寒假作业(2/2)
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2020SpringW |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2020SpringW/homework/10281 |
| 这个作业的目标 | 经过完整的设计和开发流程,开发一个疫情统计程序并撰写报告 |
| 作业正文 | https://www.cnblogs.com/sillyby/p/12317238.html |
| 其他参考文献 | ... |
Github仓库地址
作业的主仓库:https://github.com/numb-men/InfectStatistic-main
我的作业仓库:https://github.com/WallofWonder/InfectStatistic-main
个人软件开发流程
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 73 |
| Estimate | 估计这个任务需要多少时间 | 60 | 73 |
| Development | 开发 | 1600 | 2020 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 360 |
| Design Spec | 生成设计文档 | 60 | 105 |
| Design Review | 设计复审 | 60 | 50 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 120 | 180 |
| Design | 具体设计 | 120 | 220 |
| Coding | 具体编码 | 600 | 670 |
| Code Review | 代码复审 | 100 | 80 |
| Test | 测试(自我测试,修改代码,提交修改) | 300 | 355 |
| Reporting | 报告 | 140 | 300 |
| Test Report | 测试报告 | 120 | 230 |
| Size Measurement | 计算工作量 | 20 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 40 |
| 合计 | 1800 | 2393 |
解题思路
大致浏览了作业要求以及和助教交流后,我首先列出了我不太了解的,这次作业会用到的东西,准备进行知识补充:
-
JUnit
单元测试组件,前段时间在maven工程中粗浅地使用过,由于这次脱离了maven,而且对单元测试有一定的要求,所以我在网上找了些资料进行学习。
-
设计模式
说来惭愧,代码敲了快3年,设计模式是真的一点都不了解,作业提到了命令模式、策略模式和责任链模式,就先看看这三个吧。
