vi/vim正则表达式
http://www.cnblogs.com/penseur/archive/2011/02/25/1964522.html
毋庸多言,在vim中正则表达式得到了十分广泛的应用。 最常用的 / 和 :s 命令中,正则表达式都是不可或缺的。 下面对vim中的正则表达式的一些难点进行说明。
关于magic
vim中有个magic的设定。设定方法为:
:set magic " 设置magic :set nomagic " 取消magic :h magic " 查看帮助
vim毕竟是个编辑器,正则表达式中包含的大量元字符如果原封不动地引用(像perl 那样), 势必会给不懂正则表达式的人造成麻烦,比如 /foo(1) 命令, 大多数人都用它来查找foo(1)这个字符串, 但如果按照正则表达式来解释,被查找的对象就成了 foo1 了。
于是,vim就规定,正则表达式的元字符必须用反斜杠进行转义才行, 如上面的例子,如果确实要用正则表达式,就应当写成 /foo\(1\) 。 但是,像 . * 这种极其常用的元字符,都加上反斜杠就太麻烦了。 而且,众口难调,有些人喜欢用正则表达式,有些人不喜欢用……
为了解决这个问题,vim设置了 magic 这个东西。简单地说, magic就是设置哪些元字符要加反斜杠哪些不用加的。 简单来说:
magic (\m):除了 $ . * ^ 之外其他元字符都要加反斜杠。
nomagic (\M):除了 $ ^ 之外其他元字符都要加反斜杠。
这个设置也可以在正则表达式中通过 \m \M 开关临时切换。 \m 后面的正则表达式会按照 magic 处理,\M 后面的正则表达式按照 nomagic 处理, 而忽略实际的magic设置。
例如:
/\m.* # 查找任意字符串
/\M.* # 查找字符串 ".*"
另外还有更强大的 \v 和 \V。
\v (即 very magic 之意):任何元字符都不用加反斜杠
\V (即 very nomagic 之意):任何元字符都必须加反斜杠
例如:
/\v(a.c){3}$ # 查找行尾的abcaccadc
/\m(a.c){3}$ # 查找行尾的(abc){3}
/\M(a.c){3}$ # 查找行尾的(a.c){3}
/\V(a.c){3}$ # 查找任意位置的(a.c){3}$
|
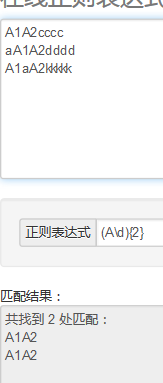
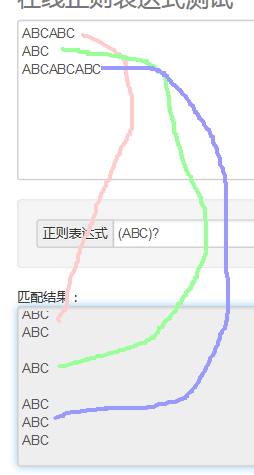
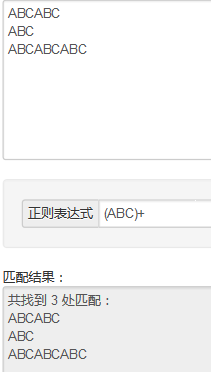
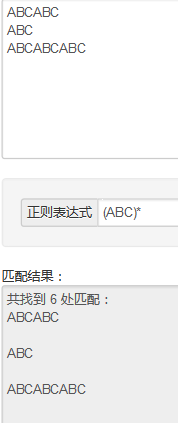
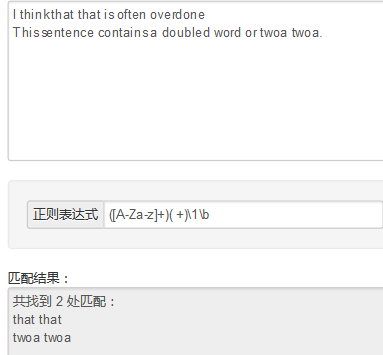
正则表达式的()和[]的用法: http://blog.csdn.net/hanjieson/article/details/8885206 http://www.cnblogs.com/snandy/p/3650309.html 1.(A\d){2}----> (ABC)?---->0个或者1个ABC-----> (ABC)+---->1个以上ABC--------> (ABC)*----->0个或者多个ABC---------> -------------------------------------------------- 2.(ABC|123)----> ************************************** 2.1gr(a|e)y---->匹配gray或者grey --->等价于gr[ae]y 2.2(Doctor|Dr\.?)--->匹配Doctor Dr Dr.----->?表示0个或者1个; ps (Doctor|Dr.?)这个也可以匹配Doctor Dr Dr. 不同明白\在这里的意义.. ------------------------------------------------------------------------ 3.错误匹配的交替行为:使用交替行为时,有时会出现意想不到的错误 用(a|ab)匹配ab时,只能匹配a 用(ab|a)则可以匹配ab-------------> -------------------------------------------------------------------------- 4.捕获圆括号:正则表达式中,与位于圆括号之间的模式匹配的内容都会被捕获 **************************************************** 4.1当模式中有嵌套的圆括号时,变量的编号会按照圆开括号出现的位置一次进行 ([A-Za-z](\d{2}))((-)\d{2})----->匹配A22-33时匹配情况如下: group1:A22 group2:22 group3:-33 group4:- ------------------------------------------------------------------------- 5..NET和JavaScript中,表示匹配第一组的变量被指定为”\1”
