
个人项目-数独
项目地址
https://github.com/si1entic/sudoku
需求分析
- 生成终局
格式:sudoku.exe -c n
1)不重复
2)1<=n<=1000000,能处理非法参数
3)左上角数字固定为(4+4)% 9 + 1 = 9
4)n在1000以内时,要求程序在 60 s 内给出结果
5)输出生成的数独终盘至sudoku.txt - 求解数独
格式:sudoku.exe -s path
1)从指定文件读取,每读81个数字视作一道数独题,忽略其他字符
2)要求文件内的数独题目是合法的
3)文件内数独个数在1000以内时,要求程序在 60 s 内给出结果
4)输出已读入数独的答案至sudoku.txt。若存在未满81个的数字,在已解出的答案后输出“存在错误格式!”
解题思路
1.数独生成算法
首先想到的是暴力解决,第一行进行1~9的全排列,之后的行依次循坏填充数字再验证,不满足就回退。但这样有个明显的问题——效率极低。于是求助度娘,找到了一些算法,但要么效率不够,要么很难满足首数字固定的要求。最终,在《编程之美》P95里找到了比较适合的算法,加以改进就可以解决该题目了。
下面简单地一下该算法思路:首先将9x9的表格视作3x3的九宫格,随机生成正中的九宫格(称其为种子),再通过行列变化填满其他九宫格,得到了一个合法的数独终盘。下面来算算通过对这个终盘进行行列变换能得到多少个不同的终盘。
不难发现,在同一九宫格内进行行列变换(蓝框列或粉框行互换),所得新数独仍是合法的。再考虑到固定左上角数字的要求,我们不动第一行第一列,于是有2!×3!×3!×2!×3!×3!=5184种,这就是一个种子变换出的终盘个数。而种子有8!=40320个,显然不同种子经行列变换得到的终盘是不重复的,故该算法可生成5184×40320=209018880个不重复终盘,满足1000000的要求。
注:该算法由本人与室友 @李金奇 结合书中内容讨论所得,但可承诺代码实现均是各自独立完成。
2.求解数独算法
查到求解数独一般采取高效率的DLX算法,于是去这个博客了解了一下。算法原理比较容易理解,Dancing Links实际上是一种数据结构(交叉十字循环双向链)。由于解决精确覆盖问题的X算法中需要频繁用到移除、恢复操作,而在这种结构下,进行这两种操作的效率极高。
接下来就该考虑如何将数独求解问题转换为01精确覆盖问题了,这篇博客对我帮助很大。
行为状态,列为条件
- 9x9x9行(状态)
X行:表示数独i行j列填入数字k(根据X=81*i+9*j+k-1求出) - 1+9x9x4列 (条件)
第0列为Head元素所占
Y列:
当0<Y≤81,表示数独i行j列是否已填入数字(根据Y=9*i+j+1求出)
当81<Y≤81*2,表示数独i行是否已填入数字k(根据Y=81+9*i+k求出)
当81*2<Y≤81*3,表示数独j列是否已填入数字k(根据Y=81*2+9*j+k求出)
当81*3<Y≤81*4,表示数独b块是否已填入数字k(根据Y=81*3+9*b+k求出)
转化之后采用DLX算法就行了,关键步骤是深度优先遍历-移除-无法满足则恢复,详见下面的代码说明。
注:该算法参考上述博客较多,尤其是关于使用数组来构建交叉十字循环双向链的部分,但代码都是我自己实现的,从注释也看得出来。
设计实现
输入处理类:根据参数调用下列函数进行相应处理(包括参数合法性判断)
终盘生成类:种子生成函数、交换组合函数、行列交换函数、转换输出函数
数独求解类:读入转换函数、链接构建函数、结点插入函数、移除函数、恢复函数、深度优先遍历函数
输入处理类中,根据读取参数选择一个执行,调用终盘生成类或数独求解类完成相应功能,并负责输出到文件。
终盘生成类中,种子生成函数调用交换组合函数生成各种变换方式,再调用行列交换函数实现交换,最后通过转换输出函数返回字符串结果。
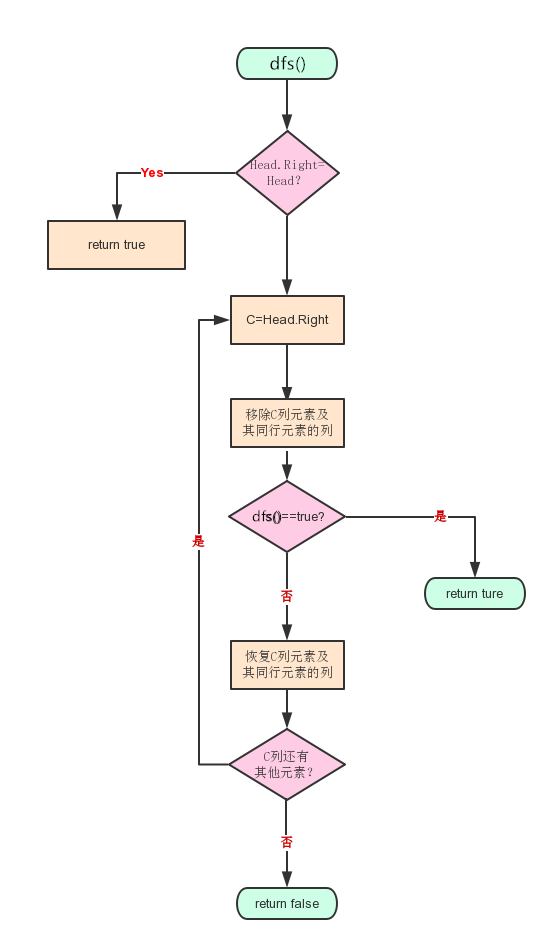
数独求解类中,先将字符串输入转化为二维整型数组,再构建交叉十字循环双向链,接着在dfs递归中进行移除、恢复操作,直到获取可行解。
DLX算法流程图如下
单元测试
TEST_METHOD(TestMethod1){
FianlMaker fm;
int a[9][9] = {
{ 9,8,7,6,5,4,3,2,1 },
{ 1,2,3,4,5,6,7,8,9 }};
fm.rowExchange(a, 0, 1);
for (int i = 0; i < 9; i++){
Assert::AreEqual(i+1, a[0][i]);
Assert::AreEqual(9-i, a[1][i]);
}
}
TEST_METHOD(TestMethod2){
FianlMaker fm;
int a[9][9] = {
{ 1,2,3,4,5,6,7,8,9 },
{ 1,2,3,4,5,6,7,8,9 },
{ 1,2,3,4,5,6,7,8,9 },
{ 1,2,3,4,5,6,7,8,9 },
{ 1,2,3,4,5,6,7,8,9 },