-
正则表达式
文本操作的利器,可惜我在这方面的学习属实有些困难,符号太多了记不住语法,这次看看用到什么学什么吧。
要求设计的程序是通过命令行进行文件IO操作,大致流程不难设计:
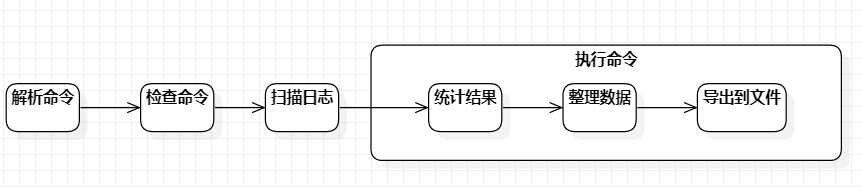
解析命令
我开始打算寻找 java 有没有现成的库能够满足命令行解析的功能,找来找去只有Apache Commons CLI这个第三方库,然而由于作业要求用原生java,所以只好乖乖手打。
作业需求中,关于命令格式的要求如下:
list命令 支持以下命令行参数:
-log指定日志目录的位置,该项必会附带,请直接使用传入的路径,而不是自己设置路径-out指定输出文件路径和文件名,该项必会附带,请直接使用传入的路径,而不是自己设置路径-date指定日期,不设置则默认为所提供日志最新的一天。你需要确保你处理了指定日期之前的所有log文件-type可选择[ip: infection patients 感染患者,sp: suspected patients 疑似患者,cure:治愈 ,dead:死亡患者],使用缩写选择,如-type ip表示只列出感染患者的情况,-type sp cure则会按顺序【sp, cure】列出疑似患者和治愈患者的情况,不指定该项默认会列出所有情况。-province指定列出的省,如-province 福建,则只列出福建,-province 全国 浙江则只会列出全国、浙江注:java InfectStatistic表示执行主类InfectStatistic,list为命令,-date代表该命令附带的参数,-date后边跟着具体的参数值,如
2020-01-22。-type 的多个参数值会用空格分离,每个命令参数都在上方给出了描述,每个命令都会携带一到多个命令参数
简单总结一下命令格式:
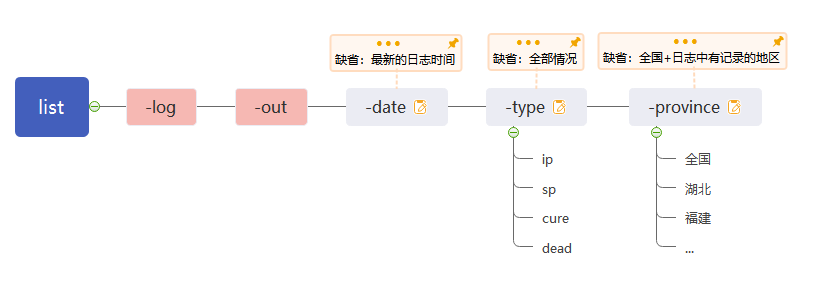
可以发现,有些参数只有一个值,有些参数能有多个值,所以需要将参数分类解析,负责解析的模块解析完成后可以返回一个值或者多个值。
检查命令
命令一定需要符合规范才能被执行。这部分就针对命令格式的要求进行逐个参数的合法性检查,一旦有不符合要求的地方就向入口抛出异常信息终止执行。
对于list命令各个参数的检查标准:
-log必须携带该参数;路径合法。-out必须携带该参数;路径合法;指定文件不存在则创建,存在则覆盖。-date可选参数;若携带则日期格式和数值必须合法。-type可选参数;若携带则所有值必须属于ip、sp、cure、dead。-province可不携带该参数;若携带则所有值必须属于国内省份或者全国。
如果全部参数都符合规范,并不是直接将业务流程推进到”读取日志“的阶段,因为用户输入的命令即使在符合规范的前提下也会五花八门,参数的数量和顺序、值的数量和顺序都有好多种可能,直接使用这些参数会在后期业务逻辑的实现上增加困难,即使成功是实现了需求,代码也可能很臃肿,效率也可能不尽人意。