ps +表示"一个以上" ?表示"0个或者1个" *表示"o个或者多个"
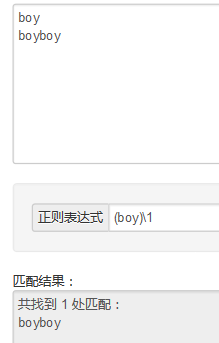
(boy)\1------> ps:(boy)是一个"boy" \1是一个"boy" 所以只能匹配boyboy
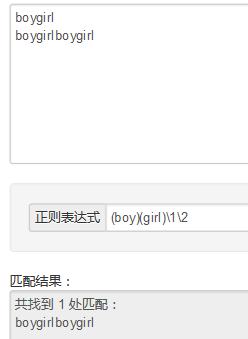
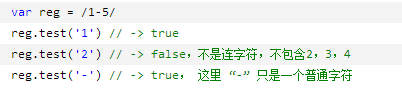
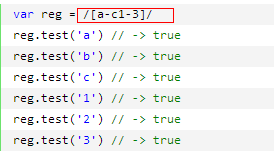
(boy)(girl)\1\2-----> ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ http://www.cnblogs.com/snandy/p/3662423.html 接下来是[]的学习 (以c#的语法进行说明--->其他语法虽然不同但是正则的规则是相同的) 1.简单字符组  ---------------------------------------------------------------------------------- 2.范围字符组(Range class,与连字符 “-” 一起使用) 如果要匹配0-9可以写成 [0123456789],但有了范围字符组更简洁了,可以写成 /[0-9]/
匹配小写英文字母可以用字符组 [a-z], 匹配大写英文字母用 [A-Z]。 这里最关键的是连字符 "-",不要理解为减号。 它的意义是“从什么到什么”,如[a-z]理解为从 “a” 到 “z”。 需要注意几点 1. 连字符(-)只在字符组内(中括号)才是元字符。如 2. 甚至在字符组内部,它也不一定是元字符。如 此外,很多元字符在字符组内都变成了普通字符,如(^$?)等。 3. 范围不能乱写,比如只能 [0-9],不能[9-0]. 范围字符组实际是安装字符对于的ASCII码值来确定的,值小的在前面,值大的在后面。例如[0-9]的码值为48~57,[a-z]的码值为97~122,[A-Z]的码值为65~90。
4.组合字符组 ->由多种字符组组合一起的字符组->需要注意的是,字符组内不要有空格,有人喜欢在f和1之间加个空格,以便阅读起来舒服一些,但这是不允许的
------------------------------------------------------------------------------------------------------------------------------------------ 3.排除型字符组(Negated character class,与脱字符 “^” 一起使用)--->即不匹配xxx
------------------------------------------------------------------------------------------------------------ 4.字符组运算(方括号嵌套+运算符) 有些语言支持,比如&&+[] Java中就支持,但JavaScript不支持
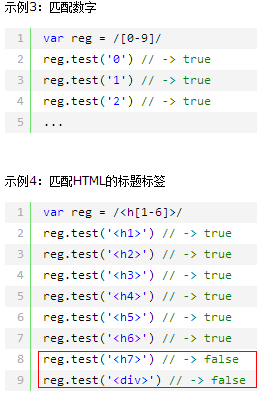
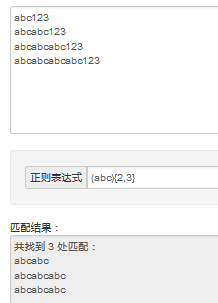
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ http://www.jb51.net/article/52594.htm \s--->空格 \s{3}---->匹配3个空格 \s[1,3]---->匹配 1个空格 or 2个空格 or 3个空格 (0-9)---->匹配'0-9' [0-9]{1,3} VS [0-9]{1,4} VS [0-9]{1,2} 这个到底怎么用啊....没看明白语法 (a){1,3} VS (a){1,4} VS (a){1,2} 这个到底怎么用啊....没看明白语法
1{n}重复n次 1{m,n}最小重复m次,最多重复n次----------------------------> 1{m,} 最小重复m次---------------------------->
感谢各位帖子的博主. |




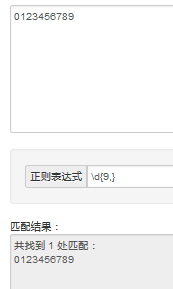 -->字符串0-9重复数字10次所以\d{9,}是可以把这个字符串匹配出来的.