{ 1,2,3,4,5,6,7,8,9 },
{ 1,2,3,4,5,6,7,8,9 },
{ 1,2,3,4,5,6,7,8,9 },
{ 1,2,3,4,5,6,7,8,9 } };
fm.colExchange(a, 0, 1);
for (int i = 0; i < 9; i++){
Assert::AreEqual(2, a[i][0]);
Assert::AreEqual(1, a[i][1]);
}
}
覆盖率分析
可以看到两个功能函数的覆盖率都达到了100%(助教给的这个插件似乎无法对单元测试的覆盖率进行统计,只能统计EXE实际跑起来执行了哪些代码?)
优化改进
- 多次输出改为单次一起输出
- dfs中,发现优先移除元素最少的列,求解效率更高。(单次求解1.2s→0.3s)
str+=to_string(table[i][j])改为str+=char(table[i][j]+'0'),快了不少之前使用string保存所有的输出字符,性能分析发现string的+=操作占用了程序大部分时间,于是改为char数组保存,速度提高了很多(39s→8s)。- 将输出由ofstream的<<改为FILE*的fputs,速度略微提高。
- 之前使用swap标准函数来交换二维数组,改为自己用temp实现变快了。(6s→3s)
最终,生成100万个终盘,开启O2优化后的release编译性能分析图如下

消耗最大的函数是make,负责调用其它函数生成终盘。
解1000次芬兰数学家提出的“最难数独”
耗时
代码说明
void FianlMaker::make(int n) {
num = n;
count = 0;
int a[9] = { 1,2,3,4,5,6,7,8,9 };
while (1) {
table[0][4] = table[1][1] = table[2][7] = table[3][3] = table[4][0] = table[5][6] = table[6][5] = table[7][2] = table[8][8] = a[0];
table[0][5] = table[1][2] = table[2][8] = table[3][4] = table[4][1] = table[5][7] = table[6][3] = table[7][0] = table[8][6] = a[1];
table[0][3] = table[1][0] = table[2][6] = table[3][5] = table[4][2] = table[5][8] = table[6][4] = table[7][1] = table[8][7] = a[2];
table[0][7] = table[1][4] = table[2][1] = table[3][6] = table[4][3] = table[5][0] = table[6][8] = table[7][5] = table[8][2] = a[3];
table[0][8] = table[1][5] = table[2][2] = table[3][7] = table[4][4] = table[5][1] = table[6][6] = table[7][3] = table[8][0] = a[4];
table[0][6] = table[1][3] = table[2][0] = table[3][8] = table[4][5] = table[5][2] = table[6][7] = table[7][4] = table[8][1] = a[5];
table[0][1] = table[1][7] = table[2][4] = table[3][0] = table[4][6] = table[5][3] = table[6][2] = table[7][8] = table[8][5] = a[6];
table[0][2] = table[1][8] = table[2][5] = table[3][1] = table[4][7] = table[5][4] = table[6][0] = table[7][6] = table[8][3] = a[7];
table[0][0] = table[1][6] = table[2][3] = table[3][2] = table[4][8] = table[5][5] = table[6][1] = table[7][7] = table[8][4] = 9;
memcpy(temp, table, sizeof(table));
for (int c1 = 0; c1 < 2 ; c1++)
for (int c2 = 0; c2 < 6 ; c2++)
for (int c3 = 0; c3 < 6 ; c3++)
for (int r1 = 0; r1 < 2 ; r1++)
for (int r2 = 0; r2 < 6 ; r2++)
for (int r3 = 0; r3 < 6; r3++) {