于是,将用户输入的命令进行标准化是有必要的,所以在检查命令之后,可以将用户命令映射到设计好的命令实体中,在这之后对命令参数的访问就是对这个实体的访问。
以一个例子简单地描述一下映射过程:
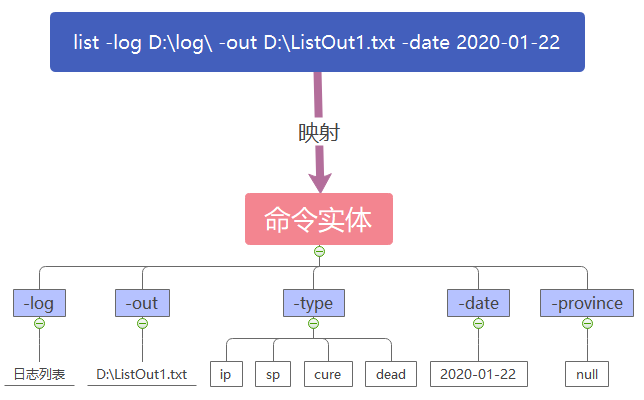
可以看出,通过读取日志路径,将-log的值转为了具体的日志信息,用户没有显式给出-type的值,在实体中也被赋了缺省值,而 -province由于和具体的日志有关所以在这里暂不做缺省赋值。
读取日志
读取日志阶段要根据命令的-log参数定位日志文件,并且根据-date参数选择性地过滤掉日志文件,同时判断日期是否超出范围。
统计结果
这里的重点是对日志的每一条记录进行解析,判断应该执行什么样的操作。
第一个问题是如何将记录和行为匹配,用正则表达式是个好主意。
记录出现的情况有8种:
该日志中出现以下几种情况:
1、<省> 新增 感染患者 n人
2、<省> 新增 疑似患者 n人
3、<省1> 感染患者 流入 <省2> n人
4、<省1> 疑似患者 流入 <省2> n人
5、<省> 死亡 n人
6、<省> 治愈 n人
7、<省> 疑似患者 确诊感染 n人
8、<省> 排除 疑似患者 n人
为了减少工作量,可以将相似情况合并,进而减少到5种:
<省> 新增 <感染患者/疑似患者> n人
<省1> <感染患者/疑似患者> 流入 <省2> n人
<省> <死亡/治愈> n人
<省> 疑似患者 确诊感染 n人
<省> 排除 疑似患者 n人
通过5个正则表达式建立5个入口,其中在情况1、2、3的内部再进行简单的ifelse判断人员种类。
第二个问题是如何将记录定位到与之匹配的行为上。首先想到的是用硕大的控制语句块实现,但是如果情况太多就很不优雅。后来学习了责任链模式后感觉挺有趣的,可以有效地代替if else。
整理数据
在将统计结果导出之前,要根据命令中的-type 和-province进行统计结果的过滤,还要确保统计结果以汉字字典序排列。
设计实现
我以前的实现方法,是像面向过程那样,一条龙服务下来,这样一个程序永远就一条功能线了,能满足。然而助教给出了提示,建议不要把程序写死,要假设程序的需求会发生变化,给程序扩展的空间,这样就不会牵一发而动全身,避免陷入代码维护的噩梦。
程序框架
程序的框架就是从识别命令到开始执行命令的过程,采用命令模式,具体如下:
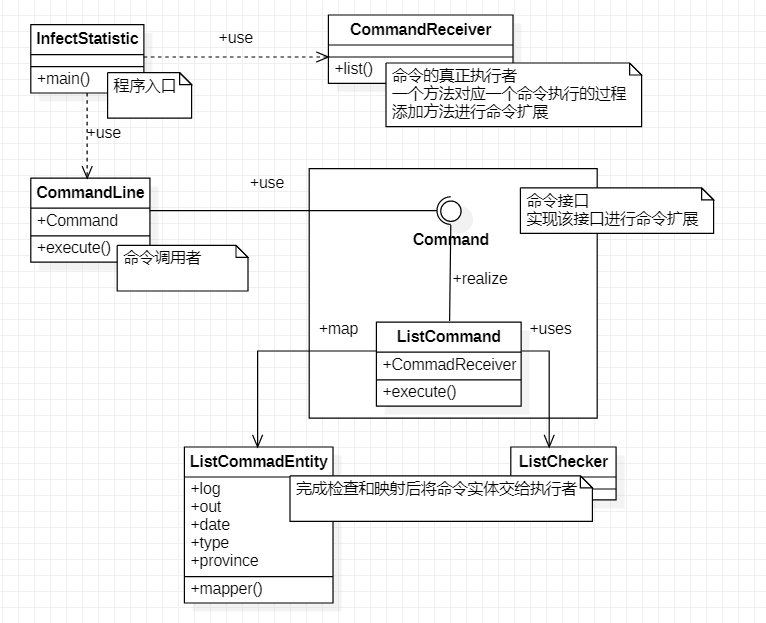
list命令的执行
代码组织,这里只列出关键的类和方法
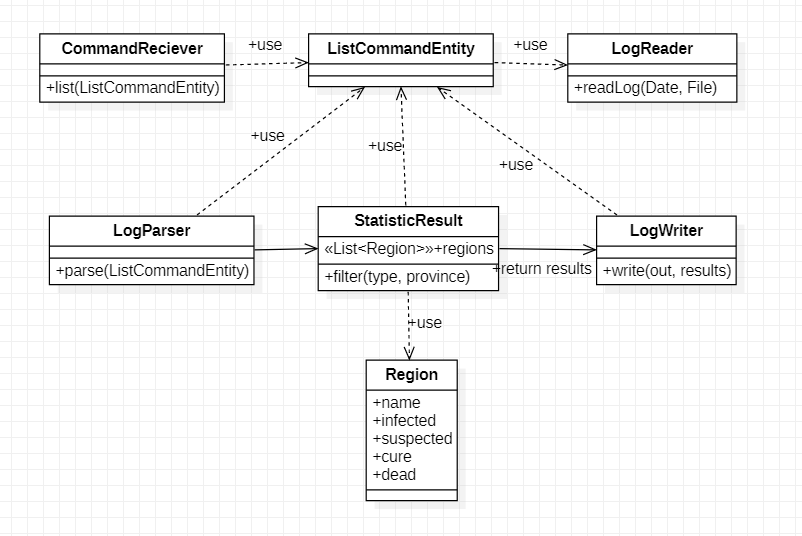
-
list各个的参数检查流程