-->字符串0-9重复数字10次所以\d{9,}是可以把这个字符串匹配出来的.
默认设置是 magic,vim也推荐大家都使用magic的设置,在有特殊需要时,直接通过 \v\m\M\V 即可。
本文下面使用的元字符都是 magic 模式下的。
量词
vim的量词与perl相比一点也不逊色。 vim的量词和perl的量词的对照表
| vim | Perl | 意义 |
| * | * | 0个或多个(匹配优先) |
| \+ | + | 1个或多个(匹配优先) |
| \? 或 \= | ? | 0个或1个(匹配优先),\?不能在 ? 命令(逆向查找)中使用 |
| \{n,m} | {n,m} | n个到m个(匹配优先) |
| \{n,} | {n,} | 最少n个(匹配优先) |
| \{,m} | {,m} | 最多m个(匹配优先) |
| \{n} | {n} | 恰好n个 |
| \{-n,m} | {n,m}? | n个到m个(忽略优先) |
| \{-} | *? | 0个或多个(忽略优先) |
| \{-1,} | +? | 1个或多个(忽略优先) |
| \{-,1} | ?? | 0个或1个(忽略优先) |
环视和固化分组
vim居然还支持环视和固化分组的功能,强大,赞一个 关于环视的解释请参考Yurii的《精通正则表达式》 一书吧。
| vim | Perl | 意义 |
| \@= | (?= | 顺序环视 |
| \@! | (?! | 顺序否定环视 |
| \@<= | (?<= | 逆序环视 |
| \@<! | (?<! | 逆序否定环视 |
| \@> | (?> | 固化分组 |
| \%(atom\) | (?: | 非捕获型括号 |
和perl稍有不同的是,vim中的环视和固化分组的模式的位置与perl不同。 例如,查找紧跟在 foo 之后的 bar,perl将模式写在环视的括号内, 而vim将模式写在环视的元字符之前。
# Perl的写法 /(?<=foo)bar/
# vim的写法 /\(foo\)\@<=barvim正则表达式 写道
元字符 说明
. 匹配任意一个字符
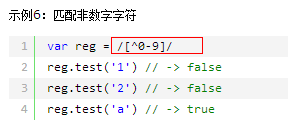
[abc] 匹配方括号中的任意一个字符。可以使用-表示字符范围,如[a-z0-9]匹配小写字母和阿拉伯数字。[^abc] 在方括号内开头使用^符号,表示匹配除方括号中字符之外的任意字符。
\d 匹配阿拉伯数字,等同于[0-9]。
\D 匹配阿拉伯数字之外的任意字符,等同于[^0-9]。
\x 匹配十六进制数字,等同于[0-9A-Fa-f]。
\X 匹配十六进制数字,等同于[^0-9A-Fa-f]。
\w 匹配单词字母,等同于[0-9A-Za-z_]。
\W 匹配单词字母之外的任意字符,等同于[^0-9A-Za-z_]。
\t 匹配<TAB>字符。
\s 匹配空白字符,等同于[ \t]。
\S 匹配非空白字符,等同于[^ \t]。
\a 所有的字母字符. 等同于[a-zA-Z]
\l 小写字母 [a-z]
\L 非小写字母 [^a-z]
\u 大写字母 [A-Z]
\U 非大写字母 [^A-Z]
表示数量的元字符
元字符 说明
* 匹配0-任意个
\+ 匹配1-任意个 注意 前面的\
\? 匹配0-1个 注意 前面的\
\{n,m} 匹配n-m个 注意 前面的\
\{n} 匹配n个 注意 前面的\
\{n,} 匹配n-任意个 注意 前面的\
\{,m} 匹配0-m个 注意 前面的\
\_. 匹配包含换行在内的所有字符
\{-} 表示前一个字符可出现零次或多次,但在整个正则表达式可以匹配成功的前提下,匹配的字符数越少越好
\= 匹配一个可有可无的项
\_s 匹配空格或断行
\_[]
元字符 说明
\* 匹配 * 字符。
\. 匹配 . 字符。
\/ 匹配 / 字符。
\\ 匹配 \ 字符。
\[ 匹配 [ 字符。
表示位置的符号
元字符 说明
$ 匹配行尾
^ 匹配行首
\< 匹配单词词首
\> 匹配单词词尾
替换变量
在正规表达式中使用 \( 和 \) 符号括起正规表达式,即可在后面使用\1、\2等变量来访问 \( 和 \) 中的内容。
懒惰模式
\{-n,m} 与\{n,m}一样,尽可能少次数地重复
\{-} 匹配它前面的项一次或0次, 尽可能地少
\| "或"操作符
\& 并列
函数式
:s/替换字符串/\=函数式
在函数式中可以使用 submatch(1)、submatch(2) 等来引用 \1、\2 等的内容,而submatch(0)可以引用匹配的整个内容。
与Perl正则表达式的区别 ?