combina(c1, c2, c3, r1, r2, r3);
if (count == num) {
ofstream out;
out.open("sudoku.txt", ios::out | ios::trunc); // 写入前先清空文件
out << str;
out.close();
return;
}
}
next_permutation(a, a + 8); // 按升序进行全排列一次,只排列前8个元素
}
}
这里生成种子时,采用了next_permutation这个标准库里的函数,其作用是将所给范围内的元素进行升序排列一次,能升序则改变数组并返回true,否则返回false。由于1000000的上限决定了不可能用完所有种子,所以无须判断。然和根据种子生成的终盘,进行行列变换。
void FianlMaker::combina(const int& c1, const int& c2, const int& c3, const int& r1, const int& r2, const int& r3) {
memcpy(table, temp, sizeof(temp));
if (c1 == 1)
colExchange(1, 2);
switch (c2) {
case 1:
colExchange(4, 5);
break;
case 2:
colExchange(3, 4);
break;
case 3:
colExchange(3, 4);
colExchange(4, 5);
break;
case 4:
colExchange(3, 5);
colExchange(4, 5);
break;
case 5:
colExchange(3, 5);
break;
}
...
tableToString();
}
这里根据6个参数选择行列变换,确定具体变换方式,然后将该终盘数组转化为字符串
const int maxrow = 9 * 9 * 9;
const int maxcol = 1 + 9 * 9 * 4;
const int num = maxcol + maxrow * 4; // 总元素个数, 第一个为Head元素,接着9*9*4个为列标元素,最后9*9*9*4个为“1”元素
int Left[num], Right[num], Up[num], Down[num]; // 每个元素的4个方向分量(相当于链表中的箭头)
int Col[num]; // 记录每个元素的列标元素
int Row[num]; // 记录每个元素所在的01矩阵行数
int Size[maxcol]; // 记录每列的“1”元素个数
int Head[maxrow]; // 记录每行第一个“1”元素
int table[9][9]; // 数独
int no; // 元素编号
DLX算法用到的交叉十字循环双向链,用数组来实现这一结构
void SudokuSolver::link() {
/* 链接列标元素 */
for (size_t i = 0; i < maxcol; i++) {
Left[i] = i - 1;
Right[i] = i + 1;
Up[i] = Down[i] = i;
Row[i] = 0;
Col[i] = i;
Size[i] = 0;
}
/* 链接Head元素 */
Left[0] = maxcol - 1;
Right[maxcol - 1] = 0;
no = maxcol;
/* 链接“1”元素 */
for (size_t i = 0; i < 9; i++) {
for (size_t j = 0; j < 9; j++) { // 遍历9x9数独
int k = table[i][j];
if (k) {
for (size_t t = 1; t <= 4; t++) { // 每个非0数字会在01矩阵中产生4个“1”元素
Left[no + t] = no + t - 1;
Right[no + t] = no + t + 1;
Row[no + t] = i * 81 + j * 9 + k - 1;
}
Left[no + 1] = no + 4;
Right[no + 4] = no + 1;
Head[Row[no + 1]] = no + 1;
/* 将4个元素插入列链中 */
insertNode(i * 9 + j + 1, no + 1);
insertNode(81 + i * 9 + k, no + 2);
insertNode(81 * 2 + j * 9 + k, no + 3);
insertNode(81 * 3 + (i / 3 * 3 + j / 3) * 9 + k, no + 4);
no += 4;
}
else { // 该位置为0,即待填
for (size_t k = 1; k <= 9; k++) { // 构造9种填法
for (size_t t = 1; t <= 4; t++) { // 生成并链接它们的元素
Left[no + t] = no + t - 1;