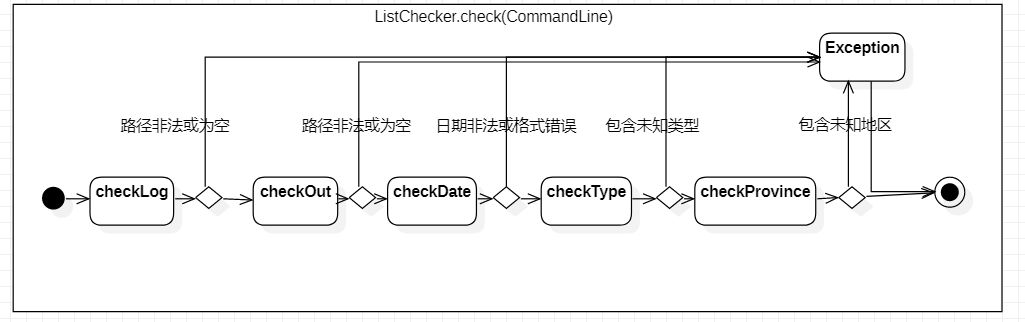
-
日志读取
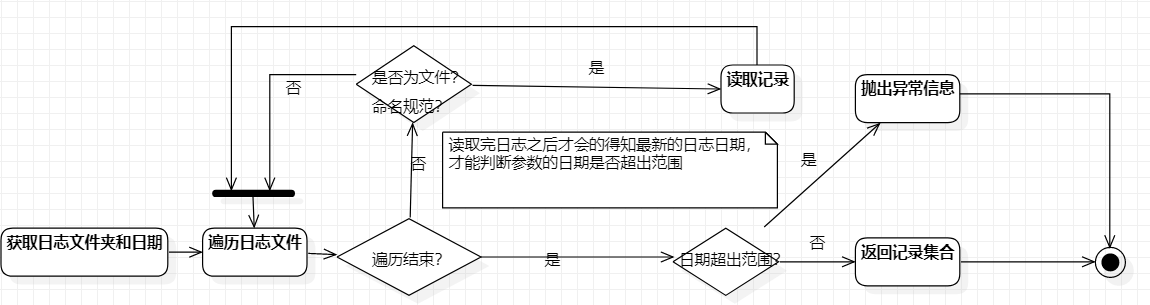
-
日志解析
采用责任链模式
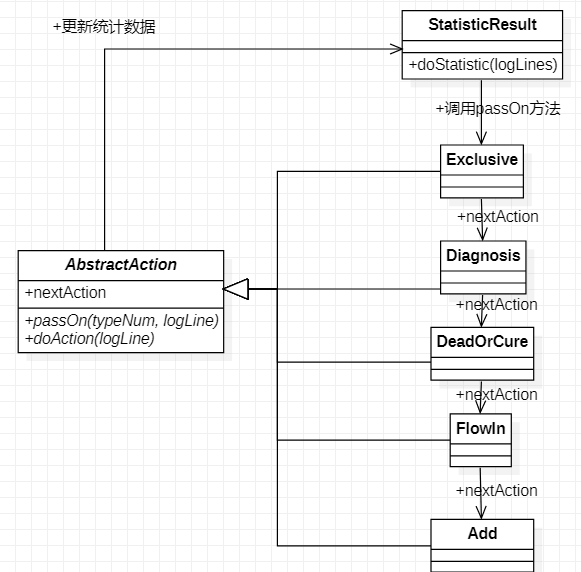
具体流程
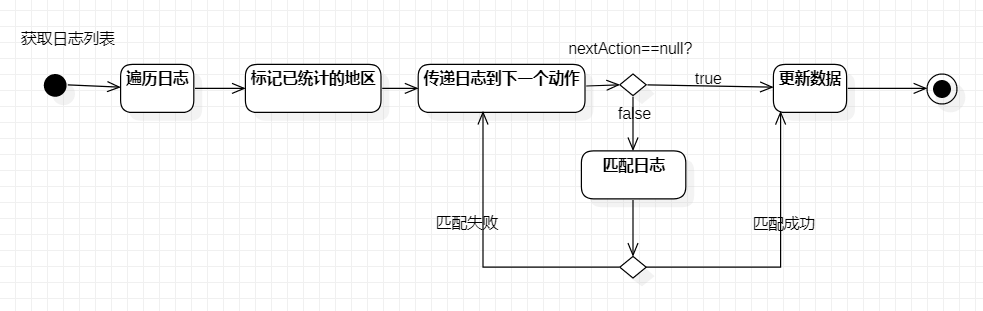
代码说明
框架部分
程序入口,采用命令模式,扩展命令时无需更改此处代码
public static void main(String[] args) {
try {
CommandReceiver receiver = new CommandReceiver();
Command command = new CommandFactory().getCommand(args[0], receiver);
CommandLine commandLine = new CommandLine(args, command);
commandLine.execute();
} catch (Exception e) {
System.out.print("error: " + e.getMessage());
}
}
Command接口,实现此接口以扩展命令:
interface Command {
void execute(CommandLine commandLine) throws Exception;
}
在命令工厂中通过反射生成指定命令的对象,传入“list”字符串即返回ListCommand对象:
/**
* 命令工厂
*/
class CommandFactory {
/**
* 通过反射执行相应方法获取命令对象
*
* @param name 命令名
* @param receiver 命令接受者
* @return 相应方法执行后获取的命令对象
* @throws Exception 不存在相应命令对象
*/
public Command getCommand(String name, CommandReceiver receiver) throws Exception {
try {
return (Command) this.getClass().getMethod(name.toLowerCase(), Class.forName("CommandReceiver"))
.invoke(this, receiver);
} catch (Exception e) {
throw new NoSuchMethodException("未知命令 \'" + name + "\'");
}
}
public Command list(CommandReceiver receiver) {
return new ListCommand(receiver);
}
// 在此处扩展命令...
