软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 作业连接 |
| 这个作业的目标 | 阅读《构建之法》并提问、学习使用git以及github、完成词频统计个人作业 |
| 作业正文 | 正文连接 |
| 其他参考文献 | 《码出高效_阿里巴巴Java开发手册》、《构建之法》 |
Part1:阅读《构建之法》并提问
Q1: 如何终止“分析麻痹”?
P52 3.2 分析麻痹:一种极端情况是想弄清楚所有细节、所有依赖关系之后再动手,心理上过于悲观,不想修复问题,出了问题都赖在相关问题上。分析太多,腿都麻了,没法起步前进,故得名“分析麻痹"( Analysis Paralysis )。
当出现一个问题的时候,我们当然会去分析导致这个问题出现的原因,而这个问题的出现也确实是存在着其他依赖问题,比如书中举的例子:木桶出现了洞需要粗绳堵,但是粗绳太长需要刀砍断······但是这些也都是真实存在,需要解决的问题。我的疑惑是,我们在分析问题的时候需要分析到哪一种程度停下来实施,才能避免“分析麻痹”?
Q2:软件工程师的职业生涯真的就会终止在35岁吗?
P55 3.3 软件工程师的职业发展 2. 工作(Job) 这些人经常会问“软件开发做到35岁以后怎么办”这样的问题。很多中国IT人士认为这个年龄是程序员的职业终点。
这个问题也是现在非常困扰我的一个职业规划方面的问题。在我上网查找的相关言论中,非常多的人都认为35岁就是一个程序员的终结,原因有很多,比如身体原因、脑力的退化以及有能力的新人的涌现等等。我的疑惑是,软件工程师的职业生涯真的就会终止在35岁吗?我们应该如何规划35岁以后的职业生涯?
Q3:用户体验和质量要怎么去权衡?
P269 12.1.6 用户体验和质量 好的用户体验当然是所有人都想要的,如果它和产品的质量有冲突,怎么办?牺牲质量去追求用户体验么,用户能接受么?
现在很多的软件都拥有数量相当多的用户,用户数量一多就会有各种各样的用户体验,有的人会觉得好,而有的人觉得不好,这样要怎么去定义“用户体验”呢?况且我认为质量不也是影响用户体验的一个因素吗?那么,在这种情况下,牺牲质量去追求用户的体验,导致了一部分用户觉得好,又有一部分觉得不好,那这样的改动还有必要吗?
Q4:怎么决定一个团队中各人负责那一功能?
P322 问题5 无明确责任的分工
当一个团队接手一个项目时,是让每个人选择自己感兴趣的部分去实现,还是根据每个人的特点去分配更好?怎样去平衡这样的分工呢?
Q5:便宜、好、快这三个愿望只能满足两个,怎么办?
P337 15.1.6 招数:砍掉功能 从团队开发的历史经验来看,如果类似的功能需要N个单位时间才能最终完成,那么我们没有理由相信新功能会花少于N个单位时间。我们再回顾一下功能/资源/时间的平衡图,我们水平不高的小团队只能满足三个愿望中的两个,你要哪两个?
又好又便宜的需要花时间等,又好又快的需要钱,又快又便宜的比较难用。如果让我来抉择的话,我首先会排除又快又便宜的,因为又快又便宜这个条件虽然看起来很诱人,但是做出来的东西难用,难用的东西会有人用吗?我的疑惑是,我们应该怎么在这三个愿望之间做出较好的权衡?
Part2:WordCount编程
本次作业相关链接
- 作业主仓库:PersonalProject-Java
- 我的主仓库:silicon-bond/PersonalProject-Java
- 代码规范制定链接 硅硅键的代码规范
一.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| • Estimate | • 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 1400 | 1295 |
| • Analysis | • 需求分析 (包括学习新技术) | 360 | 390 |
| • Design Spec | • 生成设计文档 | 50 | 70 |
| • Design Review | • 设计复审 | 30 | 25 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 60 | 60 |
| • Coding | • 具体编码 | 600 | 540 |
| • Code Review | • 代码复审 | 90 | 80 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 180 | 100 |
| Reporting | 报告 | 190 | 160 |
| • Test Repor | • 测试报告 | 40 | 60 |
| • Size Measurement | • 计算工作量 | 30 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 120 | 60 |
| 合计 | 1620 | 1475 |
二、解题思路描述
刚开始看到题目后,我得出的题目要求如下:
- 从命令行参数获得输入文件和输出文件;
- 从输入文件读取数据;
- 处理文件数据;
- 将处理结果写入输出文件。
其中处理文件数据又可以分为一下几个部分:
- 统计行数
- 统计字符数
- 统计单词数
- 统计最多的10个单词及其词频
在分析这些要求的过程中,我思考了以下四个问题:
- 文件读取采用什么方式?