元字符的区别
Vim语法 Perl语法 含义
\+ + 1-任意个
\? ? 0-1个
\{n,m} {n,m} n-m个
\(和\) (和) 分组
例如:
1,
去掉所有的行尾空格:“:%s/\s\+$//”。“%”表示在整个文件范围内进行替换,“\s”表示空白字符(空格和制表符),“\+”对前面的字符匹
配一次或多次(越多越好),“___FCKpd___0rdquo;匹配行尾(使用“\___FCKpd___0rdquo;表示单纯的
“___FCKpd___0rdquo;字符);被替换的内容为空;由于一行最多只需替换一次,不需要特殊标志。这个还是比较简单
的。(/<Space><Tab>)
2,去掉所有的空白行:“:%s/\(\s*\n\)\+/\r/”。这回多了“
\(”、“\)”、“\n”、“\r”和
“*”。“*”代表对前面的字符(此处为“\s”)匹配零次或多次(越多越好;使用“\*”表示单纯的“*”字符),“\n”代表换行符,“\r”代表回
车符,“\(”和“\)”对表达式进行分组,使其被视作一个不可分割的整体。因此,这个表达式的完整意义是,把连续的换行符(包含换行符前面可能有的连续
空白字符)替换成为一个单个的换行符。唯一很特殊的地方是,在模式中使用的是“\n”,而被替换的内容中却不能使用“\n”,而只能使用“\r”。原因是
历史造成的,详情如果有兴趣的话可以查看“:help NL-used-for-Nul”。
3,去掉所有的“//”注释:“:%s!\
s*//.*!!”。首先可以注意到,这儿分隔符改用了“!”,原因是在模式或字符串部分使用了“/”字符,不换用其他分隔符的话就得在每次使用“/”字
符本身时写成“\/”,上面的命令得写成“:%s/\s*\/\/.*//”,可读性较低。命令本身倒是相当简单,用过正则表达式的人估计都知道“.”匹
配表示除换行符之外的任何字符吧。
4,去掉所有的“/* */”注释:“:%s!\s*/\*\_.\{-}\*/\s*!
!g”。这个略有点复杂了,用到了几个不太常用的 Vim
正则表达式特性。“\_.”匹配包含换行在内的所有字符;“\{-}”表示前一个字符可出现零次或多次,但在整个正则表达式可以匹配成功的前提下,匹配的
字符数越少越好;标志“g”表示一行里可以匹配和替换多次。替换的结果是个空格的目的是保证像“int/* space not necessary
around comments */main()”这样的表达式在替换之后仍然是合法的。
:g/^\s*$/d 删除只有空白的行
:s/\(\w\+\)\s\+\(\w\+\)/\2\t\1 将 data1 data2 修改为 data2 data1
:%s/\(\w\+\), \(\w\+\)/\2 \1/ 将 Doe, John 修改为 John Doe
:%s/\<id\>/\=line(".") 将各行的 id 字符串替换为行号
:%s/\(^\<\w\+\>\)/\=(line(".")-10) .".". submatch(1) 将每行开头的单词替换为(行号-10).单词的格式,如第11行的word替换成1. word
排序 :/OB/+1,$!sort
http://www.cnblogs.com/PegasusWang/p/3153300.html
:s/\<four\>/4/g " 将所有的four替换成4,但是fourteen中的four不替换
/\(a\+\)[^a]\+\1 " 查找开头和结尾处a的个数相同的字符串," 如 aabbbaa,aaacccaaa,但是不匹配 abbbaa

 浙公网安备 33010602011771号
浙公网安备 33010602011771号