}
命令参数解析类,可以对命令进行参数的提取,不仅对List命令有效,还可用于日后扩展的任何命令:
/**
* 命令参数解析
*/
class CommandLine {
private String[] args;
private Command command;
CommandLine(String[] args, Command command) {
this.args = args;
this.command = command;
}
/**
* 获取某个参数的一个值
*
* @param arg 选项名称
* @return 参数 {@code arg} 的值,不存在返回 {@code null}
*/
String getValue(String arg) {...}
/**
* 获取某个参数的所有值
*
* @param arg 选项名称
* @return 参数 {@code arg} 的值列表
*/
List<String> getValues(String arg) {...}
/**
* 获取参数的索引
*
* @param arg 选项名称
* @return 该选项的索引值;若不存在返回 -1
*/
private int indexOf(String arg) {...}
/**
* 命令入口
*
* @throws Exception
*/
public void execute() throws Exception {...}
}
实体映射:
public static ListCommandEntity Mapper(CommandLine line) throws Exception {
ListCommandEntity entity = new ListCommandEntity();
// 映射-out参数
entity.out = new File(line.getValue("-out"));
// 映射-date参数,由于之前已经进行参数检查所以这里不做异常处理
entity.date = Util.DATE_FORMAT.parse(line.getValue("-date"));
// 映射-log参数为读取的日志
entity.log = LogReader.readLog(entity.date, new File(line.getValue("-log")));
// 映射-type
List<String> types = line.getValues("-type");
if (types.size() != 0) {
entity.type = types;
}
// 映射-province
entity.province = line.getValues("-province");
return entity;
}
读取日志,由于最新日志的日期只有在读取日志后才能得知,所以日期范围的合法性判断推迟到此处执行:
/**
* 获取指定日期之前的所有log
*
* @param requiredDate 指定日期
* @param logDir 日志文件所在目录
* @return 指定日期之前的所有log列表
*/
public static List<String> readLog(Date requiredDate, File logDir) throws Exception {
File[] fileList = logDir.listFiles();
List<String> logLines = new ArrayList<>();
Date latestDate = Util.DATE_FORMAT.parse("2000-01-01");
for (File file : fileList) {
if (file.isFile()) {
Date logDate;
// 过滤日期不规范的日志文件
try {
logDate = Util.DATE_FORMAT.parse(getLogDate(file));
} catch (Exception e) {
continue;
}
// 过滤指定日期之后的日志
if (requiredDate == null || !logDate.after(requiredDate)) {
// 记录日志最新日期
if (logDate.after(latestDate)) {
latestDate = logDate;
}
try (InputStream fr = new FileInputStream(file.getAbsolutePath());
BufferedReader bf = new BufferedReader(new InputStreamReader(fr, StandardCharsets.UTF_8))) {
String line;
// 按行读取
while ((line = bf.readLine()) != null) {
// 过滤注解
if (!line.substring(0, 2).equals("//")) {
logLines.add(line);
}
}
} catch (IOException e) {
throw new Exception("日志文件读取失败: '" + file.getAbsolutePath() + "'");
}
}
}
}
// 日期范围的合法性判断
if (requiredDate != null && requiredDate.after(latestDate)) {
throw new Exception("日期超出范围");
}
return logLines;
}
日志解析部分
入口:
public static void doStatistic(List<String> logLines) {
// 各个动作的链接
// exclusive -> diagnosis -> deadOrCure -> flowIn -> add
Add add = new Add(null);
FlowIn flowIn = new FlowIn(add);
DeadOrCure deadOrCure = new DeadOrCure(flowIn);
Diagnosis diagnosis = new Diagnosis(deadOrCure);
Exclusive exclusive = new Exclusive(diagnosis);
for (String logLine : logLines) {
// 标记该地区已被检查
setChecked(logLine.substring(0, logLine.indexOf(" ")));
// 从链头开始传递日志
exclusive.passOn(Util.logType(logLine), logLine);
}
}
使用工具类的正则表达式,通过第一次正则匹配,获得唯一的索引,用于指明日志接收者:
// 正则表达式集
static final String[] REGEXS = {
"(\\S+) 新增 (\\S+) (\\d+)人",
"(\\S+) (\\S+) 流入 (\\S+) (\\d+)人",
"(\\S+) (\\S+) (\\d+)人",
"(\\S+) 疑似患者 确诊感染 (\\d+)人",
"(\\S+) 排除 疑似患者 (\\d+)人",
};
/**
* 匹配日志类型
*
* @param logLine 日志的一条记录
* @return 正则表达式的索引;匹配失败返回-1
*/
public static int logType(String logLine) {
for (int i = 0; i < REGEXS.length; i++) {
if (logLine.matches(REGEXS[i])) {
return i;
}
}
return -1;
}
抽象动作类:
abstract class AbstractAction {
// 定义各种类型的唯一索引
public static int ADD_IP = 0;
public static int FLOW_IN = 1;
public static int DEAD_OR_CURE = 2;
public static int DGS = 3;
public static int EXC = 4;
protected int typeNum;
//责任链中的下一个动作
protected AbstractAction nextAction;
public void passOn(int typeNum, String logLine) {
// 命中,执行动作,退出责任链
if (this.typeNum == typeNum) {
doAction(logLine);
return;
}
// 未命中则传递日志到下一个动作类
if (nextAction != null) {
nextAction.passOn(typeNum, logLine);
}
}
/**
* 执行相应的数据更新操作。
*
* @param logLine
*/
abstract protected void doAction(String logLine);
}
每个具体动作类都具有以下形式:
class Action extends AbstractAction {
// 匹配的正则表达式
private String regex = "";
Add(AbstractAction nextAction) {
// 设置唯一索引和下一个动作
}
@Override
protected void doAction(String logLine) {
// 此处第二次使用正则表达式,提取所需字段进行数据更新
}
}
数据整理部分
每个地区的统计结果用Region对象封装
/**
* 地区实体类
* 一个实例代表一个地区的情况
*/
class Region {
// 地区名称
private String name;
// 数据
private int infected;
private int suspected;
private int cure;
private int dead;
// 是否经过统计
private boolean isChecked;
// ...