Right[no + t] = no + t + 1;
Row[no + t] = i * 81 + j * 9 + k - 1;
}
Left[no + 1] = no + 4;
Right[no + 4] = no + 1;
Head[Row[no + 1]] = no + 1;
insertNode(i * 9 + j + 1, no + 1);
insertNode(81 + i * 9 + k, no + 2);
insertNode(81 * 2 + j * 9 + k, no + 3);
insertNode(81 * 3 + (i / 3 * 3 + j / 3) * 9 + k, no + 4);
no += 4;
}
}
}
}
}
这是形成交叉十字循环双向链的函数,负责将1个Head元素+9*9*4个列标元素+9*9*9*4个“1”元素链接起来,即DLX算法中的DancingLink部分。
bool SudokuSolver::dfs(int select){
if (select > 81) // 已选够
return true;
/* 遍历列标元素,选一个元素最少的列(回溯率低) */
int c, minnum = INT_MAX;
for (size_t i = Right[0]; i != 0; i = Right[i]) {
if (Size[i] == 0)
return false;
if (Size[i] < minnum){
minnum = Size[i];
c = i;
}
}
remove(c);
/* 遍历该列各“1”元素 */
for (int i = Down[c]; i != c; i = Down[i]){
int row = Row[i];
table[row / 81][row % 81 / 9] = row % 9 + 1; // 根据该元素的行填入数独
for (size_t j = Right[i]; j != i; j = Right[j]) // 移除与该元素同行元素的列
remove(Col[j]);
if (dfs(select + 1)) // 已选行数+1,递归调用
return true;
for (size_t j = Left[i]; j != i; j = Left[j]) // 递归返回false,说明后续无法满足,故恢复与该元素同行元素的列,循坏进入本列下一元素
restore(Col[j]);
}
restore(c);
return false;
}
这是求解精确覆盖问题的X算法中的核心部分,即按深度优先遍历递归求解
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 500 | 600 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 500 |
| Reporting | 报告 | 10 | 20 |
| · Test Report | · 测试报告 | 30 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| Total | 总计 | 1090 | 1480 |
一些感想
草草估计了下,花在这个项目上的时间已经24h了(实际可能更多)。开学这第一周可以说也没干别的事,成天脑子里想的都是学C++、找算法、看教材、写博客、组队……写烦的时候会想“这真的是两学分的选修课?花的时间和计组差不多了!”又加上经历了前后加入的两个组 组长都带着半组人退课了这种事,有那么一刻真的想我也退了算了。理由可以找很多:我没有C++基础上来就写大项目太难了、编译+数据库+安卓 课业已经很重了……但其实心知肚明,都是想偷懒的借口。上这课只是为了学分吗?毕业想参加工作的我肯定不能只为混学分。课业虽重,但咬咬牙总能过去。That which does not kill us makes us stronger.
扯远了,说回这个项目。花了一下午找算法并看懂,花了一天完成初版。然后本来打算做附加题的,但这几天的时间都花在性能优化上了,再加上一直没怎么写过GUI也不熟悉Qt,就不了了之。 优化的结果还是比较满意的,从初版的一分多钟到现在的1.5秒,其中走了很多绕路。举个例子,之前因为方便都是用string的+=拼接字符串,可没想到比直接操作char*慢这么多。(在此之前,还查了+=、append、stringstream、sprintf的效率比较)类似的还有各种文件IO的处理。也仍有一些不懂的地方,比如VS的编译优化是怎样做到的?还有调试时出现的一些link错误也没真正弄懂背后的原理。以前写代码时几乎没怎么想效率问题,现在算是有些明白老师讲的“软工作业写个只存了五六本书的图书管理系统有什么用”了。
虽然现在想想后面的结对、团队项目仍有点头皮发麻,但也明白“轻轻松松就完成的作业相当于没做”。路在前方,唯行而已。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号