【讲●解】KMP算法
术语与规定#
为了待会方便,所以不得不做一些看起来很拖沓的术语,但这些规定能让我们更好地理解甚至自动机。
字符串匹配形式化定义如下:
假设文本是一个长度为的数组,而模式是一个长度为的数组,其中,进一步假设构成和的元素都是来自一个有限字母集的字符。例如:{}或者{}。字符数组通常称为字符串。
我们用表示所有有限长度字符串的集合,该字符串由字母表中的字符组成。特别地,长度为的空字符用表示,也属于。一个字符串的长度用表示。两个字符串和的连结用来表示,长度为,由的字符串后接的字符串构成。
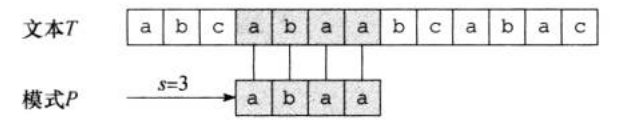
如果,并且(即如果,其中),那么称模式在文本中出现,且偏移为。如果在中以偏移存在,那么称是有效偏移;否则,称它为无效偏移。如图一,就是一个有效位移。根据此约定,字符串匹配问题就可以变成:对于模式串找出所有文本串的有效偏移。
如果对于某个字符串有,则称字符串是字符串的前缀,记作。类似的,我们也可以定义后缀符号:若,则称字符串是字符串的后缀,记作。可以看出:如果,则。特别地,空字符串同时是任何一个字符串的前缀和后缀。
(想一想我们为什么要引入和符号。)
如果不做特殊说明,我们约定认为为一个字符,即长度为的字符串。
为了使符号简洁,我们把模式的由前个字符组成的前缀记作,,采用这种记号,我们又能够把字符串匹配问题表述成:
找到所有偏移,使得。
首先,我们考虑朴素算法的操作过程#
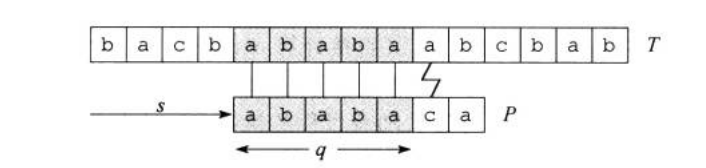
图一展示了一个针对文本串模式串的的一个特定位移。它已经匹配到了,在的位置与文本串失配。
按照朴素算法的操作,我们这时应进行的操作,把文本串的匹配指针左移到位,模式串匹配指针移回位,从头开始匹配。可这样时间开销是个很大的问题。
那怎么办呢?
我们能不能不把文本串的指针向左移,而直接把模式串的匹配指针对准下一个可能的匹配位置上,即只移动模式串呢?
答案是可以的。
别忘了我们已经匹配好了,这意味着我们已经知道了,如果能把这东西给利用起来那该多好啊!
怎么用呢?
于是,算法就来了。
KMP主体#
还是用图二。
个字符已经匹配成功的信息确定了相应的文本字符。已知的这个文本字符使我们能够立即确认某些偏移一定是无效的。就比如上面所说的。
KMP算法思想便是利用已经匹配上的字符信息,使得模式串的指针回退的字符位置能将主串与模式串已经匹配上的字符结构重新对齐。
什么意思?
假设我们存在这样一个映射函数,先把它理解成一个小黑盒。当我们在模式串的位置上失配时,它能跳到串的某一位置(注意是串),即使得与先前已匹配的个字符的文本串不发生冲突,然后再比较的位置是否与当前文本串指针匹配,如果不能,那继续找;如果能,那就成功匹配一位,进行下一位的匹配。这样,文本串的指针只会向右移而不会向左移。那么这个匹配程序就很好实现了。
这里直接给出伪代码:
KMP-MATCHER(T,P)
n = T.length
m = P.length
next = COMPUTE-PREFIX-FUNCTION(P)//这里的next就是那个小黑盒
q = 0
for i=1 to n
while q>0 and P[q+1]!=T[i]
q = next[q]
if P[q+1] == T[i]
q = q+1
if q == m
print "Pattern occurs with shift" i-m
q = next[q]//匹配成功后肯定要往回走啊
这就是算法的主体!
(仔细回味下)
那我们怎么求这个呢?
我们来观察它的性质。
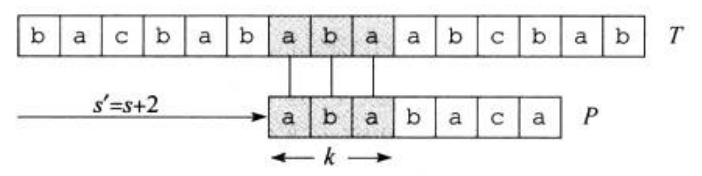
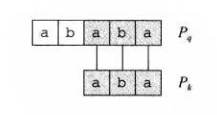
如图三,根据个字符已经完全匹配,那么图中的,且是满足此条件的最大值,我们直接可以从开始与文本串匹配。也就是说,这里的就是我们要找的。
在图四中,我们把和单独拿了出来,你发现了什么?
!
可以看出是满足条件的最大值,也就是说:
为什么会是这样呢?
我们想要直接在位开始匹配,就得保证,虽然我们在位失配,但我们已经知道了,所以即有。
那为什么我们会要求为满足条件的最大值呢?
这里先简单理解,为最大值也就包含了为更小值的情况。
那么,这个我们就把它视为的前缀函数。
那么,怎么来求这个呢?
首先,我们肯定能想到一种朴素算法,这里就不细说了,因为用朴素算法还不如敲个的匹配算法呢。。。
那我们怎么来优化求法呢?
同样假设,对于一个模式串,我们已经知道了,现在,我们来计算。其中,。
引理1:当时,可得。(前缀函数延续性引理)#
证明:
因为: 即 。
若字符,则。
所以:。
证毕。
引理2:若的最大候选项为,即,则它的次大候选项为,次次大为......(前缀函数迭代引理)#
证明:(反证法)
若存在使得且。
因为:,即。
又因为:。
所以:。
即:。
这与矛盾。
所以假设不成立。
证毕。
后面的依次类推。
由前两个引理可以看出,可能的候选项为:,......而易知,。
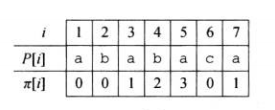
于是,我们便可以高效计算数组。
COMPUTE-PREFIX-FUNCTION(P)
m = P.length
pi[1] = 0
k = 0
for q=2 to m
while k>0 and P[k+1]!=P[q]
k = pi[k]
if P[k+1] == P[q]
k = k+1
pi[q] = k
是不是和KMP-MATCHER很像?
其实,实质上,KMP算法求前缀函数的过程就是模式串的自我匹配。
为什么我们先说算法的主体再谈的计算?其实这是从两种角度出发认识。讲解主体的时候我们采用了假设法,这是一种十分感性的认知,比较好懂。在讲解的计算时,我们引用了一些数学思维来帮助我们更加理解。大家可以看出,实质上,主体和的计算是几乎一样的逻辑。
至此,算法原理的讲解到此结束。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 没有源码,如何修改代码逻辑?
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战