}
再将Region集合封装成StatisticResult类
class StatisticResult {
static List<Region> regions = new ArrayList<>();
// ...
}
根据-type和-privince过滤数据
public static List<String> filterTypeAndProvince(List<String> type, List<String> province) {
List<String> result = new ArrayList<>();
for (String prv : province) {
if (!prv.equals("全国")) {
result.add(Objects.requireNonNull(get(prv)).toStringWithCertainType(type));
}
}
if (province.contains("全国") || province.size() == 0) {
// 添加全国统计
result.add(statisticAll()).toStringWithCertainType(type));
}
// 若-province为空,列出被统计过的地区情况
if (province.size() == 0) {
for (Region rg : regions) {
if (rg.isChecked()) {
result.add(rg.toStringWithCertainType(type));
}
}
}
// 返回最终的统计结果
return result;
}
文件读写
以utf-8编码方式进行文件的读写:
// 读取日志文件(LogReader.readLog)
try (InputStream fr = new FileInputStream(file.getAbsolutePath());
BufferedReader bf = new BufferedReader(new InputStreamReader(fr, StandardCharsets.UTF_8))) {
String line;
// 按行读取
while ((line = bf.readLine()) != null) {
// 过滤注解
if (!line.substring(0, 2).equals("//")) {
logLines.add(line);
}
}
} catch (IOException e) {
throw new Exception("日志文件读取失败: '" + file.getAbsolutePath() + "'");
}
// 导出统计结果(LogWriter.write)
try (FileOutputStream out = new FileOutputStream(filePath);
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out, StandardCharsets.UTF_8))) {
for (String resultLine : results) {
bw.write(resultLine);
}
bw.write("// 该文档并非真实数据,仅供测试使用\n");
}
测试
覆盖率优化和性能测试,性能优化截图和描述。
单元测试
使用Junit5组件,主要进行了一些主要模块的测试,和主函数测试,打包运行
/**
* 打包测试
*/
@RunWith(Suite.class)
@SuiteClasses({
CommandFactoryTest.class,
ListCheckerTest.class,
CommandLineTest.class,
LogReaderTest.class,
InfectStatisticTest.class
})
public class SuiteTest {
}
测试结果如下:
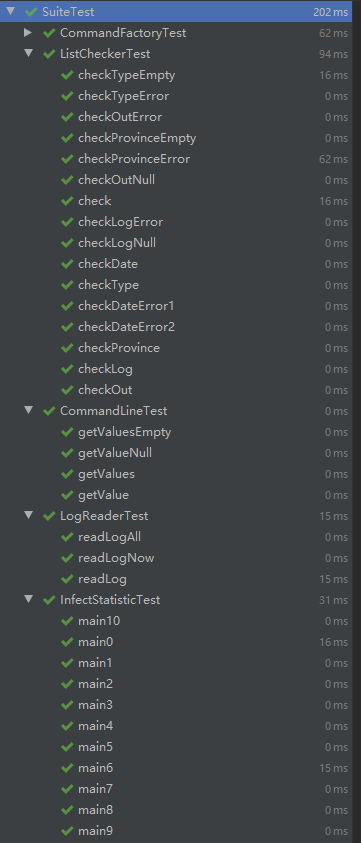
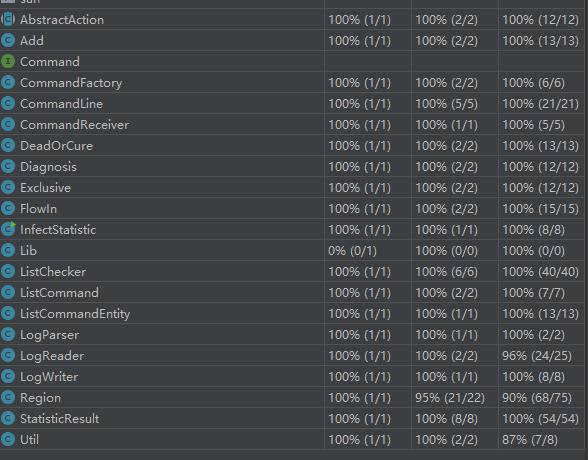
因为Lib类为空,覆盖率为0;
其实前面的分模块测试已经实现了代码覆盖率几乎100%,但《构建之法》提到:
100%的代码覆盖率并不等同于100%的正确性!
