c++ union学习
看到公司前辈的代码中用到了union,不管是大学还是工作用到union机会比较少,还是挺新奇的.所以特意找些资料学习学习
前辈的代码:
1 #include<iostream> 2 using namespace std; 3 4 typedef unsigned int UINT32; 5 typedef unsigned char UINT8; 6 typedef unsigned short UINT16; 7 8 union date 9 { 10 UINT32 value; 11 struct 12 { 13 UINT8 day; 14 UINT8 month; 15 UINT16 year; 16 }; 17 }__attribute__((packed)); 18 int main(int argc, char** argv) 19 { 20 date myDate; 21 myDate.day = 02; 22 myDate.month = 10; 23 myDate.year = 2014; 24 cout<<hex<<myDate.value<<dec<<endl; 25 return 0; 26 } 27 //输出结果 0x7de0a02--->02对应day 0a对应month 7de对应2014 (计算过程 16*16*7+16*13+14)
下面是找的学习帖子: http://blog.sina.com.cn/s/blog_660234cf0100wsgs.html
union主要是共享内存,分配内存以其最大的结构或对象为大小,即sizeof最大的。在C/C++程序的编写中,当多个基本数据类型或复合数据结构要占用同一片内存时,我们要使用联合体;当多种类型,多个对象,多个事物只取其一时(我们姑且通俗地称其为“n 选1”),我们也可以使用联合体来发挥其长处。
1 union myun 2 { 3 struct { int x; int y; int z; }u; 4 int k; 5 }a; 6 int main() 7 { 8 a.u.x =4; 9 a.u.y =5; 10 a.u.z =6; 11 a.k = 0; 12 printf("%d %d %d\n",a.u.x,a.u.y,a.u.z); //0 5 6 13 return 0; 14 }
myun这个结构就包含u这个结构体,而大小也等于u这个结构体 的大小,在内存中的排列为声明的顺序x,y,z从低到高,然后赋值的时候,在内存中,就是x的位置放置4,y的位置放置5,z的位置放置6,现在对k赋 值,对k的赋值因为是union,要共享内存,所以从union的首地址开始放置,首地址开始的位置其实是x的位置,这样原来内存中x的位置就被k所赋的 值代替了,就变为0了
试题一:编写一段程序判断系统中的CPU 是Little endian 还是Big endian 模式?
分析:
Little endian 和Big endian 是CPU 存放数据的两种不同顺序。对于整型、长整型等数据类型,Big endian 认为第一个字节是最高位字节(按照从低地址到高地址的顺序存放数据的高位字节到低位字节);而Little endian 则相反,它认为第一个字节是最低位字节(按照从低地址到高地址的顺序存放数据的低位字节到高位字节)。
--------------------------------------------------------------------------------------
例如
------------------------------------------------------------------------------------------------
一般来说,x86 系列CPU 都是little-endian 的字节序,PowerPC 通常是Big endian,还有的CPU 能通过跳线来设置CPU 工作于Little endian 还是Big endian 模式。
解答:
显然,解答这个问题的方法只能是将一个字节(CHAR/BYTE 类型)的数据和一个整型数据存放于同样的内存开始地址,通过读取整型数据,分析CHAR/BYTE 数据在整型数据的高位还是低位来判断CPU 工作于Littleendian 还是Big endian 模式。得出如下的答案:
int main(int argc, char** argv)
{
int i = 0x12345678;
char* p = reinterpret_cast<char*>(&i);
cout<<hex<<static_cast<int>(*p)<<endl;
return 0;
} //如果输出是78就是小段 如果输出是34就是大端
除了上述方法(通过指针类型强制转换并对整型数据首字节赋值,判断该赋值赋给了高位还是低位)外,还有没
有更好的办法呢?我们知道,union 的成员本身就被存放在相同的内存空间(共享内存,正是union 发挥作用、做贡献的去处),因此,我们可以将一个CHAR/BYTE 数据和一个整型数据同时作为一个union 的成员,得出
如下答案:
1 int checkCPU() 2 { 3 { 4 union w 5 { 6 int a; 7 char b; 8 } c; 9 c.a = 1; 10 return (c.b == 1); //小端的话 c.b == 1 否则c.b == 0 11 } 12 }
实现同样的功能,我们来看看Linux 操作系统中相关的源代码是怎么做的:
1 static union 2 { 3 char c[4]; 4 unsigned long mylong; 5 } endian_test = {{ 'l', '?', '?', 'b' } }; 6 7 #define ENDIANNESS ((char)endian_test.mylong)
Linux 的内核作者们仅仅用一个union 变量和一个简单的宏定义就实现了一大段代码同样的功能!由以上一段代码我们可以深刻领会到Linux 源代码的精妙之处!(如果ENDIANNESS=’1’表示系统为little endian,为’b’表示big endian )
-------------------------
试题二:假设网络节点A 和网络节点B 中的通信协议涉及四类报文,报文格式为“报文类型字段+报文内容的结构体”,四个报文内容的结构体类型分别为STRUCTTYPE1~ STRUCTTYPE4,请编写程序以最简单的方式组织一个统一的报文数据结构。
分析:
报文的格式为“报文类型+报文内容的结构体”,在真实的通信中,每次只能发四类报文中的一种,我们可以将四类报文的结构体组织为一个union(共享一段内存,但每次有效的只是一种),然后和报文类型字段统一组织成一个报文数据结构。
解答:
根据上述分析,我们很自然地得出如下答案:
1 typedef unsigned char BYTE; 2 //报文内容联合体 3 typedef union tagPacketContent 4 { 5 STRUCTTYPE1 pkt1; 6 STRUCTTYPE2 pkt2; 7 STRUCTTYPE3 pkt1; 8 STRUCTTYPE4 pkt2; 9 }PacketContent;
//统一的报文数据结构
1 typedef struct tagPacket 2 { 3 BYTE pktType; 4 PacketContent pktContent; 5 }Packet;
--------------------------------------------------------------------
继续学习
http://baike.so.com/doc/200726-212218.html
http://blog.csdn.net/lincyang/article/details/6176642
首先是union的大小问题
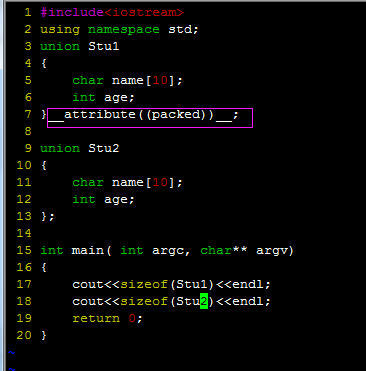
 可以看出来union也使用类似struct的内存大小分配方式.
