len, len) - 缩放,\(\text{attn_weights}/\sqrt{\text{hidden size}}\)
- bias mask,即
if not self.is_cross_attention那一部分 attn_weights + attention_mask(如果有的话) + head_mask(如果有的话)- drop out
attn_weights * value,得到的结果attn_output形状是(bs, head_num, len, head_dim)
- query和key相乘得到注意力分数
- 合并头
_merge_heads,attn_output的形状变为(bs, len, hs) - Conv1D
- Dropout
- 结束
class GPT2Attention(nn.Module):
def __init__(self, config, is_cross_attention=False, layer_idx=None):
super().__init__()
max_positions = config.max_position_embeddings
self.register_buffer(
"bias",
torch.tril(torch.ones((max_positions, max_positions), dtype=torch.uint8)).view(
1, 1, max_positions, max_positions
),
)
self.register_buffer("masked_bias", torch.tensor(-1e4))
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
self.split_size = self.embed_dim
# 同Attention is all you need论文中所提,是否需要将结果除sqrt(n_embd)
self.scale_attn_weights = config.scale_attn_weights
self.c_attn = Conv1D(3 * self.embed_dim, self.embed_dim)
self.c_proj = Conv1D(self.embed_dim, self.embed_dim)
self.attn_dropout = nn.Dropout(config.attn_pdrop)
self.resid_dropout = nn.Dropout(config.resid_pdrop)
def _attn(self, query, key, value, attention_mask=None, head_mask=None):
attn_weights = torch.matmul(query, key.transpose(-1, -2))
if self.scale_attn_weights:
# 缩放,除sqrt(n_embd)
attn_weights = attn_weights / torch.tensor(
value.size(-1) ** 0.5, dtype=attn_weights.dtype, device=attn_weights.device
)
if not self.is_cross_attention:
# len; len
query_length, key_length = query.size(-2), key.size(-2)
# (1, 1, len, len) bool类型
causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length].to(torch.bool)
mask_value = torch.finfo(attn_weights.dtype).min
mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
attn_weights = torch.where(causal_mask, attn_weights, mask_value)
if attention_mask is not None:
# Apply the attention mask
attn_weights = attn_weights + attention_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
# Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op otherwise
attn_weights = attn_weights.type(value.dtype)
attn_weights = self.attn_dropout(attn_weights)
# Mask heads if we want to
if head_mask is not None:
attn_weights = attn_weights * head_mask
attn_output = torch.matmul(attn_weights, value)
return attn_output, attn_weights
def forward(self, hidden_states, layer_past, attention_mask, head_mask, encoder_hidden_states,
encoder_attention_mask, use_cache, output_attentions):
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
# (bs, head_num, len, head_dim)
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
# (bs, head_num, len, head_dim); (bs, head_num, len, len)
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
# (bs, len, hs)
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
attn_output = self.c_proj(attn_output)
attn_output = self.resid_dropout(attn_output)
outputs = (attn_output, present)
if output_attentions:
outputs += (attn_weights,)
return outputs # a, present, (attentions)
3.2 GPT2MLP
这个就没有什么好讲的了。
class GPT2MLP(nn.Module):
def __init__(self, intermediate_size, config):
"""
intermediate_size: 如果没有指定中间维度的话,默认是4 * config.n_embd,在GPT2Block的__init__中有写
"""
super().__init__()
embed_dim = config.hidden_size
self.c_fc = Conv1D(intermediate_size, embed_dim)
self.c_proj = Conv1D(embed_dim, intermediate_size)
# ACT2FN是一个dict
# key:激活函数名字,通常是在config.json中进行设置
# value:该激活函数对象
self.act = ACT2FN[config.activation_function]
self.dropout = nn.Dropout(config.resid_pdrop)
def forward(self, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.FloatTensor:
hidden_states = self.c_fc(hidden_states)
hidden_states = self.act(hidden_states)
hidden_states = self.c_proj(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_states
3.3 GPT2Block
每个Block对输入的hidden states处理的流程(不含有Cross-Attention)如图所示:
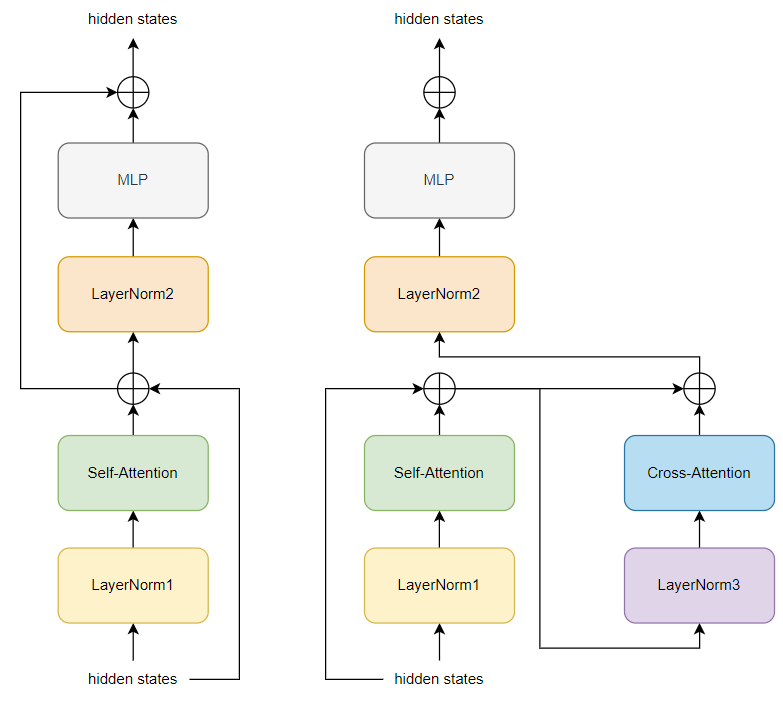
下面的代码中去掉了Cross-Attention的部分
class GPT2Block(nn.Module):
def __init__(self, config, layer_idx=None):
super().__init__()
hidden_size = config.hidden_size
inner_dim = config.n_inner if config.n_inner is not None else 4 * hidden_size
self.ln_1 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
self.attn = GPT2Attention(config, layer_idx=layer_idx)
self.ln_2 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
self.mlp = GPT2MLP(inner_dim, config)
def forward(self, 略):
residual = hidden_states
hidden_states = self.ln_1(hidden_states)
attn_outputs = self.attn(
hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
outputs = attn_outputs[1:]
# residual connection
hidden_states = attn_output + residual
residual = hidden_states
hidden_states = self.ln_2(hidden_states)
feed_forward_hidden_states = self.mlp(hidden_states)
# residual connection
hidden_states = residual + feed_forward_hidden_states
if use_cache:
outputs = (hidden_states,) + outputs
else:
outputs = (hidden_states,) + outputs[1:]
return outputs # hidden_states, present, (attentions, cross_attentions)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号