所以我增加了完整代码流程的测试并提供了11个测试用例,以确保运行的正确性。
性能测试
使用的测试命令:list -log D:\log\ -out D:\listOut.txt 即获取所有时间段所有有记录的地区的统计数据
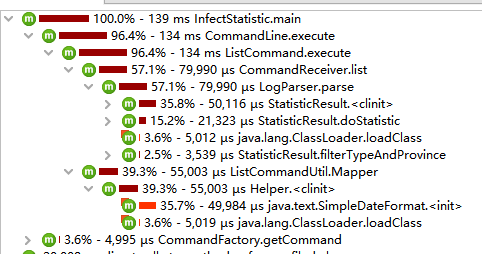
最早版本的性能分析:
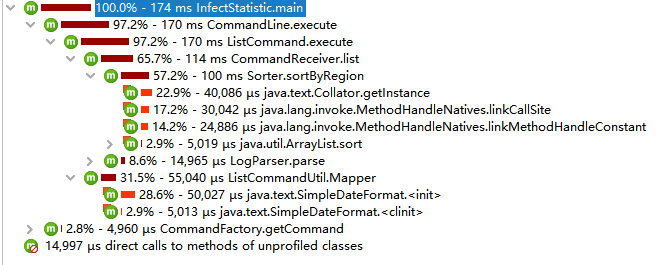
可以看到sortByRegion占用了超过一半的运行时间,这是个排序方法,以地区字典序排列数据。
由于最初的统计结果整理方式为动态添加,也就是当日志出现某地区的时候StatisticResult才会新建一个该地区的Region实例,这样一来统计结果的顺序就无法得到保证,必须手动实现排序:
/**
* 排序器
*/
class Sorter {
public static void sortByRegion(List<String> results) {
Comparator<Object> CHINA_COMPARE = Collator.getInstance(Locale.CHINA);
results.sort((o1, o2) -> {
String rg1 = o1.substring(0, o1.indexOf(' ')).replace("重庆", "冲庆");
String rg2 = o2.substring(0, o2.indexOf(' ')).replace("重庆", "冲庆");
if (rg1.equals("全国") || rg2.equals("全国")) {
return (rg1.equals("全国")) ? -1 : 1;
}
return CHINA_COMPARE.compare(rg1, rg2);
});
}
}
第一次优化
对于排序算法,主要耗时都在Collator.getInstance(Locale.CHINA),占据了排序算法将近一半的时间,由代码逻辑不难发现,每次进行比较时程序都会调用getInstance创建一个新的Comparator,这里我选择将CHINA_COMPARE独立出来,作为工具类的静态成员,这样整个程序的生命周期就只需创建一个实例。
同理对相对耗时的SimpleDateFormat也进行相同处理。
/**
* 工具类
*/
class Tools {
static final SimpleDateFormat DATE_FORMAT = new SimpleDateFormat("yyyy-MM-dd");
static final Comparator<Object> CHINA_COMPARE = Collator.getInstance(Locale.CHINA);
static {
DATE_FORMAT.setLenient(false);
}
}
修改的时候,我发现了一些业务逻辑上的不足(排序方法错误地嵌套在了日志解析方法中,相比于排序对性能影响微乎其微)进行了修复,所以第二次分析树的结构稍有不同,性能分析结果如下:
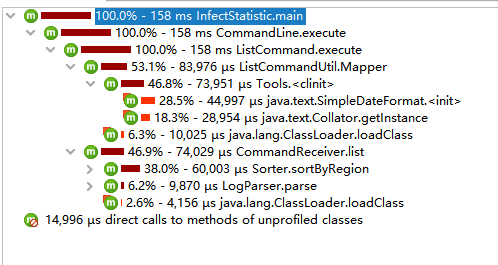
结果排序的耗时占比已经降至38%,而SimpleDateFormat的耗时没有得到明显缩短,总体测试用时有所减少。
(ps:SimpleDateFormat一般是不建议单例使用的,因为它是线程不安全的,但本程序目前未涉及到线程安全问题,所以先这样写,计划是用LocalDateTime代替旧的Date,这样可以使用DateTimeFormatter从而避免使用SimpleDateFormat)
第二次优化
回顾一下逻辑,用户输入的地区范围限定在了“全国”以及31个省,这样就为省去排序提供了可能。
初始化好地区的有序列表,在启动程序的时候就将所有可能的Region对象按序加入StatisticResult中,这样做有以下两个优点:
- 省去了排序和动态添加的开销,读取的时候按命令选择性读取即可;
- 因为列表一开始就是有序的,可以用二分查询指定的地区,替换之前的顺序查找,更加高效。
同时也有相应的代价:
- 由于列表中总是存在所有地区的对象实例,所以读取日志的时候,需要额外的操作用来记录有哪些地区是有疫情记录的;
- 牺牲了空间换取了时间。
对于StatisticResult的修改:
class StatisticResult {
// 地区的有序列表
private static final String[] REGIONS_LIST = new String[]{
"全国", "安徽", "北京", "重庆", "福建", "甘肃", "广东", "广西", "贵州", "海南", "河北", "河南", "黑龙江", "湖北",
"湖南", "吉林", "江苏", "江西", "辽宁", "内蒙古", "宁夏", "青海", "山东", "山西", "陕西", "上海", "四川", "天津",
"西藏", "新疆", "云南", "浙江"
};
static List<Region> regions = new ArrayList<>();
/**
* 按地区名二分查找地区
* 如果当前集合{@code regions}中不存在此地区返回null
*
* @param name
* @return
*/