可以看出来union也使用类似struct的内存大小分配方式.
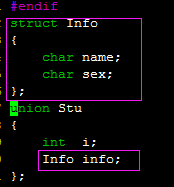
对应union Stu2来说 最大是10 但是最小单位是4 所以会扩展成4*3=12.
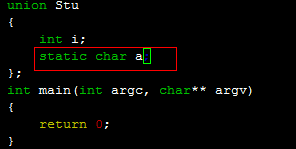
union结构体对成员变量的要求:
union的成员不可以为静态、引用[理由是联合里面的东西是共享内存的,而静态和引用不可能共享内存],如果是自订型态的话,该自订型态成员不可以有建构函式、解构函式或是复制指定运算子。
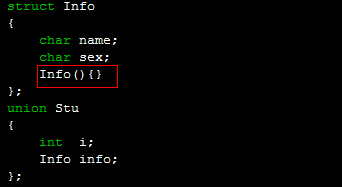
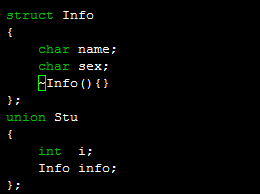
以下就是错误的形式[理由是带有构造函数、析够函数、复制拷贝操作符等的类他们共享内存,编译器无法保证这些对象不被破坏,也无法保证离开时调用析够函数。]
 |
 |
 |
 |
 |
当然.如果你不主动提供构造函数,而使用类或者结构体默认的构造函数是可以的.
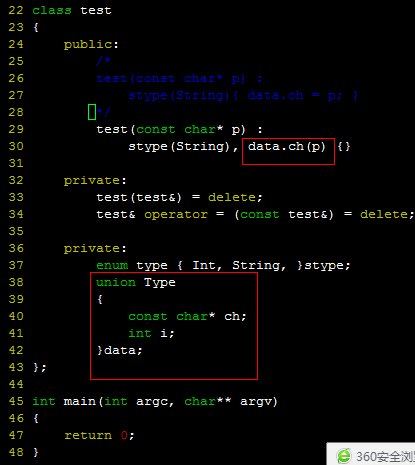
在class中定义union对象
| 错误代码 | 正确代码 | 原因分析 |
 |
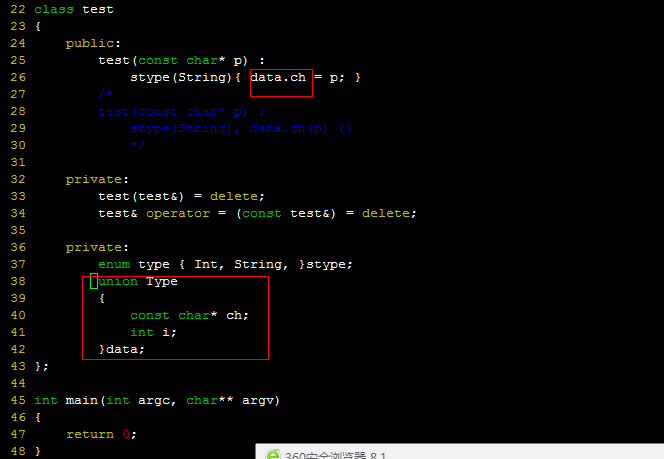 |
错误代码之所以错误是因为在构造函数的 初始化列表的时候 根本就还没有data对象 有何谈data的成员变量ch呢 |
如何有效的防止union的访问错误
使用联合可以节省内存空间,但是也有一定的风险:通过一个不适当的数据成员获取当前对象的值!例如上面的ch、i交错访问。
为了防止这样的错误,我们必须定义一个额外的对象,来跟踪当前被存储在联合中的值得类型,我们称这个额外的对象为:union的判别式(例如上例中的enum type)。
一个比较好的经验是,在处理作为类成员的union对象时,为所有union数据类型提供一组访问函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号