我脑海中首先出现的处理方法是一行一行地读取输入文件,于是分析完需求后我上网查找了Java的文件处理方法,先决定使用BufferReader的readLine方法来读取输入文件。
- 怎么分割文件中的各个单词?
使用String的splite来分割各个单词。
- 单词的格式怎么检查?
我首先想到的是用for循环来逐个检查前四个字符是否符合要求。
- 单词的频数用什么来保存?
使用map这样使用键值对的集合类来保存。
三、代码规范制定链接
四、计算模块接口的设计与实现过程
代码主要包含9个函数:getLines(String filePath)、getCharacters(String filePath)、getWords(String filePath)、countWordFrequency(String inputFilePath, String outputFilePath)、judgeWords(String word)、sortByValue(TreeMap<String, Long> map, String filePath)、readToString(String fileName)、writeToFile(String content, String filePath)、closeOutputStream()。其中前四者承担了程序的主要功能,后三者承担了文件的输入输出功能。
1. 统计行数
在这一功能上,我首先将输入文件的全部内容读入,然后将各行以'\n'和'\r\n'作为分隔符,将非空白行计入有效行数:
public static long getLines(String filePath){
long lines = 0;
//一次读入全部内容
String fileString = readToString(filePath);
String[] lineStrings = fileString.split("\n|\r\n");
for (String lineString : lineStrings){
//判断改行是否非空
if (!lineString.trim().equals("")){
lines ++;
}
}
return lines;
}
2. 统计字符数
由于我采用一次性读入文件的文件读取方法,所以这一功能的实现简单一点:直接调用字符串的length方法来获取字符数:
public static long getCharacters(String filePath){
String fileString = readToString(filePath);
return fileString.length();
}
3. 统计单词数
分割单词时,先将文件内容按行分割,再使用Pattern类的splite方法进行行内分割:
public static long getWords(String filePath){
long words = 0;
Pattern pattern = Pattern.compile("[`~!@#$%^&*()_+\\-={}\\\\|:;\"'<,>.?/ \t\\[\\]]");
String fileString = readToString(filePath);
String[] lineStrings = fileString.split("\n|\r\n");
for (String lineString : lineStrings){
String[] wordStrings = pattern.split(lineString);
for (String word : wordStrings){
if (!word.equals("") && judgeWords(word.toLowerCase())){
words ++;
}
}
}
return words;
}
判断单词是否符合要求使用正则表达式:
private static boolean judgeWords(String word){
if (word.length() < 4){
return false;
}
Pattern pattern = Pattern.compile("^[a-z]{4}");
Matcher matcher = pattern.matcher(word);
if (!matcher.find()){
return false;
}
return true;
}
4. 统计最多的10个单词及其词频
这一部分使用了和统计单词数相同的分割单词的方法,使用哈希表来保存频数,如果单词未出现在哈希表中,则将单词加入;若单词已存在,则将单词的频数加一:
if (!word.equals("") && judgeWords(word)){
Long count = hashMap.get(word);
hashMap.put(word, (count == null ? 1 : ++ count));
}
先将哈希表转化成TreeMap进行按Key升序排序:TreeMap<String, Long> treeMap = new TreeMap<String, Long>(hashMap);,再按value降序排序:
List<Map.Entry<String,Long>> mappingList = null;
mappingList = new ArrayList<Map.Entry<String,Long>>(map.entrySet());
Collections.sort(mappingList, new Comparator<Map.Entry<String,Long>>(){