public static Region get(String name) {
int begin = 0, end = regions.size() - 1;
int mid;
Region temp = new Region(name);
while (begin <= end) {
mid = (begin + end) >> 1;
Region cur = regions.get(mid);
if (name.equals(cur.getName())) {
return regions.get(mid);
}
if (cur.compareTo(temp) < 0) {
begin = mid;
}
if (cur.compareTo(temp) > 0) {
end = mid;
}
}
return null;
}
对于Region的修改,实现Comparable接口以满足二分查找的需要:
/**
* 地区实体类
* 一个实例代表一个地区的情况
*/
class Region implements Comparable<Region> {
static final Comparator<Object> CHINA_COMPARE = Collator.getInstance(Locale.CHINA);
/**
* 实现地区比较
* <p>
* 基于CHINA_COMPARE,”全国“优先,并解决”重庆“多音字的问题
*
* @param o
* @return
*/
@Override
public int compareTo(Region o) {
// 解决”重庆“多音字的问题
String rg1 = this.getName().replace("重庆", "冲庆");
String rg2 = o.getName().replace("重庆", "冲庆");
// ”全国“优先
if (rg1.equals("全国") || rg2.equals("全国")) {
return (rg1.equals("全国")) ? -1 : 1;
}
return CHINA_COMPARE.compare(rg1, rg2);
}
}
性能分析结果:
没有了排序,运行时间进一步缩短。
代码规范
https://github.com/WallofWonder/InfectStatistic-main/blob/zyf/221701233/codestyle.md
心路历程与收获
第一次被要求按照较为完整的个人开发流程进行开发,还是有点没适应过来啊,一开始设计的时候脑子一片混乱,对如何完成这个作业,脑海里一下子冒出好多模糊的想法,冷静了好一阵子才逐渐有了头绪。在纸上写写画画,最终确定程序雏形,耗费的时间真的出乎意料的长。
不过,开始编码后我确实有了和以往不一样的感觉——对于代码基础结构的修改频率明显减少,能够更加专心于功能的实现和优化上,也能更多地萌生出一些对于业务逻辑的想法,编码时思路也不容易断掉,即使编码途中因为个人原因暂停了一段时间,再次打开编辑器还是能够回到状态。
(ps:不得不提的是,变量命名一直是我的硬伤,变量一多,我的命名困难症就会犯,不知不觉就会在命名上浪费时间。)
编码之外,占用我最多时间的就是各种文档的编写了,这对从小就不善文字表达的我来说挺吃力的,边写边想,不知不觉半天就没了,稿子也没什么进展,不过这也得练,不练没法提高,没办法,以后大概率得靠这个吃饭~
这个作业接近尾声了,我现在忽然有一种感觉,大一大二一门课一门课地学过来,可能自己现在才抬起一只脚,准备迈进软件工程的大门。《构建之法》谈到过:
年轻学生都志向远大,上了一些课,就想解决高层次问题。... 他们认为“我已经知道怎么做了”。
这就是刚进大学的我啊,刚学完C语言,意气风发,急着跑去acm,才发现自己步子迈大了,才知道做到“熟练”甚至“精通”一种技术不是学完基础考试过了就行的。一个领域的佼佼者是不会像初学者一样在“低层次问题上”消耗过多的精力的。
脚踏实地,打好基础,稳步爬升才是我应该做的。
5个仓库
Spring Boot 学习示例
https://github.com/ityouknow/spring-boot-examples
Spring Boot 使用的各种示例,以最简单、最实用为标准,此开源项目中的每个示例都以最小依赖,最简单为标准,帮助初学者快速掌握 Spring Boot 各组件的使用。
博客 vue+springboot
https://github.com/MQPearth/Blog
基于vue+springboot的前后端分离的博客,文档提供了完整的技术栈,方便初学者学习
Mall
https://github.com/macrozheng/mall
基于 SpringBoot+MyBatis 实现的一套电商系统,包括前台商城系统及后台管理系统。
微人事
微人事是一个前后端分离的人力资源管理系统,项目采用SpringBoot+Vue开发。
spring-boot-seckill
https://github.com/ZoeShaw101/spring-boot-seckill
SpringBoot开发案例,从0到1构建分布式高并发抢购系统,项目案例基本成型,逐步完善中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号