public int compare(Map.Entry<String,Long> mapping1,Map.Entry<String,Long> mapping2){
return mapping2.getValue().compareTo(mapping1.getValue());
}
});
五、计算模块接口部分的性能改进
1. 文件读写
最开始使用的是BufferReader的readLine方法,需要一行一行地去读取文件,频繁地IO操作,后来我改用一次性读入全部文件的方法,也简化了统计各项数据的过程
File file = new File(fileName);
Long filelength = file.length();
byte[] filecontent = new byte[filelength.intValue()];
FileInputStream in = new FileInputStream(file);
in.read(filecontent);
in.close();
2. 单词检查
最开始我想到的是用for循环来判断格式是否符合要求,但后来了解到可以使用Macher来检查:
Pattern pattern = Pattern.compile("^[a-z]{4}");
Matcher matcher = pattern.matcher(word);
六、计算模块部分单元测试展示
单元测试使用的两个输入文件:
input1.txt: 在四个段落中,各个单词间加入不同的相对多的分隔符,并改变单词的大小写、穿插空白行
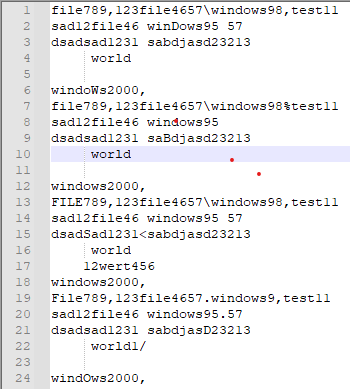
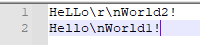
input2.txt
-
input1.txt测试
@Test public void wordCountTest1(){ String[] args = {"E:\\input1.txt", "E:\\output1.txt"}; long lines = Lib.getLines(args[0]); assertEquals(21, lines); long characters = Lib.getCharacters(args[0]); assertEquals(476, characters); long words = Lib.getWords(args[0]); assertEquals(32, words); Lib.countWordFrequency(args[0], args[1]); }
-
input2.txt测试
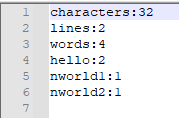
@Test public void wordCountTest2(){ String[] args = {"E:\\input2.txt", "E:\\output2.txt"}; long lines = Lib.getLines(args[0]); assertEquals(2, lines); long characters = Lib.getCharacters(args[0]); assertEquals(32, characters); long words = Lib.getWords(args[0]); assertEquals(4, words); Lib.countWordFrequency(args[0], args[1]); }
-
main函数测试
@Test public void mainTest(){ String[] args = {"E:\\input1.txt", "E:\\output1.txt"}; WordCount.main(args); }
-
单元测试覆盖率
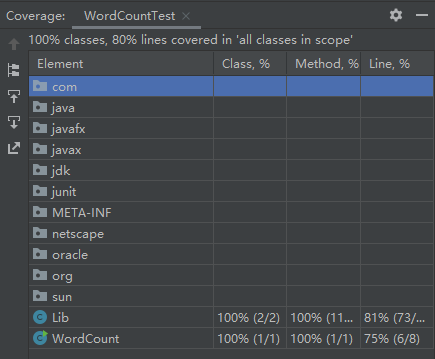
说明:未覆盖部分为异常处理部分
-
output1.txt 和 output2.txt
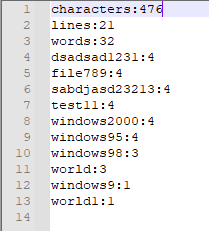
七、计算模块部分异常处理说明
异常处理主要体现在命令行参数与文件读写两方面
-
命令行参数数量不符合规定
if (args.length != 2){ System.out.println("命令行参数错误,需要两个文件名!"); System.exit(0); }
-
输入的文件不存在
try { FileInputStream in = new FileInputStream(file); in.read(filecontent); in.close(); } catch (FileNotFoundException e) { System.err.println("未找到文件:" + fileName); e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }
八、心路历程与收获
第一次看到这一次的作业的时候,我的心情是有一些崩溃的,因为作业的描述与要求太多,看的我眼花缭乱、头晕目眩,而且还要学习我之前从来没有使用过的Git和GitHub,让我觉得很慌张。
但是我放平心态后,仔细再看了一遍要求,发现任务的要求很清晰,再经过一番思考后,脑子中已经有了大致的想法。之后我先学习了Git和Github的使用,在学习Git的分支这一内容上也花了我大量的精力,但也通过一系列的练习大致掌握了分支的使用。
通过这一次的作业,我发现我在性能改进和单元测试这两方面存在很大的不足,不知道该从何下手,以后要多花精力在这两个方面上去学习。

